从行协议切换到 Protobuf¶
行协议¶
由于历史原因,DataKit 内部使用 InfluxDB 的行协议作为基础数据结构,用来表示一个具体的数据点,它基本形式如下:
所谓行协议,就是用一行这样的文本来表示一个具体的数据点,比如如下数据点表示一个基本的磁盘使用情况:
disk,device=/dev/disk3s1s1,fstype=apfs free=167050518528i,total=494384795648i,used=327334277120i,used_percent=66.21042556354438 1685509141064064000
此处 disk 即指标集,device 和 fstype 是两个标签(tag),后面就是这个点上的一系列具体指标,最后一个大整数表示 Unix 时间戳,单位是纳秒。
此处几个以 i 结尾的数值表示这是一个有符号整数,上面这个数据点表示磁盘的具体使用情况。除了 i 之外,还支持
- 浮点(如这里的
used_percent,它不带类型后缀) - 无符号整数(后缀为
u) - 字符串
- 布尔
如果有多个数据点,则分行表示(故名行协议):
disk,device=/dev/disk3s1s1,fstype=apfs free=167050518528i,,total=494384795648i,used=327334277120i,used_percent=66.21042556354438 1685509141064064000
disk,device=/dev/disk3s6,fstype=apfs free=167050518528i,total=494384795648i,used=327334277120i,used_percent=66.21042556354438 1685509141064243000
disk,device=/dev/disk3s2,fstype=apfs free=167050518528i,total=494384795648i,used=327334277120i,used_percent=66.21042556354438 1685509141064254000
disk,device=/dev/disk3s4,fstype=apfs free=167050518528i,total=494384795648i,used=327334277120i,used_percent=66.21042556354438 1685509141064260000
行协议因为其可读性强,具备基本的数据表达功能,在使用初期,基本能满足我们的需求。
Protobuf¶
随着数据采集的不断深入,我们面临着两个问题:
- 行协议能表示的数据类型有点单一,比如它不支持数组类型的字段
在进程的采集中,我们需要采集进程打开的端口列表,这个只能通过字符串内嵌 JSON 来表示。而对于二进制数据,基本无法支持。
-
InfluxDB 官方的行协议 SDK 设计不当,且有一些性能问题:
- 数据点(Point)构建出来之后,对其做二次操作(比如 Pipeline),需要再次解开 Point,造成 CPU/内存浪费
- 编码/解码性能不佳,导致在高吞吐量情况下,数据处理受影响
基于上述原因,我们弃用了行协议这种数据结构(v1),进而采用完全自定义的数据结构(v2),然后采用 Protobuf 来传输。相比 v1 版本,v2 支持更多特性:
-
数据类型完全自定义,脱离了 InfluxDB 中对 Point 的约束,我们增加了数组/map/二进制等类型支持
- 有了二进制支持,我们能直接在 Point 中添加 binary 文件,比如在 profile 数据点中直接追加对应的 Profile 文件
- Protobuf 的 JSON 结构能直接用于 HTTP 请求,行协议没有提供对应的 JSON 形式,导致开发者只能被动熟悉行协议
-
构建出来的数据点,没有封包处理,仍然可以自由改动数据内容
- 编码体积上,由于行协议全是文本形式,gzip 压缩后,其体积稍微小一点(1MB 的 payload,差别在 0.1% 以内),Protobuf 在这方面也不弱。
- Protobuf 编码/解码效率更高,Benchmark 表明,编码效率大概 X10,解码效率大概 X5:
# 编码
BenchmarkEncode/bench-encode-lp
BenchmarkEncode/bench-encode-lp-10 250 4777819 ns/op 8674069 B/op 41042 allocs/op
BenchmarkEncode/bench-encode-pb
BenchmarkEncode/bench-encode-pb-10 2710 433151 ns/op 1115021 B/op 16 allocs/op
# 解码
BenchmarkDecode/decode-lp
BenchmarkDecode/decode-lp-10 72 15973900 ns/op 4670584 B/op 90286 allocs/op
BenchmarkDecode/decode-pb
BenchmarkDecode/decode-pb-10 393 3044680 ns/op 3052845 B/op 70025 allocs/op
基于上面 v2 在各方面的改进,我们在自己的可观测性方面做了一下基本测试,内存和 CPU 使用都有明显的改善:
在中低负载 DataKit 上,v2/v1 性能差异很明显:
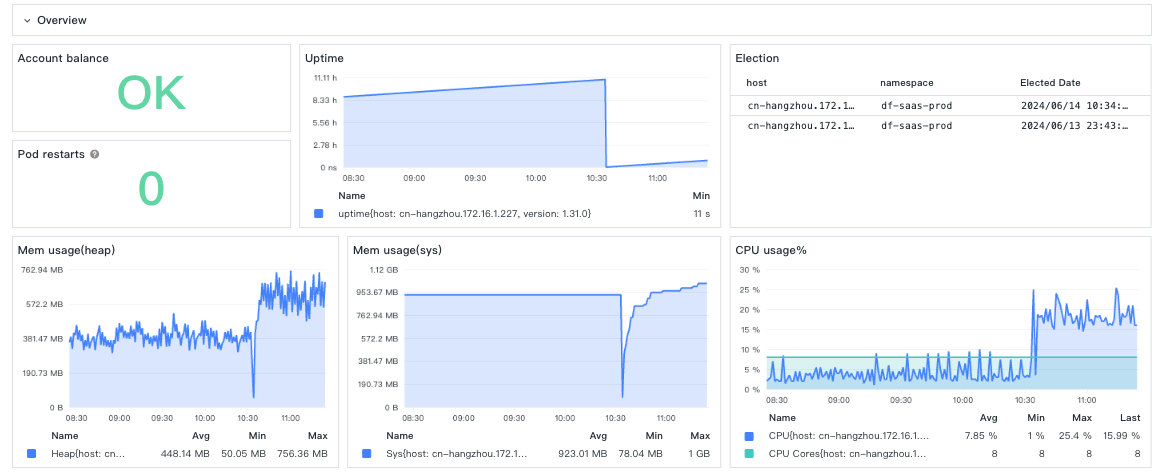
10:30 从 v2 切换到 v1,能看到 CPU/内存都有明显的上升。在在高负载 DataKit 上,性能差异也很明显:
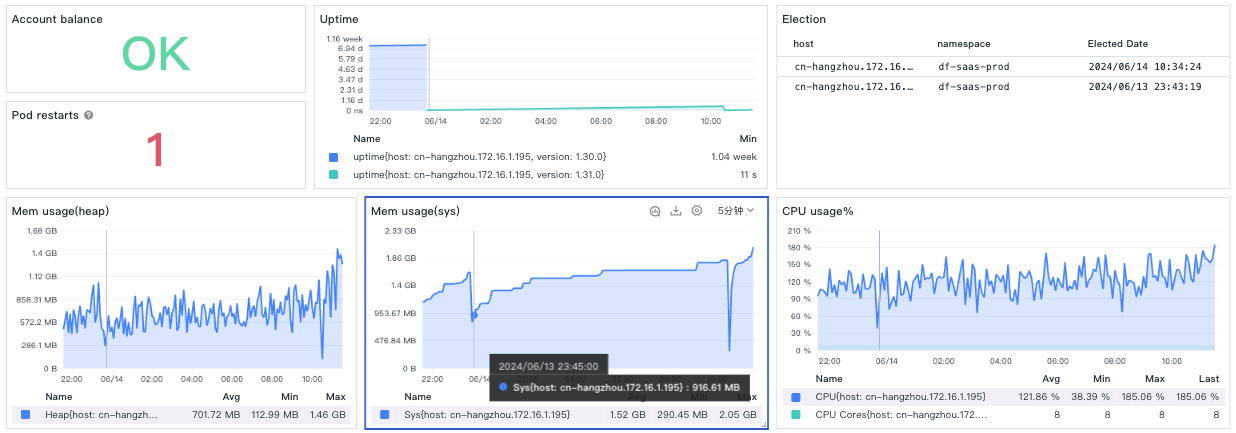
23:45 切换了 v2,此时 sys/heap mem 相比第二天 10:30 切换到 v1 要低很多。CPU 方面,10:30 切换到 v1 后,CPU 也有上升,但不是很明显,主要是因为高负载的 DataKit 主力 CPU 不在数据编码。
结论¶
v2 相比 v1 除了在性能方面提升显著,在拓展性方面也不在受限。同时 v2 也支持以 v1 的形式来编码,以兼容老的部署版本和开发习惯。在 DataKit 中,我们可以结合使用 point-pool 来实现更好的内存/CPU 表现。