DataKit 基础运行情况以及性能说明¶
本文档主要展示 DataKit 在真实生产环境下的运行表现,大家可依据这里展示的数据作为参考,对标各自的环境。
基础环境信息¶
- 运行环境 : Kubernetes
- DataKit 版本 : 1.28.1
- 资源限制 : 2C4G
- 运行时长 : 1.73d
- 数据源 : 集群中有大量的应用在运行,DataKit 会主动采集各种应用的指标、日志以及 Tracing 数据
以下列举了高、中、低三种情况下的 DataKit 负载情况 1。
高负载情况下,DataKit 采集的数据量以及数据本身都比较复杂,会消耗更多的计算资源。
- CPU 占比
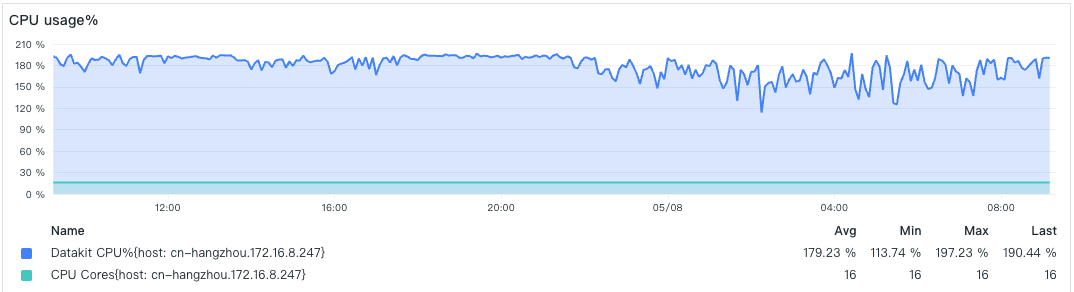
由于限制了 CPU 使用核数,这里 CPU 稳定在 200% 附近。
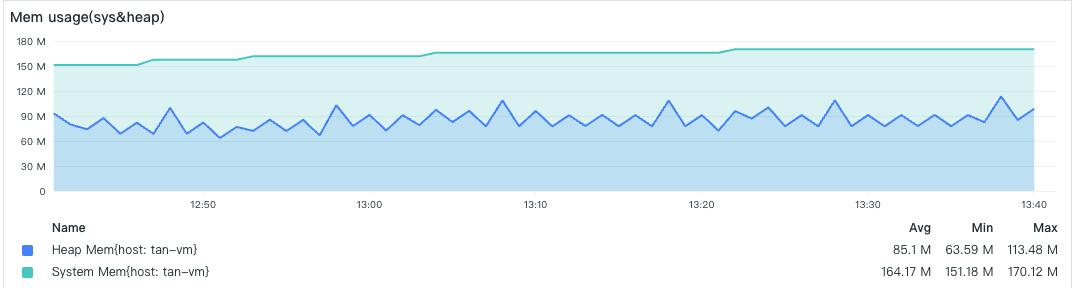
- 内存消耗
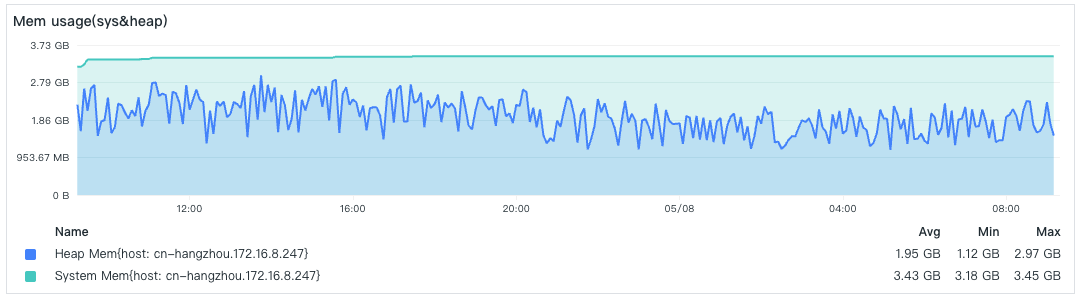
内存限制了 4GB,这里已经比较接近限制。当超过内存限制,DataKit POD 将被 OOM 重启。
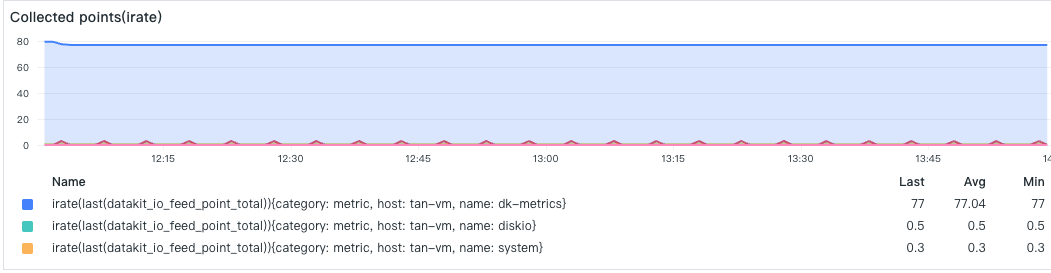
- 数据采集点数
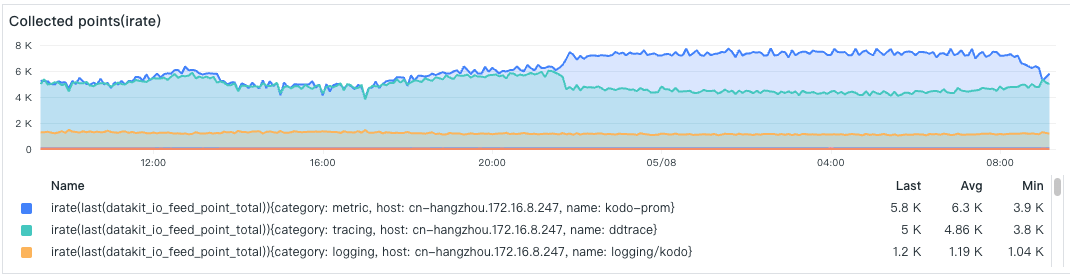
每个采集器采集的数据点数,排在首位的是一个 Prometheus 指标采集,每次采集的数据点比较多,其次是 Tracing 采集器。
- Pipeline 处理点数
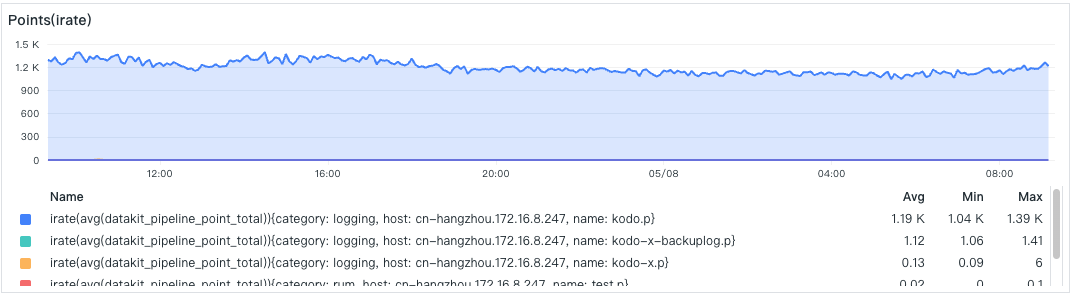
这里是某个具体 Pipeline 处理数据点的情况,有一个 Pipeline 脚本(kodo.p)业务比较繁忙。
- 网络发送

采集到的数据点最终都要通过网络发送到中心,这里展示的是 GZip 之后的数据点 Payload (HTTP Body)上传 2 情况。Tracing 因为其含有大量文本信息,所以其 Payload 特别大。
中度负载情况下,DataKit 的资源消耗大大降低。
- CPU 占比
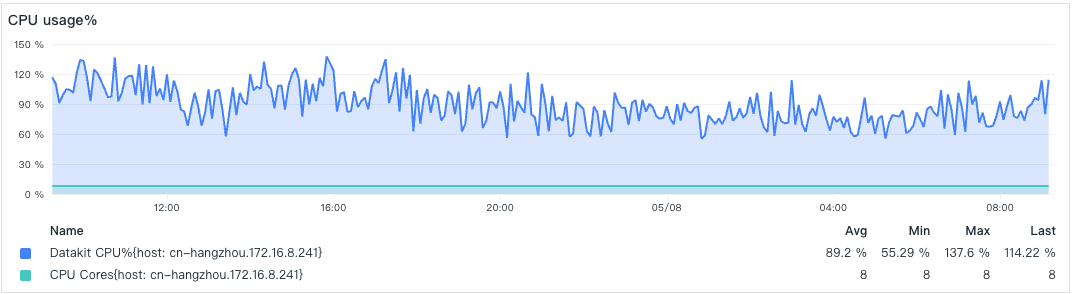
- 内存消耗
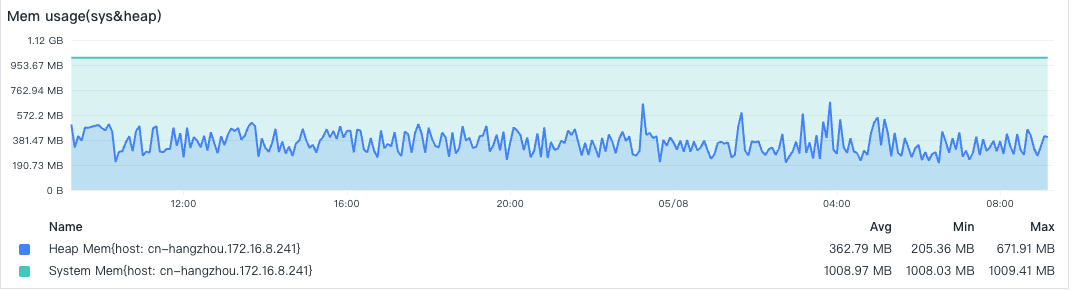
- 数据采集点数
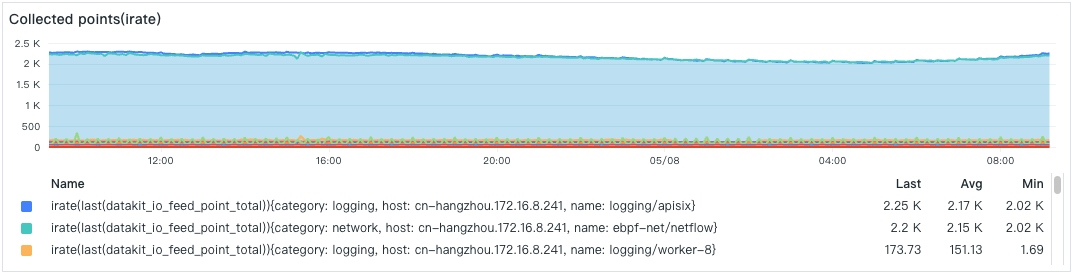
- Pipeline 处理点数

- 网络发送

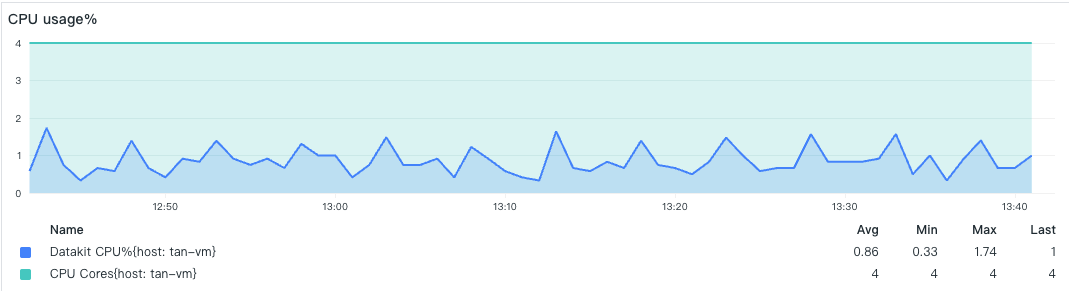

-
DataKit 都开启了 Point Pool,且使用 V2 的编码上传 ↩
-
该数值跟 Pod 流量会有一定的出入,Pod 统计的是 Kubernetes 层面网络流量信息,它的值会比此处的流量要大 ↩
-
该低负载的 DataKit 是在额外的一台 Linux 服务器上测试的,它只开启了基础的采集器。由于没有 Pipeline 参与,所以没有对应的数据 ↩