日志 Pipelines¶
在观测云的日志管理中,可以通过 Pipelines 对日志的文本内容进行切割,将格式各异的日志切割成符合我们要求的结构化数据,如日志的时间戳、日志的状态、以及提取出特定的字段作为标签等。
前提条件¶
- 安装 DataKit;
- DataKit 版本要求 >= 1.5.0。
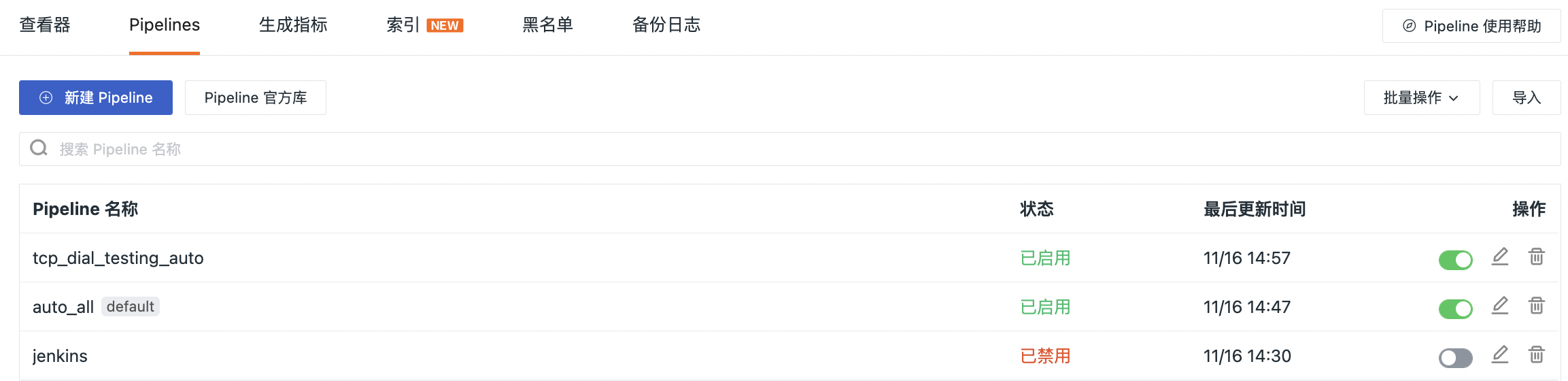
新建 Pipeline¶
在观测云工作空间日志 > Pipelines,点击新建 Pipeline,选择过滤日志,填入定义解析规则,然后在日志样本测试输入日志数据进行测试,测试通过后点击保存即可创建一个新的 Pipeline 文件。支持配置默认 Pipeline,并且在新建 Pipeline 时支持选择多个 source。
注意:Pipeline 文件创建以后,需要安装 DataKit 才会生效,DataKit 会定时从工作空间获取配置的 Pipeline 文件,默认时间为 1分钟,可在 conf.d/datakit.conf 中修改。
- 过滤日志:支持多选日志来源;
- 名称:输入自定义的 Pipeline 文件名;
- 定义解析规则:定义日志的解析规则,支持多种脚本函数,可通过观测云提供的脚本函数列表直接查看其语法格式,如
add_pattern()等。关于如何定义解析规则,可参考 Pipeline 介绍;
- 日志样本测试:输入日志数据,根据配置的解析规则进行测试,支持「一键获取」已经采集的日志数据样本。
关于如何调试样本数据,可参考调整 Pipeline。
- 支持将某一 Pipeline 脚本设置为“默认 Pipeline 脚本”,当前数据类型在匹配 Pipeline 处理时若未匹配到其它的 Pipeline 脚本,则数据会按照默认 Pipeline 脚本的规则做处理。设为默认的 Pipeline,名称后面会有一个【default】icon 作为标识。
注意:自定义 Pipeline 文件不能同名,但可以和官方 Pipeline 同名,此时 DataKit 会优先自动获取自定义 Pipeline 文件配置。若在日志采集器 .conf 中手动配置 Pipeline 文件,此时 DataKit 会优先获取手动配置的 Pipeline 文件。
操作 Pipeline¶
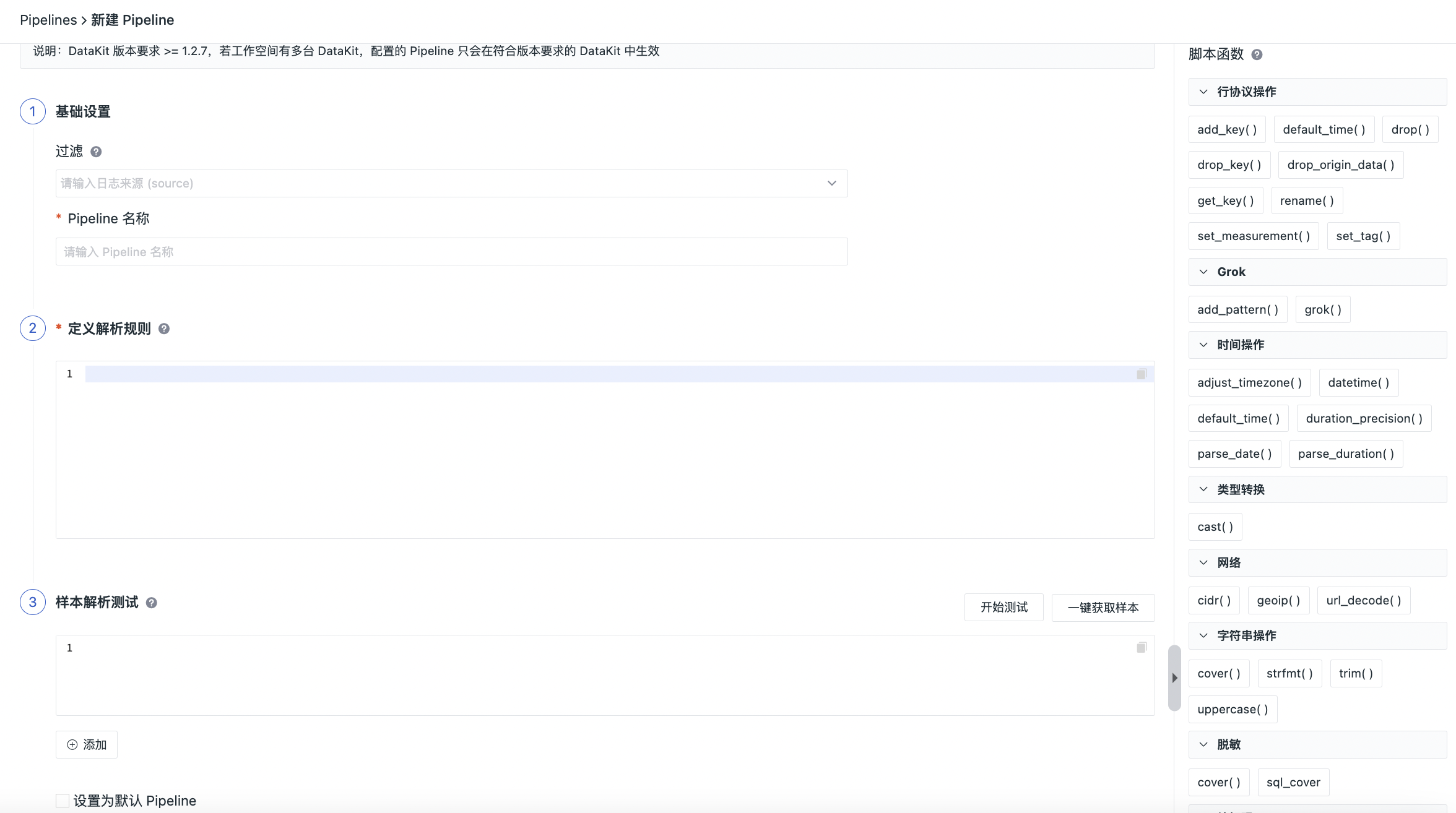
编辑/删除/启用/禁用¶
在观测云工作空间日志 > Pipelines,点击右侧操作下的按钮即可对 Pipeline 文件编辑/删除/启用/禁用。 注意:
- 编辑 Pipeline 文件后,默认生效时间为 1 分钟;
- 删除 Pipeline 文件后,无法恢复,需要重新创建;若存在同名的官方库 Pipeline 文件,DataKit 会自动匹配官方库 Pipeline 文件进行文本处理;
- 禁用 Pipeline 文件后,可通过启用重新恢复;若存在同名的官方库 Pipeline 文件,DataKit 会自动匹配官方库 Pipeline 文件进行文本处理;
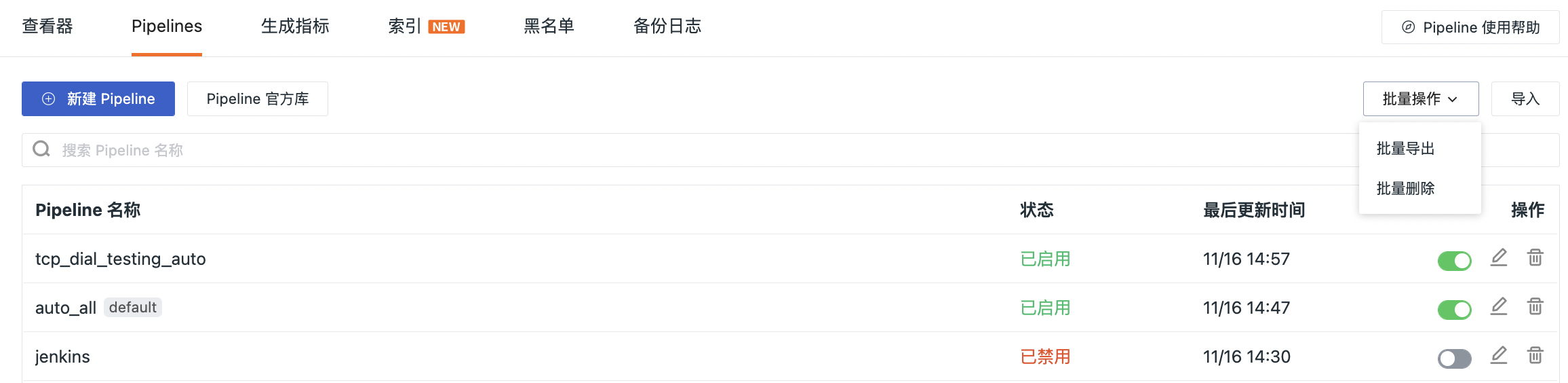
批量操作¶
在观测云工作空间日志 > Pipelines,点击批量操作,即可批量导出或批量删除 Pipelines。
注意:该功能仅对工作空间拥有者、管理员、普通成员显示,只读成员不显示。
导入/导出¶
在观测云工作空间日志 > Pipelines中支持导入/导出 Pipeline。
注意:导入的 JSON 文件需要是来自观测云的配置 JSON 文件。
Pipeline 官方库¶
在观测云工作空间日志 > Pipelines,点击 Pipeline 官方库即可查看内置标准的 Pipeline 官网文件库,包括如 nginx、apache、redis、elasticsearch、mysql 等。
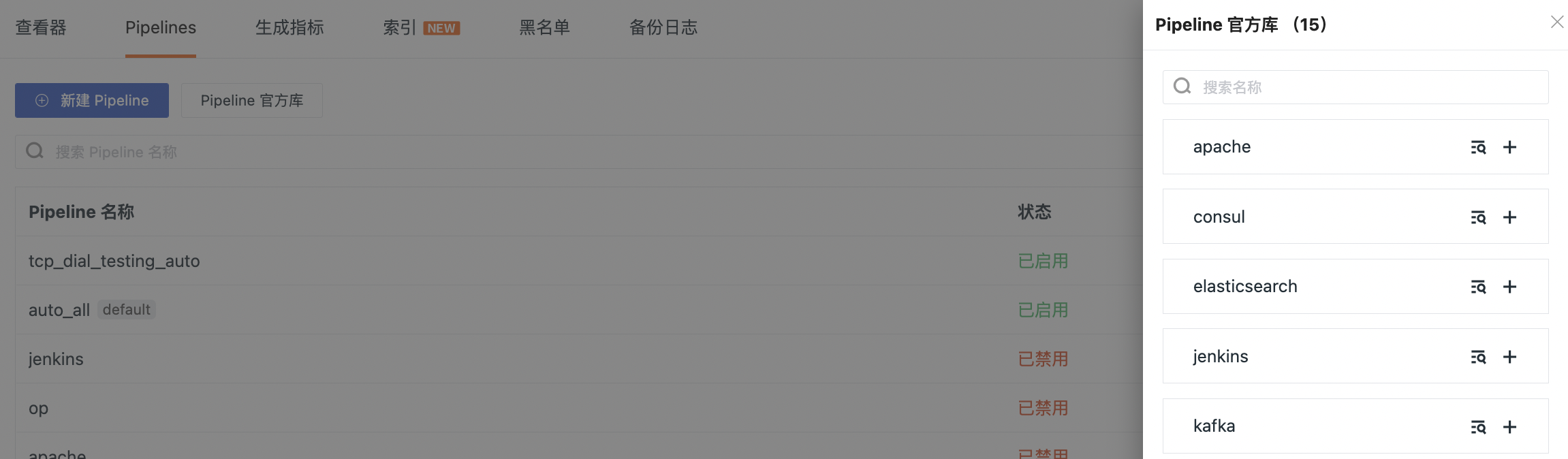
选择打开任意一个 Pipeline 文件,如 apache.p,可以看到内置的解析规则,如果需要自定义修改,可以点击右上角的克隆。
注意:
- Pipeline 官方库文件不支持修改。
- Pipeline 官方库自带多个日志样本测试数据,在「克隆」前可选择符合自身需求的日志样本测试数据。
- 克隆的 Pipeline 修改保存后, 日志样本测试数据同步保存。
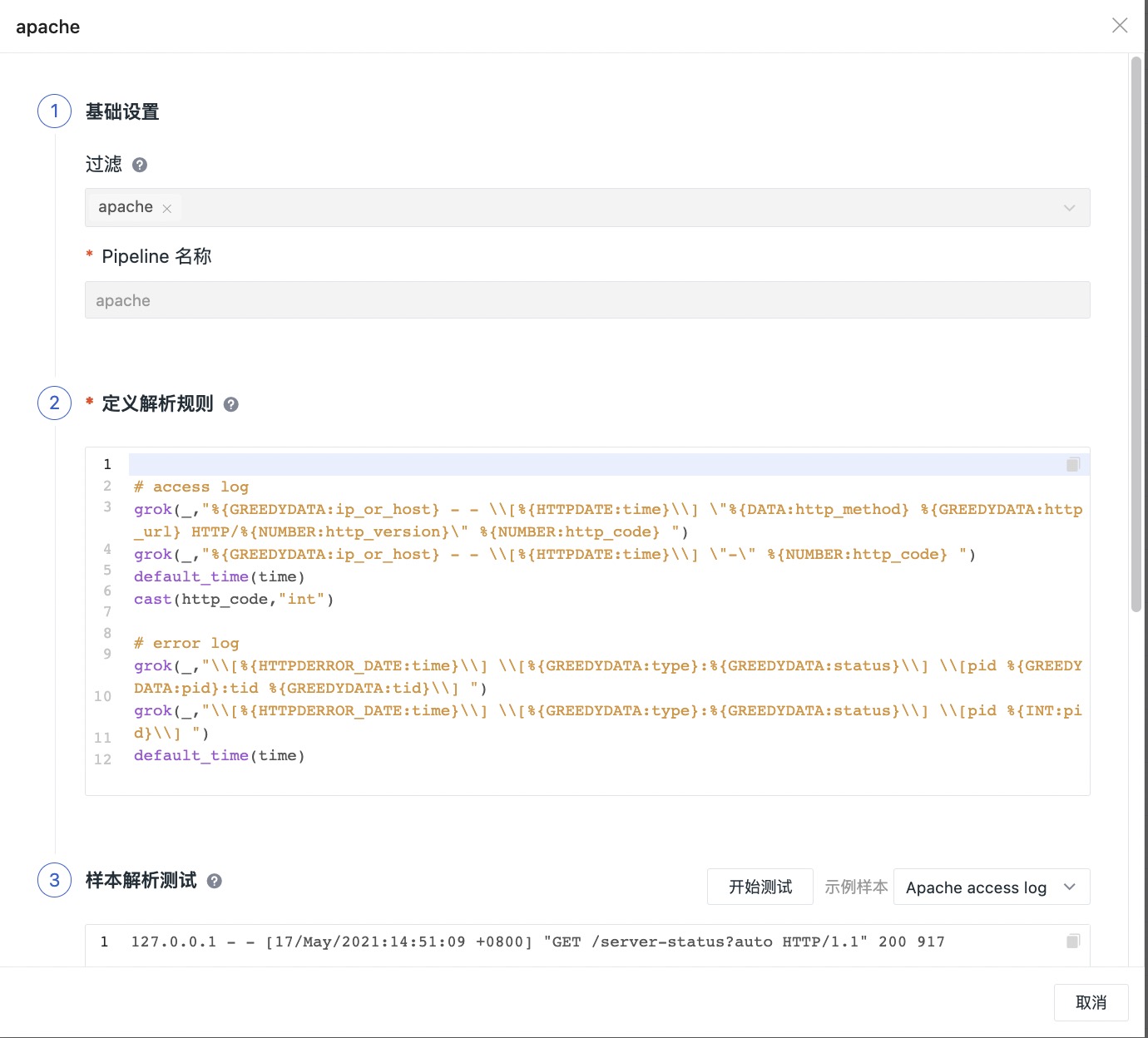
根据所选日志来源自动生成同名 Pipeline 文件名称,点击确定后,即可创建一个自定义 Pipeline 文件。
注意:DataKit 会自动获取官方库 Pipeline 文件,若克隆的自定义 Pipeline 文件与官方 Pipeline 同名,此时 DataKit 会优先自动获取新建的自定义 Pipeline 文件配置;若克隆的自定义 Pipeline 文件与官方 Pipeline 不同名,则需要在对应采集器的 Pipeline 修改对应的 Pipeline 的文件名称。
创建完成后,可以在日志 > Pipelines查看所有已经创建的自定义 Pipeline 文件,支持对 Pipeline 编辑/删除/启用 /禁用。

注意事项¶
若您从未通过 DataKit 配置过日志采集器,在观测云工作空间创建了 Pipeline 文件以后,您需要在您的主机上 安装 DataKit ,且开启 Pipeline 文件对应采集器的日志采集和 Pipeline 功能。以 Nginx 为例,在 Nginx 采集器 中开启日志采集并开启 pipeline = "nginx.p",开启完成后重启 DataKit 即可生效。
注意:pipeline = "nginx.p"中 nginx.p 可以不填,DataKit 会根据您选择的日志来源自动匹配您创建的日志 Pipeline 文件。若日志来源和 Pipeline 文件名称不一致,则需要在 pipeline = "..." 填入对应的 Pipeline 文件名称,DataKit 会优先匹配用户自定义的 Pipeline 文件。
[[inputs.nginx]]
...
[inputs.nginx.log]
files = ["/var/log/nginx/access.log","/var/log/nginx/error.log"]
Pipeline = "nginx.p"
更多操作手册可参考文档 日志 Pipeline 使用手册 和 DataKit Pipeline 使用手册。