Best Practices for Kafka Observability¶
Overview¶
Kafka is a distributed messaging queue based on the publish-subscribe model developed by LinkedIn. It is a real-time data processing system that can scale horizontally. Like RabbitMQ, RocketMQ, and other MIDDLEWARE, it has several key features:
- Asynchronous processing
- Service decoupling
- Traffic peak shaving
The following diagram illustrates an example of asynchronous processing.
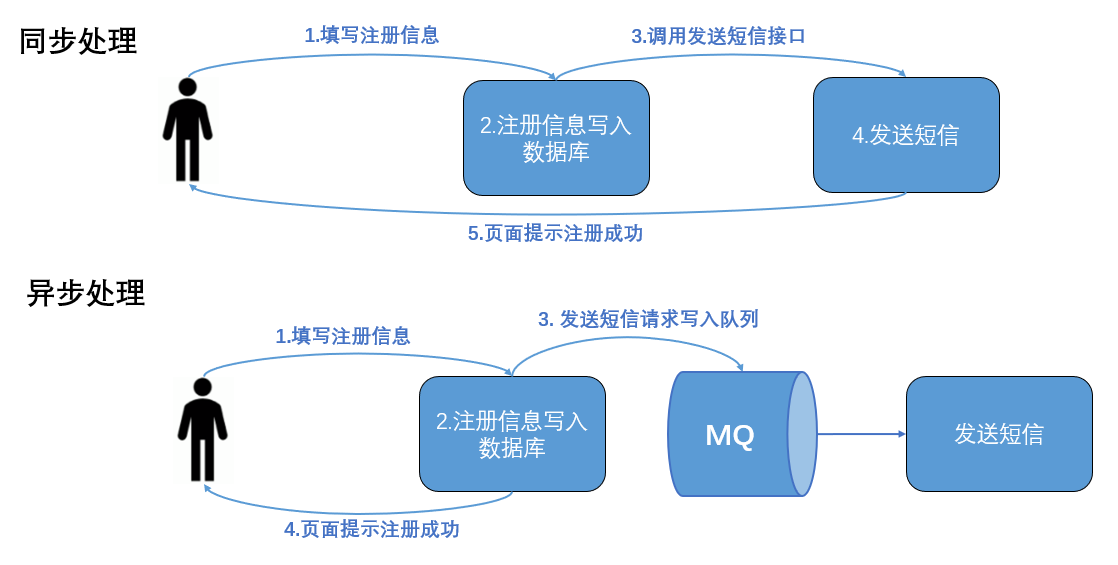
Architecture¶
As shown in the figure below, a Kafka architecture includes several Producers, several Consumers, several Brokers, and a Zookeeper cluster.
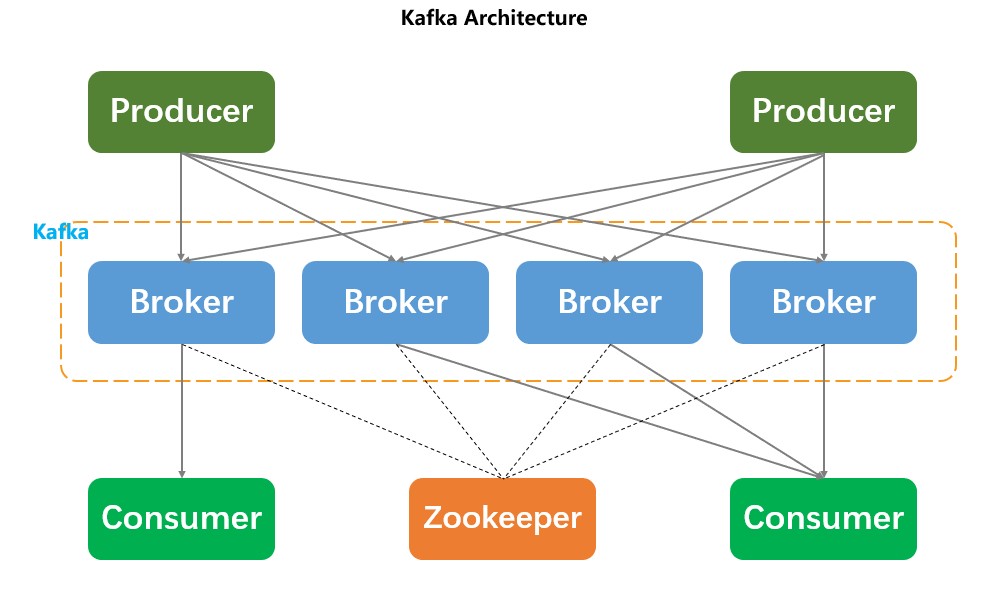
- Zookeeper: The Kafka cluster manages cluster configurations through Zookeeper. Leader election and Consumer Group changes trigger Rebalance.
- Broker: Message handling nodes in the middleware. A node is a Broker, and a Kafka cluster consists of one or more Brokers. A message can be distributed across multiple Brokers.
- Producer: Responsible for publishing messages to the Broker.
- Consumer: Reads messages from the Broker.
- Consumer Group: Each Consumer belongs to a specific Consumer Group, which can be named. If not specified, it defaults to a default Group. A message can be sent to multiple Groups, but only one Consumer within a Group can consume the message.
Kafka categorizes messages, and every message sent to the cluster must specify a Topic. A Topic represents a class of messages and is logically considered a Queue. Each message produced by the Producer must specify a Topic, then the Consumer will pull messages from the corresponding Broker based on the subscribed Topic. Each Topic contains one or more Partitions, with each Partition corresponding to a folder. This folder stores the data and index files of the Partition (partition). Each Partition internally maintains order. Thus, a Topic is divided into one or more Partitions, each of which has multiple replicas distributed across different Brokers. Among the multiple replicas of a partition, there is a relationship of one primary (Leader) and multiple secondary (Follower) replicas. The Leader provides external services, meaning interaction with client programs, while the Followers merely passively synchronize with the Leader and cannot interact with the outside world. The multi-replica mechanism achieves automatic fault transfer, ensuring service availability even when a Broker in the cluster fails, enhancing disaster recovery capabilities. As shown in the figure below, the Kafka cluster has 4 Brokers. A certain Topic has three partitions, assuming the replication factor is also set to 3, so each partition will have one Leader and two Follower replicas.

Partition replicas are located on different Brokers, and producers and consumers only interact with the Leader replica, while the Follower replicas are responsible for message synchronization. When the Leader replica fails, a new Leader replica is elected from the Follower replicas to provide external services.
Below are some important terms in Kafka's multi-replica mechanism.
- AR (Assigned Replicas): All replicas in a partition are collectively referred to as AR.
- ISR (In-Sync Replicas): The Leader replica and all Followers that maintain a certain level of synchronization (including the Leader itself) form the ISR.
- OSR (Out-of-Sync Replicas): All Followers that do not maintain a certain level of synchronization with the Leader replica form the OSR.
First, the producer sends messages to the Leader replica, then the Follower replicas pull messages from the Leader to synchronize. At any given moment, the messages in all replicas are not entirely identical, meaning that during synchronization, the Follower may lag behind the Leader to some extent. Thus, the relationship between the three can be seen: AR = ISR + OSR.
The Leader is responsible for maintaining and tracking the lag state of all Follower replicas in the ISR set. When a Follower lags too much or fails, the Leader will remove it from the ISR set. Of course, if a Follower in the OSR set catches up with the Leader, the Leader will move it from the OSR set to the ISR set. Normally, when the Leader fails, only Followers in the ISR set are eligible to be elected as the new Leader, while Followers in the OSR set do not have this opportunity (though this can be changed by modifying parameters).
Key Metrics for Monitoring Kafka¶
Next, we introduce detailed information about Kafka metrics.
UnderReplicatedPartitions¶
UnderReplicatedPartitions indicates the number of partitions in an unsynchronized state, i.e., the number of partitions with failed replicas, where abnormal values are non-zero. In a well-functioning cluster, the number of synchronized replicas (ISR) should completely equal the total number of replicas. A non-zero value indicates the number of partitions on a Broker whose Leader does not have fully synchronized and caught-up replicas. Possible issues include:
- A Broker going down.
- Disk failure/full disk for the replica, causing the replica to go offline, which can be judged by combining it with a non-zero OfflineLogDirectoryCount metric.
- Performance issues leading to inability to synchronize replicas. There could be two scenarios: first, the Follower replica process gets stuck, failing to initiate synchronization requests with the Leader for a period of time, such as frequent Full GC; second, the Follower replica process synchronizes too slowly to catch up with the Leader replica within a period of time, such as excessive I/O overhead.
| Measurement | kafka_replica_manager | |
|---|---|---|
| Metrics | Description | Data Type |
| UnderReplicatedPartitions | Number of Partitions in an unsynchronized state | int |
| UnderMinIsrPartitionCount | Number of Partitions below the minimum ISR. | int |
OfflineLogDirectoryCount¶
OfflineLogDirectoryCount indicates the number of offline log directories, where abnormal values are non-zero. This metric needs to be monitored to check for any dismounted log directories.
| Measurement | kafka_log | |
|---|---|---|
| Metrics | Description | Data Type |
| OfflineLogDirectoryCount | Number of offline log directories | int |
IsrShrinksPerSec / IsrExpandsPerSec¶
The number of replicas in sync (ISR) for any partition should remain stable unless you are expanding Broker nodes or deleting partitions. To ensure high availability, the Kafka cluster must guarantee a minimum number of ISRs to prevent Followers from taking over when a partition's Leader goes down. Reasons for removing a replica from the ISR pool include: the Follower's offset lagging far behind the Leader (changing the replica.lag.max.messages configuration item), or a Follower losing contact with the Leader for a period of time (changing the replica.socket.timeout.ms configuration item). Regardless of the reason, if IsrShrinksPerSec (ISR shrinkage) increases without a subsequent increase in IsrExpandsPerSec (ISR expansion), attention should be paid and manual intervention required.
| Measurement | kafka_replica_manager | |
|---|---|---|
| Metrics | Description | Data Type |
| IsrShrinksPerSec.Count | Number of ISR reductions | int |
| IsrShrinksPerSec.OneMinuteRate | Frequency of ISR reductions | float |
| IsrExpandsPerSec.Count | Number of ISR expansions | int |
| IsrExpandsPerSec.OneMinuteRate | Frequency of ISR expansions | float |
ActiveControllerCount¶
ActiveControllerCount indicates the number of controllers currently in an active state, where abnormal values are 0. The first node started in the Kafka cluster automatically becomes the Controller, and there can only be one such node. Normally, this metric should be 1 on the Broker where the Controller resides, and 0 on other Brokers. The Controller's responsibility is to maintain the list of partition Leaders and coordinate Leader changes when a Leader becomes unavailable. If necessary, a new Controller will be randomly selected from the Broker pool by Zookeeper. Typically, this value should never exceed 1, but when this value equals 0 and persists for a period (<1), a clear warning must be issued, so this metric can be used for alerting.
| Measurement | kafka_controller | |
|---|---|---|
| Metrics | Description | Data Type |
| ActiveControllerCount.Value | Number of live Controllers | int |
OfflinePartitionsCount¶
OfflinePartitionsCount indicates the number of partitions without an active Leader, where abnormal values are non-zero. Since all read/write operations occur only on the Partition Leader, any partition without an active Leader will become completely unavailable, and both consumers and producers on that partition will be blocked until the Leader becomes available. This metric can be used for alerting.
| Measurement | kafka_controller | |
|---|---|---|
| Metrics | Description | Data Type |
| OfflinePartitionsCount.Value | Number of offline Partitions | int |
LeaderElectionRateAndTimeMs¶
When a Partition Leader fails, a new Leader election is triggered. Through LeaderElectionRateAndTimeMs, you can monitor how many times per second the Leader elections occur, indicating the frequency of elections.
| Measurement | kafka_controller | |
|---|---|---|
| Metrics | Description | Data Type |
| LeaderElectionRateAndTimeMs.Count | Number of Leader elections | int |
| LeaderElectionRateAndTimeMs.OneMinuteRate | Leader election rate | float |
| LeaderElectionRateAndTimeMs.50thPercentile | Leader election rate | float |
| LeaderElectionRateAndTimeMs.75thPercentile | Leader election rate | float |
| LeaderElectionRateAndTimeMs.99thPercentile | Leader election rate | float |
UncleanLeaderElectionsPerSec¶
When Kafka Brokers' partition Leaders are unavailable, unclean Leader elections occur, selecting a new Leader from the ISR set of that partition. Essentially, unclean leader elections sacrifice consistency for availability. If there are no available replicas in sync, Leader elections must occur among replicas not in sync, meaning all messages from the previous Leader that were not synchronized will be lost forever. An abnormal value for UncleanLeaderElectionsPerSec.Count is not equal to 0, indicating data loss, and therefore requires alerting.
| Measurement | kafka_controller | |
|---|---|---|
| Metrics | Description | Data Type |
| UncleanLeaderElectionsPerSec.Count | Number of Unclean Leader elections | int |
TotalTimeMs¶
TotalTimeMs is itself the sum of four metrics:
- queue: Time spent waiting in the request queue
- local: Time spent processing by the leader
- remote: Time spent waiting for follower responses (only when requests.required.acks=-1)
- response: Time spent sending replies
TotalTimeMs measures server request duration. Normally, this metric remains stable with only minor fluctuations. If anomalies are detected, irregular data fluctuations will appear. At this point, check the values of queue, local, remote, and response to determine which segment is causing the delay.
| Measurement | kafka_request | |
|---|---|---|
| Metrics | Description | Data Type |
| TotalTimeMs.Count | Total request duration | int |
PurgatorySize¶
PurgatorySize: A temporary storage area where produce and fetch requests wait until they are needed. Monitoring the size of purgatory helps identify the root cause of latency. For example, if the number of fetch requests in the purgatory queue increases accordingly, it can easily explain the increase in consumer fetch time.
| Measurement | kafka_purgatory | |
|---|---|---|
| Metrics | Description | Data Type |
| Fetch.PurgatorySize | Size of Fetch Purgatory | int |
| Produce.PurgatorySize | Size of Produce Purgatory | int |
| Rebalance.PurgatorySize | Size of Rebalance Purgatory | int |
| topic.PurgatorySize | Size of topic Purgatory | int |
| ElectLeader.PurgatorySize | Size of Leader Election Purgatory | int |
| DeleteRecords.PurgatorySize | Size of Delete Records Purgatory | int |
| DeleteRecords.NumDelayedOperations | Number of delayed delete records | int |
| Heartbeat.NumDelayedOperations | Heartbeat monitoring | int |
BytesInPerSec / BytesOutPerSec¶
BytesInPerSec/BytesOutPerSec measure incoming/outgoing bytes. Typically, disk throughput and network throughput can both become bottlenecks. If you are sending messages across data centers, have numerous Topics, or replicas are catching up with the Leader, network throughput may affect Kafka's performance. These metrics help track network throughput on Brokers to identify where the bottleneck lies.
| Measurement | kafka_topics | |
|---|---|---|
| Metrics | Description | Data Type |
| BytesInPerSec.Count | Number of bytes flowing in per second | int |
| BytesInPerSec.OneMinuteRate | Flow rate per second | float |
| BytesOutPerSec.Count | Number of bytes flowing out per second | int |
| BytesOutPerSec.OneMinuteRate | Outflow rate per second | float |
RequestsPerSec¶
RequestsPerSec measures the number of requests per second. By monitoring this metric, you can keep real-time tabs on the request rates of producers and consumers to ensure efficient Kafka communication. If this metric remains consistently high, consider increasing the number of producers or consumers to improve throughput and reduce unnecessary network overhead.
| Measurement | kafka_topics | |
|---|---|---|
| Metrics | Description | Data Type |
| TotalFetchRequestsPerSec.Count | Number of fetch requests per second | int |
| TotalProduceRequestsPerSec.Count | Number of write requests by producers per second | int |
| FailedFetchRequestsPerSec.Count | Number of failed Topic Fetches | int |
| FailedProduceRequestsPerSec.Count | Rate of failed send requests | int |
Other Common Metrics¶
| Measurement | kafka_controller | |
|---|---|---|
| Metrics | Description | Data Type |
| GlobalTopicCount.Value | Total number of Topics in the cluster | int |
| GlobalPartitionCount.Value | Number of Partitions | int |
| TotalQueueSize.Value | Total number of queues | int |
| EventQueueSize.Value | Number of event queues | int |
| Measurement | kafka_request | |
|---|---|---|
| Metrics | Description | Data Type |
| RequestQueueTimeMs.Count | Request queue time | int |
| ResponseSendTimeMs.Count | Response queue time | int |
| MessageConversionsTimeMs.Count | Message conversion time | int |
| Measurement | kafka_topics | |
|---|---|---|
| Metrics | Description | Data Type |
| PartitionCount.Value | Number of Partitions | int |
| LeaderCount.Value | Number of Leaders | int |
| BytesRejectedPerSec.Count | Number of rejected Topic requests | int |
Scenario Views¶
Before starting to use Guance to observe Kafka, you need to first register for a Guance account. After completing registration, log in to the Guance workspace. Then follow the <Kafka Integration Documentation> to implement Kafka observability.
