主机智能检测¶
依托智能检测算法,系统将定期对主机的 CPU 和内存使用情况进行智能监测。当检测到 CPU 或内存出现异常时,通过深入的根因分析来确定主机是否存在急剧增加、减少或持续性上升等异常模式,进而有效监控主机的运行状态和稳定性。
应用场景¶
适用于对稳定性和可靠性要求较高的业务主机的监控,支持对产生的异常事件提供分析报告。
检测配置¶
-
定义监控器名称;
-
选择检测范围:通过筛选组合,限定检测的主机范围。若不添加筛选,观测云检测所有主机的数据。
查看事件¶
监控器会获取最近 10 分钟的检测对象主机的 CPU、内存、网络和磁盘使用情况,识别出现异常情况时,会生成相应的事件,在事件 > 智能监控列表可查看对应异常事件。
事件详情页¶
点击事件,可查看智能监控事件的详情页,包括事件状态、异常发生时间、异常名称、分析报告、扩展字段、告警通知、历史记录和关联事件。
-
点击右上角的跳转到监控器,可查看调整智能监控配置;
-
点击右上角的导出按钮,支持选择导出 JSON 文件与导出 PDF 文件,从而获取当前事件所对应的所有关键数据。
分析报告
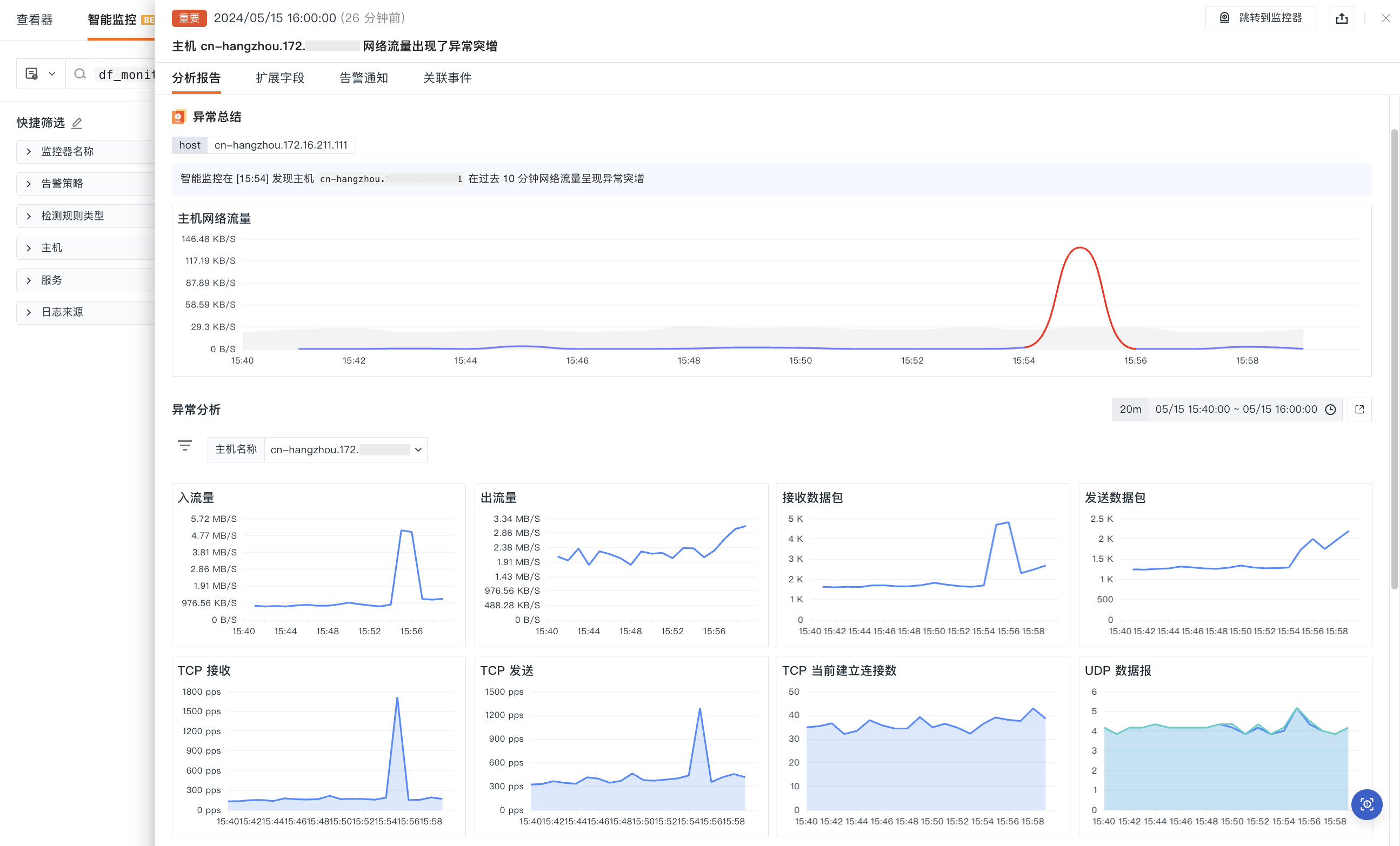
- 事件内容:显示查看监控器配置的事件内容;
- 异常总结:显示查看当前异常主机名标签、异常分析报告详情、异常值时序图显示异常趋势;
- 异常分析:异常分析仪表板,可查看主机的异常进程、CPU 使用率等基础信息;
- 主机详情:可查看主机集成运行情况、系统信息,及云厂商信息。
注意
存在多个区间异常时,异常总结 > 异常趋势图及异常分析仪表板默认展示第一段异常区间的异常情况分析,可以点击“异常趋势图”进行切换,切换后异常分析仪表板同步联动。