OpenSearch High Availability Deployment¶
Introduction¶
OpenSearch is an open-source distributed search and analytics suite, derived from Elasticsearch OSS 7.10.2. It provides the foundational capabilities to perform interactive log analysis, real-time application monitoring, and data analysis.
| Node Type | Description | Best Practices for Production |
|---|---|---|
| Cluster manager | Manages overall cluster operations and tracks cluster status. This includes creating and deleting indices, tracking nodes joining and leaving the cluster, checking the health of each node in the cluster (by running ping requests), and assigning shards to nodes. | Having three dedicated cluster manager nodes across three different regions is the right approach for almost all production use cases. This configuration ensures your cluster never loses quorum. Two nodes are mostly idle most of the time unless one of them fails or requires some maintenance. |
| Cluster manager eligible | One of these nodes is elected as the cluster manager node through a voting process. | For production clusters, ensure you have dedicated cluster manager nodes. The way to achieve this is by marking all other node types as false. In this case, all other nodes must be marked as ineligible for the cluster manager role. |
| Data | Stores and searches data. Executes all data-related operations (indexing, searching, aggregating) on local shards. These are your cluster's workhorse nodes and require more disk space than any other node type. | When adding data nodes, keep them balanced across zones. For example, if there are three zones, add data nodes in multiples of three, one per zone. We recommend using nodes with large storage and RAM. |
| Ingest | Preprocesses data before storing it in the cluster. Runs ingest pipelines to transform data before adding it to the index. | If you plan to ingest large volumes of data and run complex ingest pipelines, we recommend using dedicated ingest nodes. You can also choose to offload indexing from data nodes so that data nodes are exclusively used for searching and aggregating. |
| Coordinating | Delegates client requests to shards on data nodes, collects and aggregates results into a final result, and sends that result back to the client. | A pair of dedicated coordinating-only nodes can prevent bottlenecks for high-volume search workloads. We recommend using CPUs with as many cores as possible. |
| Dynamic | Assigns specific nodes to custom tasks, such as machine learning (ML) jobs, preventing resource consumption from data nodes and thus not affecting any OpenSearch functionality. |
Prerequisites¶
-
Deployed Kubernetes cluster
-
Determined storage components (based on actual conditions)
- Public cloud storage block components (public cloud)
- OpenEBS storage plugin
Resource Catalog¶
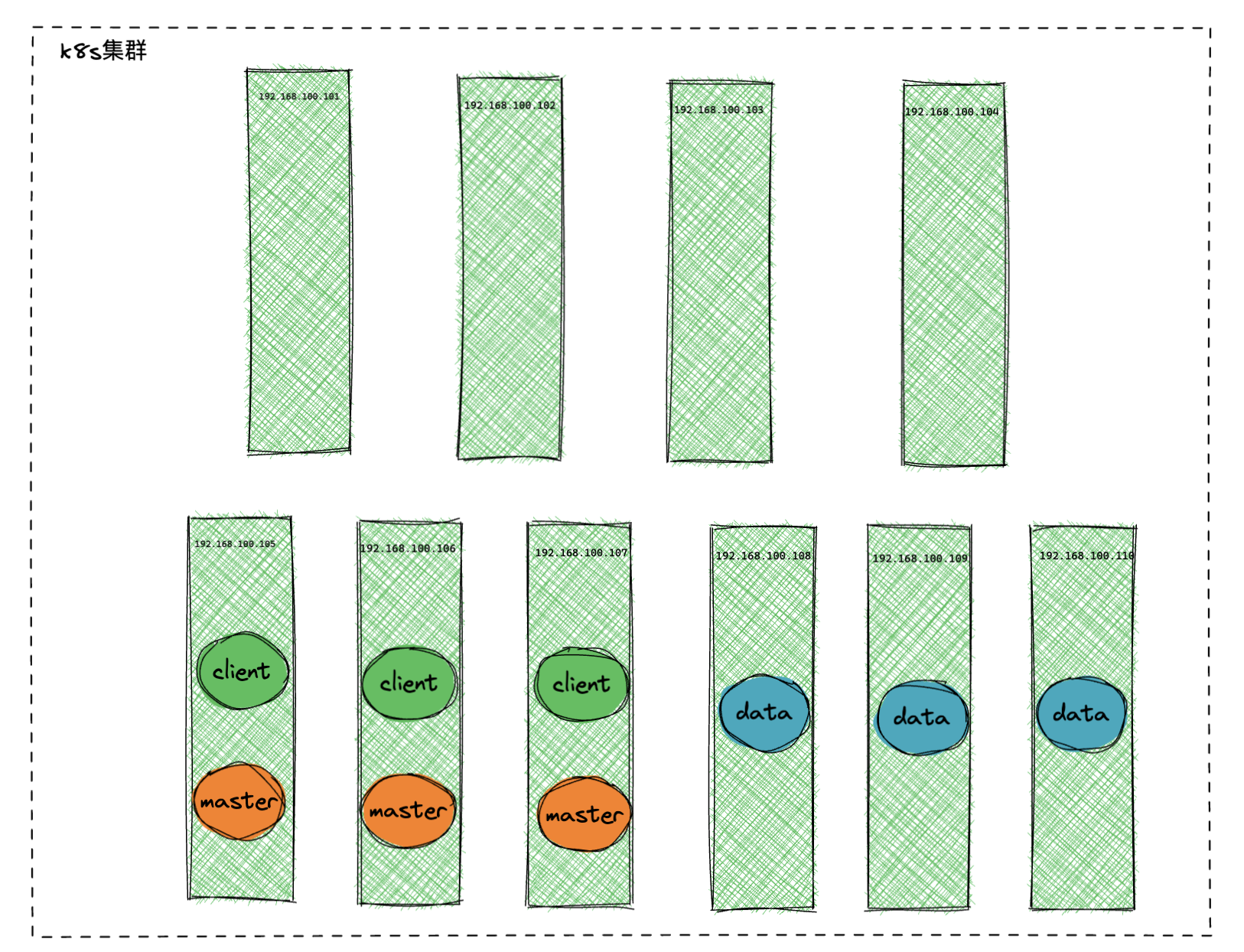
| Hostname | IP Address | Role | K8s Configuration | Data Storage |
|---|---|---|---|---|
| k8s-master | 192.168.100.101 | k8s, master | 4 CPU, 16G MEM, 100G DISK | |
| K8s-node01 | 192.168.100.102 | k8s, node01 | 4 CPU, 16G MEM, 100G DISK | |
| K8s-node02 | 192.168.100.103 | k8s, node02 | 4 CPU, 16G MEM, 100G DISK | |
| K8s-node03 | 192.168.100.104 | k8s, node03 | 4 CPU, 16G MEM, 100G DISK | |
| K8s-node04 | 192.168.100.105 | OpenES, master, client | 4 CPU, 16G MEM, 100G DISK | /data:200G |
| K8s-node05 | 192.168.100.106 | OpenES, master, client | 4 CPU, 16G MEM, 100G DISK | /data:200G |
| K8s-node06 | 192.168.100.107 | OpenES, master, client | 4 CPU, 16G MEM, 100G DISK | /data:200G |
| K8s-node07 | 192.168.100.108 | OpenES, data | 8CPU, 32G MEM, 100G DISK | /data:1T |
| K8s-node08 | 192.168.100.109 | OpenES, data | 8CPU, 32G MEM, 100G DISK | /data:1T |
| K8s-node09 | 192.168.100.110 | OpenES, data | 8CPU, 32G MEM, 100G DISK | /data:1T |
Default Configuration¶
| OpenSearch URL | opensearch-cluster-client.middleware |
|---|---|
| OpenSearch Port | 9200 |
| OpenSearch Account | openes/kJMerxk3PwqQ |
| Master JVM Size | 2G |
| Client JVM Size | 4G |
| Data JVM Size | 20G |
Deployment Architecture Diagram¶
Installation Preparation¶
Since OpenSearch consumes significant resources and requires exclusive cluster resources, we need to configure cluster scheduling in advance.
Cluster Label Settings¶
Run commands to label the cluster:
kubectl label node 192.168.100.105 192.168.100.106 192.168.100.107 openes=master-client
kubectl label node 192.168.100.108 192.168.100.109 192.168.100.110 openes=data
Check labels:
Cluster Taint Settings¶
Run commands to set cluster taints:
kubectl taint node 192.168.100.105 192.168.100.106 192.168.100.107 192.168.100.108 192.168.100.109 192.168.100.110 app=openes:NoExecute
Set OpenEBS StorageClass¶
If using public cloud, refer to the public cloud storage block component.
Deploy the following YAML configuration:
apiVersion: storage.k8s.io/v1
allowVolumeExpansion: true
kind: StorageClass
metadata:
annotations:
cas.openebs.io/config: |
- name: StorageType
value: "hostpath"
- name: BasePath
value: "/data/opensearch"
name: openebs-opensearch
provisioner: openebs.io/local
reclaimPolicy: Retain
volumeBindingMode: WaitForFirstConsumer
Ensure the
/datadirectory has sufficient disk capacity.
Installation¶
Modify Configuration¶
The infrastructure-related charts are located in the /etc/kubeasz/guance/infrastructure/charts directory. Change to this directory for operations.
$ cd /etc/kubeasz/guance/infrastructure/charts
$ ls
localpv-provisioner-3.3.0.tgz opensearch-cluster-0.0.1.tgz tdengine-0.4.0.tgz
Modify the
values.yamlfile under theopensearch-clusterdirectory, paying attention to theopensearchJavaOpts,nodeSelector,tolerations, andstorageClassparameters for each node type. SetresourcesandopensearchJavaOptsbased on actual conditions; Kubernetes-assigned memory should not be lower than the JVM heap memory. An odd number ofreplicasis preferred to prevent cluster split-brain.
opensearch-master:
...
replicas: 3
# Use init containers to set kernel parameters
# sysctlInit:
# enabled: true
opensearchJavaOpts: "-Xmx2g -Xms2g"
nodeSelector:
openes: master-client # Schedule clients and masters on similar machines
tolerations:
- effect: NoExecute
key: app
operator: Equal
value: openes
persistence:
...
storageClass: openebs-opensearch
opensearch-client:
...
replicas: 3
# sysctlInit:
# enabled: true
opensearchJavaOpts: "-Xmx2g -Xms2g"
nodeSelector:
openes: master-client # Schedule clients and masters on similar machines
tolerations:
- effect: NoExecute
key: app
operator: Equal
value: openes
persistence:
...
storageClass: openebs-opensearch
opensearch-data:
...
replicas: 3
# sysctlInit:
# enabled: true
opensearchJavaOpts: "-Xmx20g -Xms20g"
nodeSelector:
openes: data
tolerations:
- effect: NoExecute
key: app
operator: Equal
value: openes
persistence:
...
storageClass: openebs-opensearch
If you do not want to manually set the kernel parameter
vm.max_map_counton the host, you can enable thesysctlInitconfiguration to use init containers for this purpose. Setting this parameter via init containers will remain independent of the container lifecycle until the machine is restarted or the configuration is refreshed withsysctl -p.vm.max_map_countis a non-namespaced kernel parameter, and to minimize its impact, it is recommended to isolate OpenSearch deployments on dedicated machines.
Execute Installation¶
Run the installation command in the /etc/kubeasz/guance/infrastructure/charts directory:
$ helm install opensearch-cluster -n middleware --create-namespace -f opensearch-cluster/values.yaml opensearch-cluster-0.0.1.tgz
Output:
Release "opensearch-cluster" has been installed. Happy Helming!
NAME: opensearch-cluster
LAST DEPLOYED: Wed Nov 2 20:26:16 2022
NAMESPACE: middleware
STATUS: deployed
REVISION: 1
TEST SUITE: None
Verify Deployment and Configuration¶
Check Container Status¶
Output:
NAMESPACE NAME READY STATUS RESTARTS AGE
middleware opensearch-cluster-client-0 1/1 Running 0 63m
middleware opensearch-cluster-client-1 1/1 Running 0 4m52s
middleware opensearch-cluster-client-2 1/1 Running 0 4m47s
middleware opensearch-cluster-data-0 1/1 Running 0 63m
middleware opensearch-cluster-data-1 1/1 Running 0 63m
middleware opensearch-cluster-data-2 1/1 Running 0 63m
middleware opensearch-cluster-master-0 1/1 Running 0 63m
middleware opensearch-cluster-master-1 1/1 Running 0 63m
middleware opensearch-cluster-master-2 1/1 Running 0 4m31s
"Running" indicates successful deployment
Configure Accounts¶
Create User¶
Replace
kJMerxk3PwqQwith your desired password.
kubectl exec -ti -n middleware opensearch-cluster-client-0 -c opensearch-client \
-- curl -X PUT -u admin:admin http://127.0.0.1:9200/_plugins/_security/api/internalusers/openes \
-H 'Content-Type: application/json' \
-d '{"password": "kJMerxk3PwqQ","opendistro_security_roles": ["all_access"]}'
Output:
Verify User¶
If you modified the default password in the document, update the command accordingly.
Run the following command:
kubectl exec -ti -n middleware opensearch-cluster-client-0 -c opensearch-client -- curl -u openes:kJMerxk3PwqQ http://127.0.0.1:9200/_cat/indices
Output: