Pipelines¶
Pipelines 是一种运行在 DataKit 上的轻量级脚本语言,用于对采集到的数据进行自定义解析和修改。通过定义解析规则,它们能够将不同种类的数据细粒度地切割并转换为结构化的格式,以满足具体的数据管理需求。例如,用户可以通过 Pipelines 提取日志中的时间戳、状态和其他关键字段,并将这些信息作为标签使用。
DataKit 利用 Pipelines 的强大功能,使得用户能够在工作空间页面上直接编写和调试 Pipeline 脚本,从而实现对数据的更细粒度的结构化处理。这种处理不仅提高了数据的可管理性,而且通过 Pipeline 提供的丰富函数库,支持对常见数据进行标准化操作,如解析时间字符串和补全 IP 地址的地理信息等。
Pipeline 的主要特点包括:
- 作为一种轻量化脚本语言,Pipeline 提供了高效的数据处理能力;
- 它拥有丰富的函数库,支持对多种常见数据类型的标准化操作;
- 用户可以在工作空间页面直接编写和调试 Pipeline 脚本,使得脚本的创建和批量生效变得更加便捷。
目前,观测云支持配置本地 Pipeline 和中心 Pipeline。
- 本地 Pipeline:在数据采集时运行,要求 DataKit 采集器版本不低于 1.5.0;
- 中心 Pipeline:在数据上传到控制台中心后运行;
使用场景¶
除以下说明的特殊数据类型以外,其余所有数据均可由本地 Pipeline 或中心 Pipeline 进行处理。
类型 |
场景 |
|---|---|
| 本地 Pipeline | 在数据转发前处理日志 |
| 中心 Pipeline | 1. 用户访问 (Session) 数据、Profiling 数据、可用性监测数据; 2. 处理链路中的用户访问数据,如提取链路 message 中的 session、view、resource 等字段 |
使用前提¶
- 安装 DataKit;
- DataKit 版本要求 >= 1.5.0。
为了保证正常使用 Pipeline,请将 DataKit 升级到 1.5.0 及以上。版本过低会导致部分 Pipeline 功能失效。
在 DataKit<1.5.0 版本之前:
-
不支持默认 Pipeline 功能;
-
数据来源不支持多选,每个 Pipeline 只能选择一个
source。所以若您的版本低于 1.5.0,同时又多选了数据来源,则不会生效; -
Pipeline 名称为固定生成不支持修改。例如:日志来源选择了
nginx,则 Pipeline 名称固定为nginx.p。所以若您的版本低于 1.5.0,Pipeline 名称与数据来源名称不一致,则 Pipeline 不会生效。
在数据上传到中心系统后执行脚本(按处理数据大小单独收费)。
❗️该功能需付费使用。
开始新建¶
在工作空间管理 > Pipelines,点击新建 Pipeline。
或者您可以在指标、日志、用户访问、应用性能、基础设施菜单目录入口,点击 Pipelines 进行创建。
注意
Pipeline 文件创建以后,需要安装 DataKit 才会生效。DataKit 会定时从工作空间获取配置的 Pipeline 文件,默认时间为 1 分钟,可在 conf.d/datakit.conf 中修改。
- 选择 Pipeline 类型;
- 选择数据类型,并添加过滤条件;
- 输入 Pipeline 名称,即自定义 Pipeline 文件名;
- 选择是否设置为默认 Pipeline;
- 当选择新建中心 Pipeline,设定是否启用 Pipeline 处理转发数据;
- 提供测试样本;
- 输入函数脚本,配置解析规则;
- 保存。
注意
- 若过滤对象选择为日志,系统将自动过滤掉拨测数据,即使将该 Pipeline 设置为默认,也不会应用于拨测数据。
- 若过滤对象选择为“可用性拨测”,类型将自动设置为“中心 Pipeline”,且无法选择本地 Pipeline。
- Pipeline 文件命名需避免重名。
- 每个数据类型可支持设置两个默认 Pipeline。已设置为默认的 Pipeline 名称后会显示
default标识。
过滤条件¶
使用前提
使用该功能前,请确保版本满足以下要求:普通商业版需将 DataKit 升级至 1.93.0 及以上,本地 Pipeline 才会生效(中心 Pipeline 的配置不受 DataKit 版本影响);部署版需将中心 Pipeline 更新至 1.129.224 及以上。
选择数据类型后,可通过过滤条件限定 Pipeline 生效的数据范围。过滤条件支持使用通配符(wildcard)匹配:
| 通配符 | 含义 | 示例 |
|---|---|---|
* |
匹配任意字符(包括空字符) | backcenter_* 匹配所有以 backcenter_ 开头的字段 |
? |
匹配单个字符 | web?server 匹配 web0server、web1server 等 |
例如:
*_prod:匹配所有以_prod结尾的sourcenginx_*:匹配所有以nginx_开头的字段web?server:匹配web0server、web1server等单个字符变化的名称
匹配流程¶
数据进入 Pipeline 处理时,系统按以下顺序为其匹配解析规则:
-
精确匹配优先:如果存在过滤条件与当前数据来源完全一致的 Pipeline,直接使用该 Pipeline 处理数据。
-
复用历史匹配结果:如果此前已对相同数据来源执行过通配匹配,系统会直接复用上次的匹配结果,无需重新计算。
-
通配规则匹配:若不存在精确匹配且无历史记录,系统会检查所有配置了通配符过滤条件的 Pipeline,筛选出匹配当前数据来源的规则。
-
选择最具体的规则:如果同时有多条通配规则匹配成功,系统会自动选择约束最严格、匹配范围最精确的一条执行。选择标准如下:
判断标准 说明 固定字符越多越优先 规则中不含通配符的固定字符越多,表示约束越严格。例如 svc-prod-*比svc-*更具体?比*更优先?仅匹配单个字符,约束强于*。例如ab?cd优先于ab*cd表达式越长越优先 整体长度更长的规则通常更具体 字典序兜底 以上均相同时,按字符串排序决定 -
保存匹配结果:确定使用的 Pipeline 后,系统会将匹配结果保存下来。后续相同来源的数据进入时,直接复用该结果,提升处理效率。
示例:
假设配置了三条过滤规则:
| 规则 | 优先级 |
|---|---|
svc-* |
较低 |
svc-prod-* |
最高(固定字符更多) |
*prod* |
中等 |
当数据来源为 svc-prod-ab 时,三条规则都能匹配,系统最终选择 svc-prod-*。
测试样本¶
根据选择的数据类型,输入对应的数据,基于配置的解析规则进行测试。
- 一键获取样本:可自动获取已经采集的数据,包含 Message 和所有字段;
- 添加:可添加多条样本数据(最多 3 条)。
注意
在工作空间中创建的 Pipeline 文件统一保存在 <datakit 安装目录>/pipeline_remote 目录下。其中:
- 一级目录下的文件默认为日志 Pipeline。
- 每种类型的 Pipeline 文件保存在对应的二级目录中。例如,指标 Pipeline 文件
cpu.p保存在<datakit 安装目录>/pipeline_remote/metric/cpu.p路径下。
更多详情,可参考 Pipeline 各类别数据处理。
一键获取样本¶
在创建或编辑 Pipeline 时,点击 样本解析测试 > 一键获取样本,您可以选择是否根据指定的日志来源随机获取数据,或者指定具体的数据来源。
系统会自动从已采集并上报到工作空间的数据中,根据筛选的数据范围选取最新的一条数据,作为样本填入测试样本框进行测试。每次点击“一键获取样本”时,系统仅查询最近 6 小时内的数据。如果最近 6 小时内没有数据上报,则无法自动获取样本。
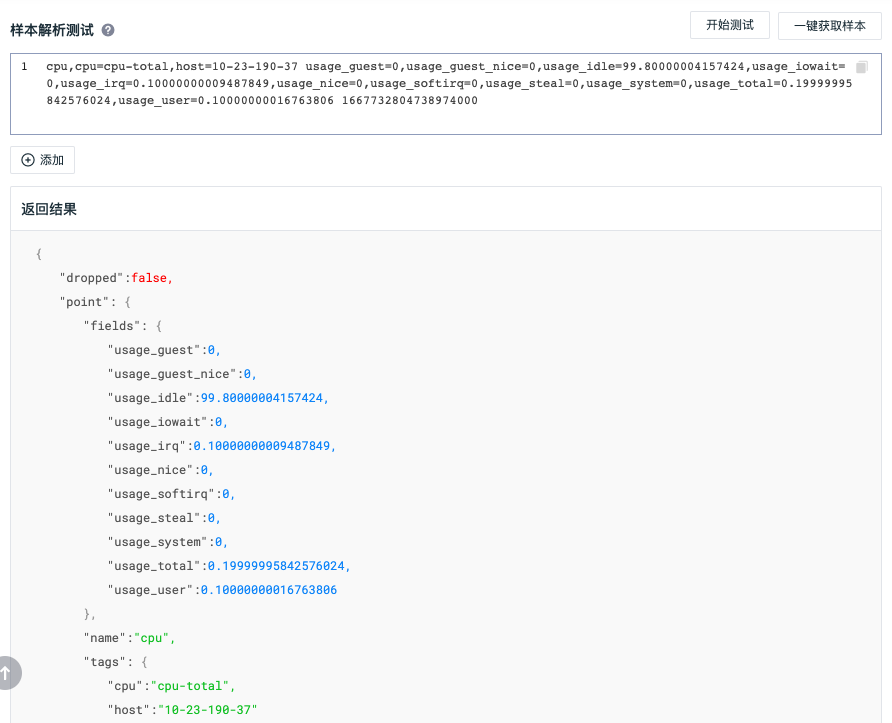
调试示例:
以下是一个一键获取的指标数据样本,指标集为 cpu,标签为 cpu 和 host。从 usage_guest 到 usage_user 的字段均为指标数据,最后的 1667732804738974000 是时间戳。通过返回结果,可以清晰地了解一键获取样本的数据结构。
手动输入样本¶
您也可以直接手动输入样本数据进行测试,支持两种格式类型:
- 日志数据可在样本解析测试中直接输入
message内容进行测试; - 其他数据类型先将内容转换成“行协议”格式的内容,再输入进行样本解析测试。
更多日志 Pipeline 详情,可参考 日志 Pipeline 使用手册。
行协议示例¶

cpu、redis为指标集;tag1、tag2为标签集;f1、f2、f3为字段集(其中f1=1i表示为int,f2=1.2表示默认为float,f3="abc"表示为string);162072387000000000为时间戳;- 指标集和标签集之间用逗号隔开;多个标签之间用逗号隔开;
- 标签集和字段集之间用空格隔开;多个字段之间用逗号隔开;
- 字段集和时间戳之间用空格隔开;时间戳必填;
- 若是对象数据,必须有
name标签,否则协议报错;最好有message字段,主要便于做全文搜索。
更多行协议详情,可参考 DataKit API。
更多行协议数据的获取方式,可在 conf.d/datakit.conf 中配置 output_file 的输出文件,并在该文件中查看行协议。
定义解析规则¶
通过手动编写或 AI 定义不同来源数据的解析规则,支持多种脚本函数,可通过右侧系统提供的脚本函数列表直接查看其语法格式,如 add_pattern() 等。
关于如何定义解析规则,可参考 Pipeline 手册。
手动编写¶
自主编写数据解析规则,可设置文本自动换行或内容溢出。
AI 生成¶
AI 生成解析规则是基于模型生成 Pipeline 解析,旨在快速提供初步的解析方案。
注意
由于模型生成的规则可能无法覆盖所有复杂的情况或场景,因此返回的结果可能并不完全准确。建议将其作为参考和起点,生成后根据具体的日志格式和需求进行进一步的调整和优化。
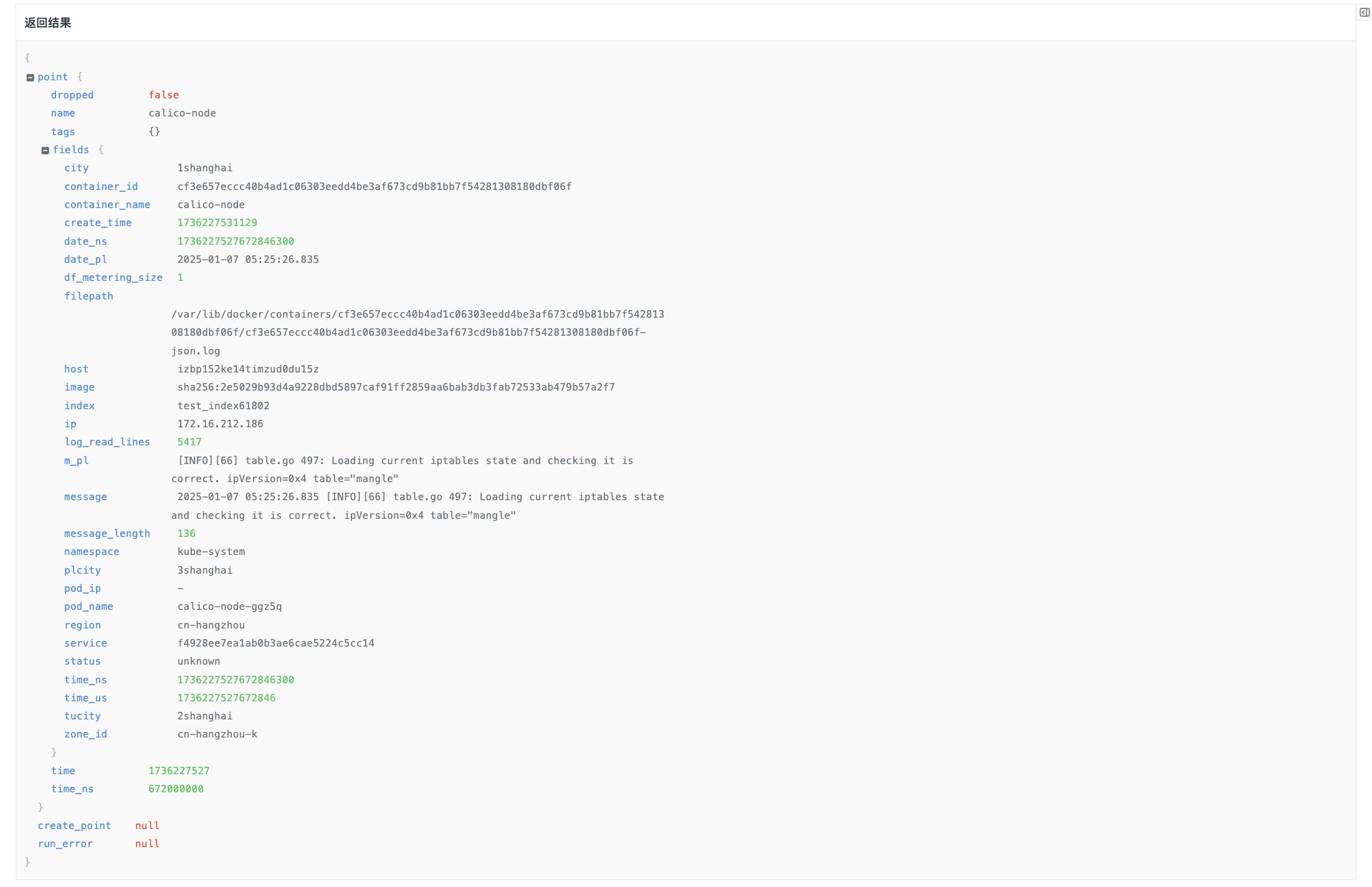
现根据样本输入需要提取的内容和名称,比如:
-"date_pl":"2024-12-25 07:25:33.525",
-"m_pl":"[INFO][66] route_table.go 237: Queueing a resync of routing table. ipVersion=0x4"
点击生成 Pipeline:

测试后,返回结果如:
更多详情,可参考 规则编写指南。
开始测试¶
在 Pipeline 编辑页面,您可对已填写的解析规则进行测试,只需要在样本解析测试中输入数据进行测试,若解析规则不符合,则返回错误提示的结果。样本解析测试为非必填项,样本解析测试后,测试的数据同步保存。
终端命令行调试¶
除了在控制台调试 Pipeline 以外,您也可以通过终端命令行来调试 Pipeline。
更多详情,可参考 如何编写 Pipeline 脚本。