Pointer Filters¶
This document mainly describes the basic use and considerations of DataKit Filter.
Introduction¶
DataKit Filter is used to filter the collected points and filter out some unwanted data, or define some policies for successive handling. Its function is similar to Pipeline, but there is a difference:
| Data Processing Component | Support Local Configuration | Distributed by Support Center | Support Data Discarding | Support data rewriting | Instruction |
|---|---|---|---|---|---|
| Pipeline | By configuring Pipeline in the collector or writing Pipeline in Guance Studio | ||||
| Filter | Write Pipeline in Guance Studio or configure filter in DataKit.conf |
It can be seen from the table that Filter is a more convenient data filtering tool than Pipeline if only some data is simply filtered out.
How to use Filter¶
The main function of Filter is data filtering, which is based on judging the collected data through certain screening conditions, and the data that meets the screening conditions will be discarded.
The basic syntax pattern for filters is:
Among them, conditions can be a combination of other conditions. Here are some examples of filters:
# This article is generally aimed at log data. It is used to determine all log types and filter out key1/key2 that meet the requirements
# Note that key1 and key2 here are both tag or field in the row protocol field
{ source = re('.*') AND ( key1 = "abc" OR key2 = "def") }
# This one typically for Tracing data, is used for a service named app1 that filters out eligible key1/key2
{ service = "app-1" AND ( key1 = "abc" OR key2 = "def") }
Data Range for Filter Action¶
As (most) data collected by DataKit is reported in the form of data point, all filters work on top of data point. Filters support data filtering on the following data:
- Measurement name: For different types of data, the business attribution of measurement is different, as follows:
- For time series data (M), a
measurementtag is injected into its tag list when the filter is running, so you can write a metric set-based filter as follows:{ measurement = re('abc.*') AND ( tag1='def' and field2 = 3.14)}. - For object data (O), when the filter runs, a
classtag is injected into its tag list, so an object-based filter can be written like this:{ class = re('abc.*') AND ( tag1='def' and field2 = 3.14)} - For log data (L), when the filter runs, a
sourcetag is injected into its tag list, so an object-based filter can be written like this:{ trace = re('abc.*') AND ( tag1='def' and field2 = 3.14)}
- For time series data (M), a
If there is a tag named
measurement/class/sourcein the original tag, the tag values of the original measurement/class/source will not exist during the filter running
- Tag: All data types can be filtered on their tags.
- Field: Filtering can be performed on all data types on their Field.
Manual Configuration of Filter in DataKit¶
In datakt.conf, you can manually configure blacklist filtering, as shown in the following example:
[io]
[io.Filters]
logging = [ # Filtering for log data
"{ source = 'datakit' or f1 IN [ 1, 2, 3] }"
]
metric = [ # Filtering for metrics
"{ measurement IN ['datakit', 'disk'] }",
"{ measurement MATCH ['host.*', 'swap'] }",
]
object = [ # Filtering for objects
"{ class MATCH ['host_.*'] }",
]
tracing = [ # Filtering for tracing
"{ service = re("abc.*") AND some_tag MATCH ['def_.*'] }",
]
network = [ # Filtering for Network
"{ source = 'netflow' or f1 IN [ 1, 2, 3] }"
]
keyevent = [ # Filtering for KeyEvent
"{ source = 'datakit' or f1 IN [ 1, 2, 3] }"
]
custom_object = [ # Filtering for CustomObject
"{ class MATCH ['host_.*'] }",
]
rum = [ # Filtering for RUM
"{ source = 'resource' or app_id = 'appid_xxx' or f1 IN [ 1, 2, 3] }"
]
security = [ # Filtering for Security
"{ category = 'datakit' or f1 IN [ 1, 2, 3] }"
]
profiling = [ # Filtering for Profiling
"{ service = re("abc.*") AND some_tag MATCH ['def_.*'] }",
]
Warning
Filters in datakit.conf developped for debugging, you should use web-side Blacklist for production usage. Once the filter is configured in datakit.conf, the Blacklist configured in web-side will no longer take effect.
PS: Blacklist will be deprecated in the future, we recommend use Pipeline drop() to drop unwanted data.
The configuration here should follow the following rules:
- A specific set of filters that must specify the type of data it filters
- Do not configure multiple entries for the same data type (i.e. multiple sets of logging filters are configured), otherwise datakit.conf will parse an error and cause the DataKit to fail to start
- Under a single data type, multiple filters can be configured (metric in the above example)
- Filters with syntax errors are ignored by DataKit by default, which will not take effect, but will not affect other functions of DataKit
Basic Syntax Rules for Filters¶
Basic Grammar Rules¶
The basic syntax rules of filter are basically the same as Pipeline, see here.
Operator¶
Support basic numerical comparison operations:
-
Judge equality
=!=
-
Judge the value
>>=<<=
-
Parenthesis expression: Used for logical combination between arbitrary relationships, such as:
-
Built-in constants
true/falsenil/null: null value, see following usage about them
In addition, the following list operations are supported:
| Operator | Support Numeric Types | Description | Example |
|---|---|---|---|
IN, NOTIN |
Numeric list | Whether the specified field is in a list, and multi-type cluttering is supported in the list | { abc IN [1,2, "foo", 3.5]} |
MATCH, NOTMATCH |
Regular expression list | Whether the specified field matches the regular in the list, which only supports string types | { abc MATCH ["foo.*", "bar.*"]} |
Note
- Only ordinary data types such as string, integer, floating point can appear in the list. Other expressions are not supported.
The keywords IN/NOTIN/MATCH/NOTMATCH are case insensitive, meaning in, IN and In have the same effect. In addition, other operands are case sensitive, for example, the following filters express different meanings:
{ abc IN [1,2, "foo", 3.5]} # whether field abc(tag or field)is in the list
{ abc IN [1,2, "FOO", 3.5]} # FOO is not equal to foo
{ ABC IN [1,2, "foo", 3.5]} # ABC is not equal to abe
In data point, all fields of and their values are case-sensitive.
- Identity/Non-identity Expression Syntax:
Usage of nil/null¶
nil/null is used to indicate the non-existence of certain fields, and can be used in =/!=/IN/NOTIN operations:
{ some_tag_or_field != nil } # The field exists
{ some_tag_or_field = nil } # The field does not exist
{ some_tag_or_field IN ["abc", "123", null] } # The field either does not exist or can only equal specified values
{ some_tag_or_field NOTIN ["abc", "123", null] } # The field is not null and not equal to specified values
Here, nil/null is not case sensitive and can be written in various forms such as NULL/Null/NIL/Nil.
Usage Example¶
You can view the filtering using the datakit monitor -V command:
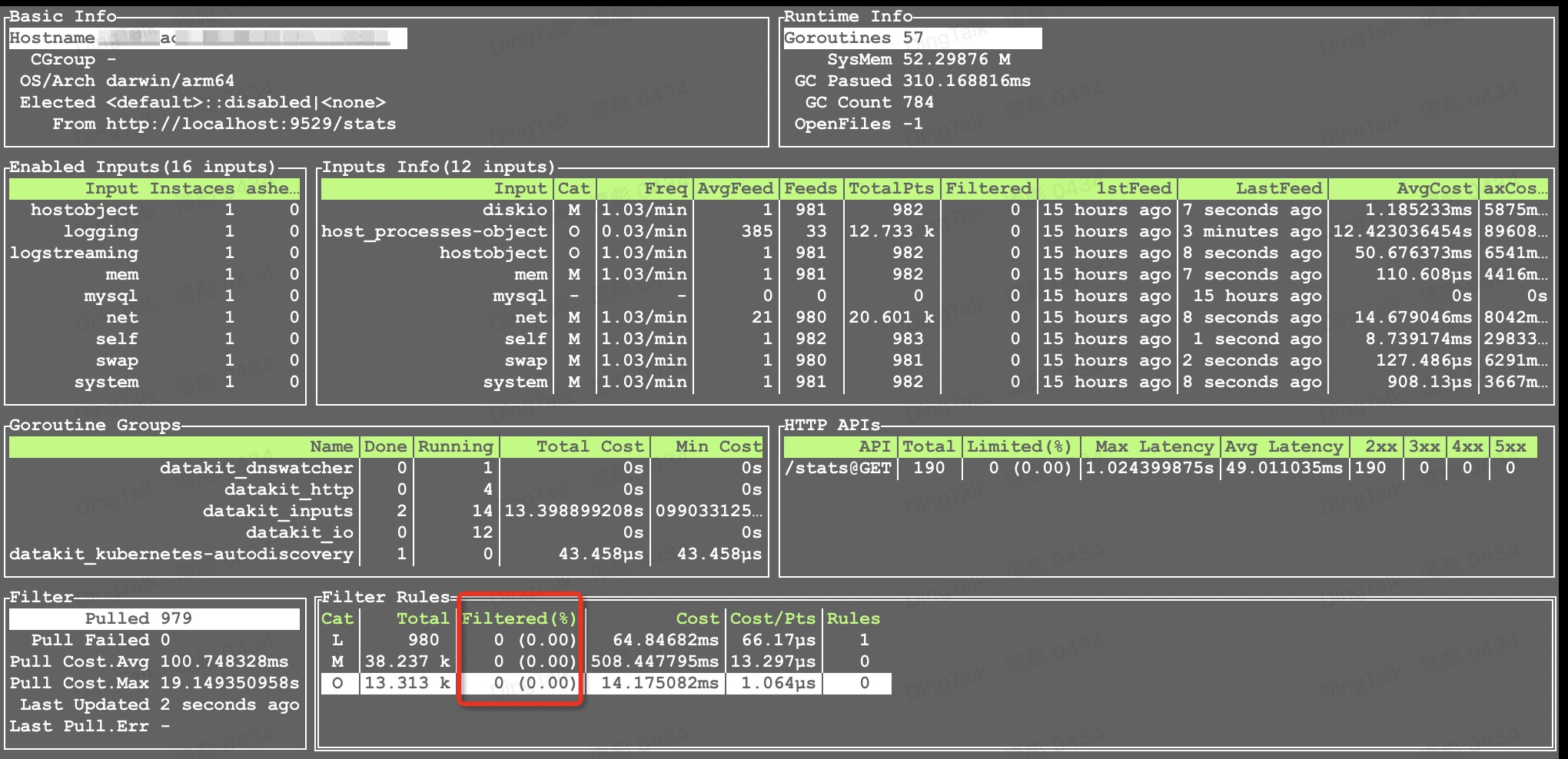
Network¶
The eBPF collector needs to be turned on. Suppose we want to filter out network traffic with destination port 443, the configuration file can read as follows:
[io]
...
[io.filters]
network = [ # Filtering for Network
"{ source = 'netflow' and dst_port IN [ '443' ] }"
]
Using the curl command to trigger the network traffic curl https://www.baidu.com:443, you can see that the network traffic with the target port 443 has been filtered out.
Profiling¶
The configuration file is as follows:
[io]
...
[io.Filters]
profiling = [ # Filtering for Profiling
"{ service = 'python-profiling-manual' }",
]
Open 2 Profiling:
DD_ENV=testing DD_SERVICE=python-profiling-manual DD_VERSION=7.8.9 python3 profiling_test.py
DD_ENV=testing DD_SERVICE=2-profiling-python DD_VERSION=7.8.9 python3 profiling_test.py
Python source code file profiling_test.py:
import time
import ddtrace
from ddtrace.profiling import Profiler
ddtrace.tracer.configure(
https=False,
hostname="localhost",
port="9529",
)
prof = Profiler()
prof.start(True, True)
# your code here ...
while True:
print("hello world")
time.sleep(1)
You can see that python-profiling-manual is filtered out.
Scheck¶
Suppose we want to filter out log level warn, the configuration can be written as follows:
[io]
...
[io.filters]
security = [ # Filtering for Security
"{ category = 'system' AND level='warn' }"
]
After a while, you can see in the center that the log level warn is filtered out.
RUM¶
Warm Tip: If you install AdBlock advertising plugin, you may report interception to the center. You can temporarily close the AdBlock class plug-in while testing.
We can use three browsers, Chrome, Firefox and Safari, to access the website. Suppose we want to filter out the access of Chrome browser, and the configuration file can read as follows:
[io]
...
[io.filters]
rum = [ # Filtering for RUM
"{ app_id = 'appid_JtcMjz7Kzg5n8eifTjyU6w' AND browser='Chrome' }"
]
Configure Local Nginx¶
Configure the local test domain name /etc/hosts: 127.0.0.1 www.mac.my
Web file source index.html:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<script src="https://static.guance.com/browser-sdk/v2/dataflux-rum.js" type="text/javascript"></script>
<script>
window.DATAFLUX_RUM &&
window.DATAFLUX_RUM.init({
applicationId: 'appid_JtcMjz7Kzg5n8eifTjyU6w',
datakitOrigin: 'http://127.0.0.1:9529', // Protocol (including://), domain name (or IP address) [and port number]
env: 'production',
version: '1.0.0',
trackInteractions: true,
traceType: 'ddtrace', // It is not required and defaults to ddtrace. Currently, it supports 6 types: ddtrace, zipkin, skywalking_v3, jaeger, zipkin_single_header and w3c_traceparent
allowedTracingOrigins: ['http://www.mac.my:8080', 'http://www.mac.my', 'http://mac.my:8080', 'http://127.0.0.1:9529/'], // It is not required and allows all requests to be injected into the header header required by the trace collector. It can be the origin of the request or it can be regular
})
</script>
<body>
hello world!
</body>
</html>
Then, using the above three browsers, we can see that Chrome's access record has not increased.
KeyEvent¶
KeyEvent is tested in the form of an API. Suppose we want to filter out source for user, df_date_range for 10, and the configuration file is as follows:
[io]
...
[io.filters]
keyevent = [ # Filtering for KeyEvent
"{ source = 'user' AND df_date_range IN [ '10' ] }"
]
Then use curl to make a POST request:
curl --location --request POST 'http://localhost:9529/v1/write/keyevent' \
--header 'Content-Type: text/plain' \
--data-raw 'user create_time=1656383652424,df_date_range="10",df_event_id="event-21946fc19eaf4c5cb1a698f659bf74cd",df_message="【xxx】(xxx@xx.com)进入了工作空间",df_status="info",df_title="【xxx】(xxx@xx.com)进入了工作空间",df_user_id="acnt_a5d6130c19524a6b9fe91d421eaf8603",user_email="xxx@xx.com",user_name="xxx" 1658040035652416000'
curl --location --request POST 'http://localhost:9529/v1/write/keyevent' \
--header 'Content-Type: text/plain' \
--data-raw 'user create_time=1656383652424,df_date_range="9",df_event_id="event-21946fc19eaf4c5cb1a698f659bf74ca",df_message="【xxx】(xxx@xx.com)进入了工作空间",df_status="info",df_title="【xxx】(xxx@xx.com)进入了工作空间",df_user_id="acnt_a5d6130c19524a6b9fe91d421eaf8603",user_email="xxx@xx.com",user_name="xxx" 1658040035652416000'
You can see in the DataKit monitor that the df_date_range for 10 is filtered out.
Custom Object¶
The Custom Object is tested in the form of an API. Suppose we want to filter out class as aliyun_ecs, regionid as cn-qingdao, and the configuration file is as follows:
[io]
...
[io.filters]
custom_object = [ # 针对 CustomObject 过滤
"{ class='aliyun_ecs' AND regionid='cn-qingdao' }",
]
Then use curl to make a POST request:
curl --location --request POST 'http://localhost:9529/v1/write/custom_object' \
--header 'Content-Type: text/plain' \
--data-raw 'aliyun_ecs,name="ecs_name",host="ecs_host" instanceid="ecs_instanceid",os="ecs_os",status="ecs_status",creat_time="ecs_creat_time",publicip="1.1.1.1",regionid="cn-qingdao",privateip="192.168.1.12",cpu="ecs_cpu",memory=204800000000'
curl --location --request POST 'http://localhost:9529/v1/write/custom_object' \
--header 'Content-Type: text/plain' \
--data-raw 'aliyun_ecs,name="ecs_name",host="ecs_host" instanceid="ecs_instanceid",os="ecs_os",status="ecs_status",creat_time="ecs_creat_time",publicip="1.1.1.1",regionid="cn-qinghai",privateip="192.168.1.12",cpu="ecs_cpu",memory=204800000000'
You can see in the DataKit monitor that regionid for cn-qingdao is filtered out.
FAQ¶
View Synchronized Filters¶
For filters synchronized from the center, DataKit records a copy to data/.pull, which can be viewed directly.
$ cat .filters | jq
{
"dataways": null,
"filters": {
"logging": [
"{ source = 'datakit' and ( host in ['ubt-dev-01', 'tanb-ubt-dev-test'] )}"
]
},
"pull_interval": 10000000000,
"remote_pipelines": null
}
Here, the filters field in JSON is the filter that is pulled, and there is only a blacklist for logs at present.