阈值检测¶
当前文档定位
本文档为检测规则配置流程中的第二步。配置完成后,请返回主文档继续第三步:事件通知。
数据范围:支持全部数据类型,如指标 M、日志 L、链路 T、用户访问数据 R、对象 O 等)。
检测配置¶
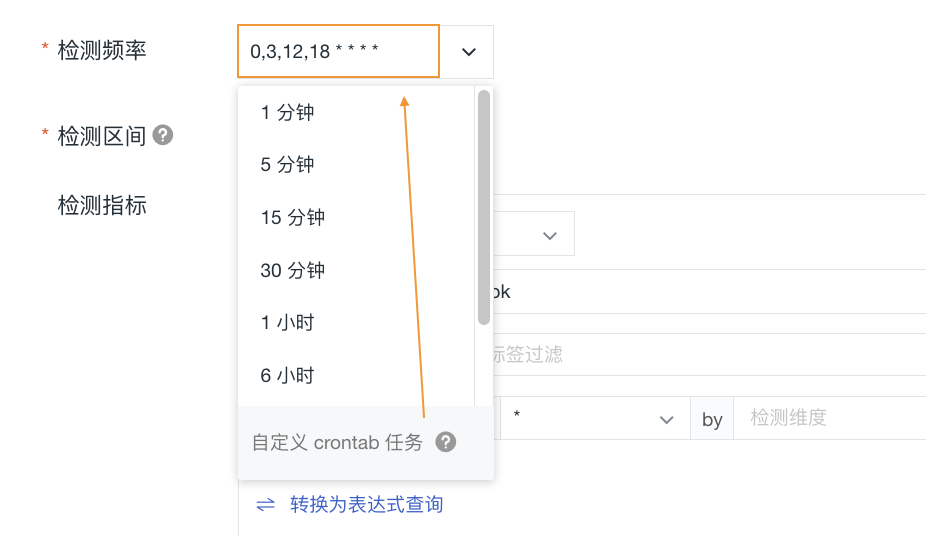
检测频率¶
设置执行检测的时间周期。
-
预设选项:1 分钟、5 分钟、10 分钟、15 分钟、30 分钟、1 小时
-
Crontab 模式:点击“切换到 Crontab 模式”可配置自定义周期,支持基于秒、分钟、小时、天、月、周等周期配置定时任务执行情况。
检测区间¶
设置每次检测查询的数据时间范围(❗️检测区间应大于等于检测频率,且需与数据实际上报周期匹配,避免漏检或误报)。
- 预设选项:
| 检测频率 | 检测区间(下拉可选项) |
|---|---|
| 30s | 1m/5m/15m/30m/1h/3h |
| 1m | 1m/5m/15m/30m/1h/3h |
| 5m | 5m/15m/30m/1h/3h |
| 15m | 15m/30m/1h/3h/6h |
| 30m | 30m/1h/3h/6h |
| 1h | 1h/3h/6h/12h/24h |
| 6h | 6h/12h/24h |
| 12h | 12h/24h |
| 24h | 24h |
- 自定义格式:自定义输入检测区间,如:20m(最近 20 分钟)、2h(最近 2 小时)、1d(最近 1 天)。
检测指标¶
基于 DQL 定义检测数据源及聚合方式。
请避免选择高基数字段作为检测维度。如果配置不当,触发条件过于宽松,可能会引发频繁告警。当前查询最大返回数量为 10 万条记录。
配置示例:在配置监控器的检测指标时,选择了 by trace_id 作为分组字段。
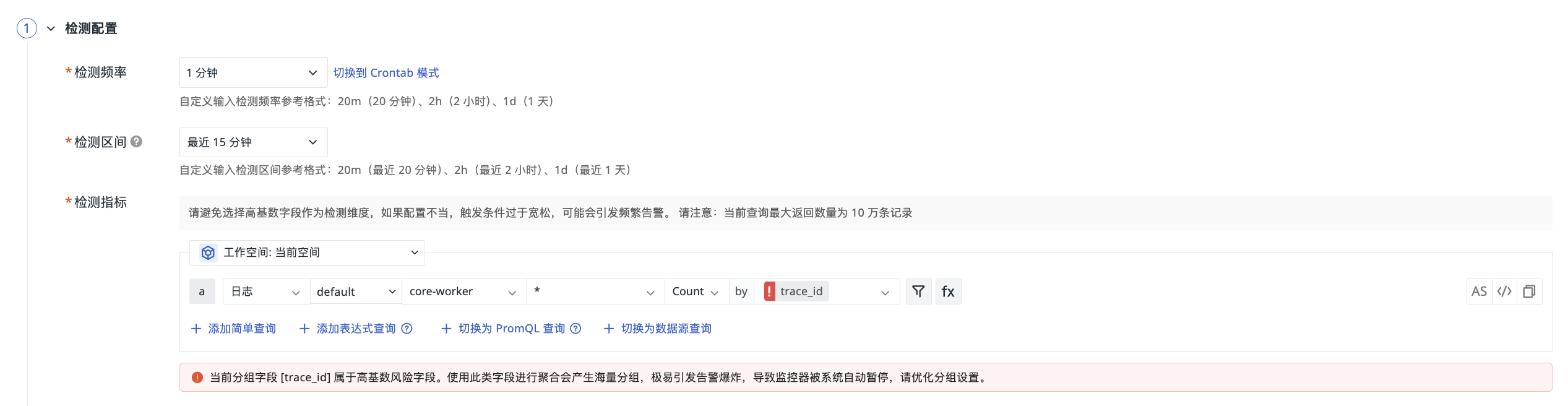
系统此时会提示您:
当前分组字段 trace_id 属于高基数风险字段。使用此类字段进行聚合会产生海量分组,极易引发告警爆炸,导致监控器被系统自动暂停,请优化分组设置。
配置要素¶
| 配置项 | 说明 |
|---|---|
| 工作空间 | 默认当前空间,可切换至其他授权空间 授权后,您可以使用当前账号下其他工作空间的检测指标来创建监控器。规则创建成功后,即可实现跨工作空间的告警配置。需要留意的是,当您选择其他工作空间时,检测指标的下拉列表仅会显示当前工作空间已被授权使用的数据类型 |
| 数据源类型 | 指标、日志、链路、用户访问数据等 |
| 查询方式 | 简单查询、表达式查询、PromQL 查询、数据源查询 |
| 筛选条件 | 通过标签过滤检测对象 |
| 聚合方式 | avg、sum、max、min、count 等 |
| 函数支持 | 点击 fx 按钮,支持选择以下函数:❗️当选择转换函数 derivative、difference、non_negative_derivative、non_negative_difference 时,需要添加 interval。例如:[::5m] |
触发条件¶
配置触发条件及严重程度。当查询结果为多个值时,任一值满足触发条件则产生事件。
支持配置致命、严重、重要、警告四级阈值,以及正常恢复条件。
| 等级 | 配置 | 说明 |
|---|---|---|
| 致命 | 当 Result >= [值] |
最高等级告警,需立即处理 |
| 严重 | 当 Result >= [值] |
高等级告警,需优先处理 |
| 重要 | 当 Result >= [值] |
中等级告警,需关注 |
| 警告 | 当 Result >= [值] |
低等级告警,需留意 |
| 正常 | [N] 次检测无事件产生 |
若检测指标触发了“致命”、“严重”、“重要”、“警告”异常事件,之后连续 N 次检测都正常,则产生“正常”事件。用于判定异常事件是否恢复正常,建议配置 |
更多详情,可参考 事件等级说明。
高级选项¶
连续触发判断¶
开启后,持续满足触发条件时才产生事件,避免瞬时波动误报(❗️最大配置上限为 10 次)。
大批量告警保护¶
系统默认开启。
当单次检测产生的告警数量超过预设阈值时,系统会自动切换到按状态汇总策略:不再逐个处理告警对象,而是根据事件状态生成少量摘要告警并进行推送。
这样既能确保通知的及时性,又能显著减少告警噪声,避免因处理过多告警而导致超时风险。
当此开关开启,后续监控器检测到异常后产生的此类事件详情中不会展示历史记录和关联事件。
恢复条件¶
配置恢复条件及严重程度。当查询结果为多个值时,任意一值满足触发条件则产生恢复事件。
针对不同等级设置独立的恢复阈值,实现降级恢复。例如:严重告警需在数值降至 70 以下恢复,而重要告警在 80 以下即可恢复。
恢复告警逻辑¶
启用“恢复条件”后,系统会使用 Fault ID(故障 ID)作为唯一标识来管理告警的整个生命周期(包括创建 Issue 等操作)。
当同时开启分级恢复功能时:
-
平台会为每个告警级别(如
critical,warning)单独配置一套恢复规则(即恢复阈值) -
每个级别的告警状态和恢复状态独立计算
-
不会影响原有 Fault ID 标识的告警生命周期
因此,当监控器首次触发告警(即开启一个新的告警生命周期)时,系统同时产生两条告警消息。它们看似相同,是因为:
-
第一条告警来源:整体检测(
check),代表整个故障生命周期的开始(基于原始规则); -
第二条告警来源:分级检测(
critical/error/warning/…),代表开启的分级恢复功能已启动,用于呈现具体告警级别及其后续恢复状态(如critical_ok)。
上述中,df_monitor_checker_sub 字段是区分两类告警的核心依据:
-
check:表示整体检测的结果; -
其他值(如
critical、error、warning等):对应分级检测规则的结果。
因此,当告警首次触发时,会出现两条记录,内容相似,但来源和用途不同。
df_monitor_checker_sub |
T+0 | T+1 | T+2 | T+3 |
|---|---|---|---|---|
check |
check |
error |
warning |
ok |
critical |
critical |
critical_ok |
||
error |
error |
error_ok |
||
warning |
warning |
warning_ok |
数据断档¶
当检测指标在检测区间内查询结果为空时的处理策略:
| 选项 | 说明 |
|---|---|
| 不触发事件(默认) | 无数据时不产生告警,适用于允许数据缺失的场景 |
| 查询结果视为 0 | 将空数据视为 0 值进行阈值判定 |
| 触发数据断档事件 | 无数据时视为异常,触发数据断档事件 |
| 触发致命事件 | 无数据时触发致命等级事件 |
| 触发严重事件 | 无数据时触发严重等级事件 |
| 触发重要事件 | 无数据时触发重要等级事件 |
| 触发警告事件 | 无数据时触发警告等级事件 |
| 触发恢复事件 | 无数据时触发恢复事件 |
同时配置触发条件、数据断档、信息生成时,按照如下优先级判断触发:数据断档 > 触发条件 > 信息事件生成。
即:先判断是否断档,再判断是否触发阈值,最后判断是否生成信息事件。
信息生成¶
开启此选项后,系统会将所有未匹配到上述触发条件的检测结果,以“信息”事件的形式进行写入。
适用于需要记录正常状态变化或低优先级信息的场景。
后续配置¶
完成上述检测配置后,请继续配置: