数据点规则策略¶
本文档主要描述 DataKit Filter 基本使用以及注意事项。
简介¶
DataKit Filter 用于对采集到的数据点进行筛选,用于过滤掉一些不想要的数据,或者基于这些数据点的特征,制定对应的规则策略。它的功能跟 Pipeline 有一点类似,但有所区别:
| 数据处理组件 | 支持本地配置 | 支持中心下发 | 支持数据丢弃 | 支持数据改写 | 使用方法 |
|---|---|---|---|---|---|
| Pipeline | 通过在采集器中配置 Pipeline 或者在观测云 Studio 编写 Pipeline | ||||
| Filter | 在观测云 Studio 编写 Pipeline 或者在 datakit.conf 中配置 filter |
从表中可以看出,相比 Pipeline,如果只是简单的过滤掉部分数据,那么 Filter 是一种更便捷的数据筛选工具。
Filter 具体使用方法¶
Filter 的主要功能就是数据筛选,其筛选依据是通过一定的筛选条件,对采集到的数据进行判定,符合筛选条件的数据,将被丢弃。
过滤器的基本语法模式为:
其中 conditions 又可以是其它各种条件的组合。以下是一些过滤器示例:
# 这条一般针对日志数据,用于判定所有日志类型,将其中符合条件的 key1/key2 过滤掉
# 注意,这里的 key1 和 key2 均为数据点字段中的 tag 或 field
{ source = re('.*') AND ( key1 = "abc" OR key2 = "def") }
# 这条一般针对 Tracing 数据,用于名为 app1 的 service,将其中符合条件的 key1/key2 过滤掉
{ service = "app-1" AND ( key1 = "abc" OR key2 = "def") }
过滤器操作的数据范围¶
由于 DataKit 采集到的(绝大部分)数据均以数据点方式上报,故所有过滤器均工作于数据点之上。过滤器支持在如下数据上做数据筛选:
-
指标集名称:对于不同类型的数据,指标集的业务归属有所不同,分别如下:
- 对时序数据(M)而言,在过滤器运行的时候,会在其 tag 列表中注入一个
measurement的 tag,故可以这样来写基于指标集的过滤器:{measurement = re('abc.*') AND ( tag1='def' and field2 = 3.14)} - 对对象数据(O)而言,在过滤器运行的时候,会在其 tag 列表中注入一个
class的 tag,故可以这样来写基于对象的过滤器:{class = re('abc.*') AND ( tag1='def' and field2 = 3.14)} - 对日志数据(L)而言,在过滤器运行的时候,会在其 tag 列表中注入一个
source的 tag,故可以这样来写基于对象的过滤器:{source = re('abc.*') AND ( tag1='def' and field2 = 3.14)}
- 对时序数据(M)而言,在过滤器运行的时候,会在其 tag 列表中注入一个
注意:如果原来 tag 中就存在一个名为
measurement/class/source的 tag,那么在过滤器运行过程中,原来的 measurement/class/source 这些 tag 值将不存在
- Tag(标签):对所有的数据类型,均可以在其 Tag 上执行过滤。
- Field(指标):对所有的数据类型,均可以在其 Field 上执行过滤。
Note
在 RUM 数据中,可能会在 Tracing 数据上触发一个 root span,该 root span 是在中心生成的,其目的是避免由 RUM 触发的链路数据缺少 root span 而凭空创建的一个 span(保持链路的完整性)。由于该 span 不经过 DataKit,故其无法通过过滤器来丢弃。同理,该数据也无法进行 Pipeline 处理。
DataKit 中手动配置 filter¶
在 datakt.conf 中,可手动配置黑名单过滤,示例如下:
[io]
[io.Filters]
logging = [ # 针对日志数据的过滤
"{ source = 'datakit' or f1 IN [ 1, 2, 3] }"
]
metric = [ # 针对指标的过滤
"{ measurement IN ['datakit', 'disk'] }",
"{ measurement MATCH ['host.*', 'swap'] }",
]
object = [ # 针对对象过滤
"{ class MATCH ['host_.*'] }",
]
tracing = [ # 针对 tracing 过滤
"{ service = re("abc.*") AND some_tag MATCH ['def_.*'] }",
]
network = [ # 针对 Network 过滤
"{ source = 'netflow' or f1 IN [ 1, 2, 3] }"
]
keyevent = [ # 针对 KeyEvent 过滤
"{ source = 'datakit' or f1 IN [ 1, 2, 3] }"
]
custom_object = [ # 针对 CustomObject 过滤
"{ class MATCH ['host_.*'] }",
]
rum = [ # 针对 RUM 过滤
"{ source = 'resource' or app_id = 'appid_xxx' or f1 IN [ 1, 2, 3] }"
]
security = [ # 针对 Security 过滤
"{ category = 'datakit' or f1 IN [ 1, 2, 3] }"
]
profiling = [ # 针对 Profiling 过滤
"{ service = re("abc.*") AND some_tag MATCH ['def_.*'] }",
]
Warning
过滤器只适用于调试,日常使用的话,还是建议大家使用黑名单的网页模式。一旦 datakit.conf 中配置了过滤器,那么则以该过滤器为准,观测云 Studio 配置的黑名单将不再生效。
另外,黑名单功能在未来将被下线,最好的数据过滤方式还是通过 Pipeline 的 drop() 函数实现。
这里的配置需遵循如下规则:
- 具体的一组过滤器,必须指定它所过滤的数据类型
- 同一个数据类型,不要配置多个入口(即配置了多组 logging 过滤器),否则 datakit.conf 会解析报错,导致 DataKit 无法启动
- 单个数据类型下,能配置多个过滤器(如上例中的 metric)
- 对于语法错误的过滤器,DataKit 默认忽略,它将不生效,但不影响 DataKit 其它功能
过滤器基本语法规则¶
基本语法规则¶
过滤器基本语法规则,跟 Pipeline 基本一致,参见这里。
操作符¶
支持基本的数值比较操作:
-
判断相等
=!=
-
判断数值大小
>>=<<=
-
括号表达式:用于任意关系之间的逻辑组合,如
-
内置常量
true/falsenil/null: 空值,见下文说明
-
匹配和列表操作
| 操作符 | 支持数值类型 | 说明 | 示例 |
|---|---|---|---|
IN, NOTIN |
数值列表列表 | 指定的字段是否在列表中,列表中支持多类型混杂 | { abc IN [1,2, "foo", 3.5]} |
MATCH, NOTMATCH |
正则表达式列表 | 指定的字段是否匹配列表中的正则,该列表只支持字符串类型 | { abc MATCH ["foo.*", "bar.*"]} |
Note
- 列表中只能出现普通的数据类型,如字符串、整数、浮点,其它表达式均不支持。
IN/NOTIN/MATCH/NOTMATCH 这些关键字大小写不敏感,即 in 和 IN 以及 In 效果是一样的。除此之外,其它操作数的大小写都是敏感的,比如如下几个过滤器表达的意思不同:
{ abc IN [1,2, "foo", 3.5]} # 字段 abc(tag 或 field)是否在列表中
{ abc IN [1,2, "FOO", 3.5]} # FOO 并不等价于 foo
{ ABC IN [1,2, "foo", 3.5]} # ABC 和 abe 也不等价
在数据点中,所有字段以及其值都是大小写敏感的。
- 恒等/恒不等表达式写法:
nil/null 用法¶
nil/null 用于表示某些字段不存在,我们可以在 =/!=/IN/NOTIN 操作中使用:
{ some_tag_or_field != nil } # 某个字段存在
{ some_tag_or_field = nil } # 某个字段不存在
{ some_tag_or_field IN ["abc", "123", null] } # 某个字段要么不存在,要么只能等于指定的值
{ some_tag_or_field NOTIN ["abc", "123", null] } # 某个字段不为 null 且不为指定的值
此处 nil/null 不区分大小写,我们可以写成 NULL/Null/NIL/Nil 等多种形式。
用法示例¶
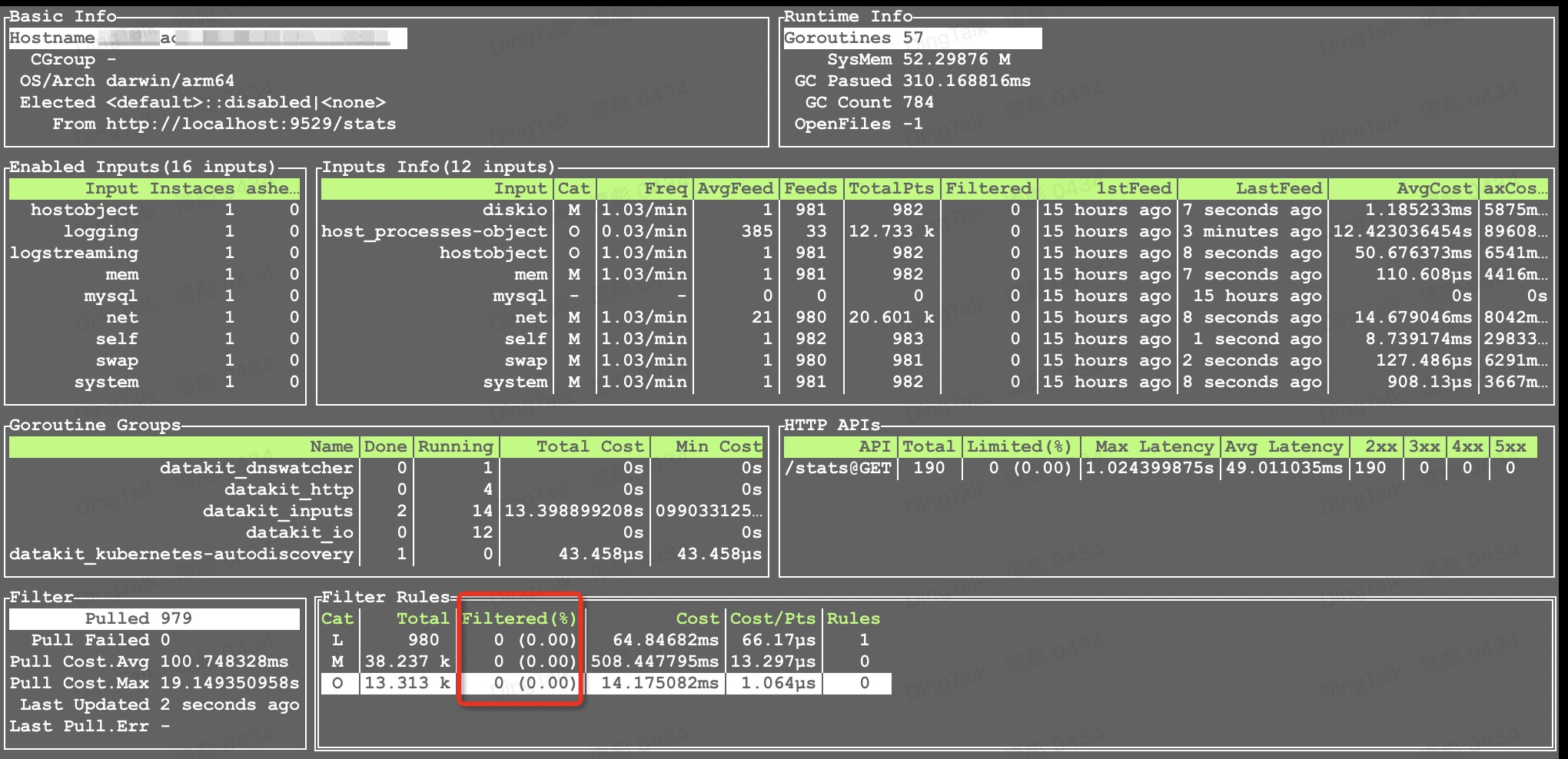
使用 datakit monitor -V 命令可以查看过滤情况:
Network¶
需要开启 eBPF 采集器。假设我们要过滤掉目标端口为 443 的网络通讯,配置文件可以这样写:
[io]
...
[io.filters]
network = [ # 针对 Network 过滤
"{ source = 'netflow' and dst_port IN [ '443' ] }"
]
用 curl 命令触发网络通讯 curl https://www.baidu.com:443,可以看到目标端口为 443 的网络通讯被过滤掉了。
Profiling¶
配置文件如下:
开 2 个 Profiling:
DD_ENV=testing DD_SERVICE=python-profiling-manual DD_VERSION=7.8.9 python3 profiling_test.py
DD_ENV=testing DD_SERVICE=2-profiling-python DD_VERSION=7.8.9 python3 profiling_test.py
python 源码文件 profiling_test.py:
import time
import ddtrace
from ddtrace.profiling import Profiler
ddtrace.tracer.configure(
https=False,
hostname="localhost",
port="9529",
)
prof = Profiler()
prof.start(True, True)
# your code here ...
while True:
print("hello world")
time.sleep(1)
可以看到 python-profiling-manual 被过滤掉了。
Scheck 安全巡检¶
假设我们要过滤掉 log level 为 warn 的,配置可以这样写:
过段时间可以在中心看到 log level 为 warn 的被过滤掉了。
RUM¶
温馨提示:如果你安装了 AdBlock 类广告插件可能会对中心汇报拦截。你可以在测试的时候临时关闭 AdBlock 类插件。
我们这里可以用三种浏览器 Chrome、Firefox、Safari 访问网站,假设我们要过滤掉 Chrome 浏览器的访问,配置文件可以这样写:
[io]
...
[io.filters]
rum = [ # 针对 RUM 过滤
"{ app_id = 'appid_JtcMjz7Kzg5n8eifTjyU6w' AND browser='Chrome' }"
]
配置本地 nginx¶
配置本地测试域名 /etc/hosts: 127.0.0.1 www.mac.my
网页文件源码 index.html:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<script src="https://static.guance.com/browser-sdk/v2/dataflux-rum.js" type="text/javascript"></script>
<script>
window.DATAFLUX_RUM &&
window.DATAFLUX_RUM.init({
applicationId: 'appid_JtcMjz7Kzg5n8eifTjyU6w',
datakitOrigin: 'http://127.0.0.1:9529', // 协议(包括://),域名(或 IP 地址)[和端口号]
env: 'production',
version: '1.0.0',
trackInteractions: true,
traceType: 'ddtrace', // 非必填,默认为 ddtrace,目前支持 ddtrace、zipkin、skywalking_v3、jaeger、zipkin_single_header、w3c_traceparent 6 种类型
allowedTracingOrigins: ['http://www.mac.my:8080', 'http://www.mac.my', 'http://mac.my:8080', 'http://127.0.0.1:9529/'], // 非必填,允许注入 trace 采集器所需 header 头部的所有请求列表。可以是请求的 origin,也可以是是正则
})
</script>
<body>
hello world!
</body>
</html>
随后,我们使用以上三种浏览器访问,可以看到 Chrome 的访问记录没有增加。
KeyEvent¶
KeyEvent 通过 API 形式来进行测试。假设我们要过滤掉 source 为 user,df_date_range 为 10,配置文件如下:
[io]
...
[io.filters]
keyevent = [ # 针对 KeyEvent 过滤
"{ source = 'user' AND df_date_range IN [ '10' ] }"
]
然后使用 curl 进行 POST 请求:
curl --location --request POST 'http://localhost:9529/v1/write/keyevent' \
--header 'Content-Type: text/plain' \
--data-raw 'user create_time=1656383652424,df_date_range="10",df_event_id="event-21946fc19eaf4c5cb1a698f659bf74cd",df_message="【xxx】(xxx@xx.com)进入了工作空间",df_status="info",df_title="【xxx】(xxx@xx.com)进入了工作空间",df_user_id="acnt_a5d6130c19524a6b9fe91d421eaf8603",user_email="xxx@xx.com",user_name="xxx" 1658040035652416000'
curl --location --request POST 'http://localhost:9529/v1/write/keyevent' \
--header 'Content-Type: text/plain' \
--data-raw 'user create_time=1656383652424,df_date_range="9",df_event_id="event-21946fc19eaf4c5cb1a698f659bf74ca",df_message="【xxx】(xxx@xx.com)进入了工作空间",df_status="info",df_title="【xxx】(xxx@xx.com)进入了工作空间",df_user_id="acnt_a5d6130c19524a6b9fe91d421eaf8603",user_email="xxx@xx.com",user_name="xxx" 1658040035652416000'
可以在 DataKit monitor 里面看到 df_date_range 为 10 的被过滤掉了。
Custom Object¶
Custom Object 通过 API 形式来进行测试。假设我们要过滤掉 class 为 aliyun_ecs,regionid 为 cn-qingdao,配置文件如下:
[io]
...
[io.filters]
custom_object = [ # 针对 CustomObject 过滤
"{ class='aliyun_ecs' AND regionid='cn-qingdao' }",
]
然后使用 curl 进行 POST 请求:
curl --location --request POST 'http://localhost:9529/v1/write/custom_object' \
--header 'Content-Type: text/plain' \
--data-raw 'aliyun_ecs,name="ecs_name",host="ecs_host" instanceid="ecs_instanceid",os="ecs_os",status="ecs_status",creat_time="ecs_creat_time",publicip="1.1.1.1",regionid="cn-qingdao",privateip="192.168.1.12",cpu="ecs_cpu",memory=204800000000'
curl --location --request POST 'http://localhost:9529/v1/write/custom_object' \
--header 'Content-Type: text/plain' \
--data-raw 'aliyun_ecs,name="ecs_name",host="ecs_host" instanceid="ecs_instanceid",os="ecs_os",status="ecs_status",creat_time="ecs_creat_time",publicip="1.1.1.1",regionid="cn-qinghai",privateip="192.168.1.12",cpu="ecs_cpu",memory=204800000000'
可以在 DataKit monitor 里面看到 regionid 为 cn-qingdao 的被过滤掉了。
FAQ¶
查看同步下来的过滤器¶
对于从中心同步下来的过滤器,DataKit 记录了一份到 [DataKit 安装目录]/data/.pull 中,可直接查看
$ cat .filters | jq
{
"dataways": null,
"filters": {
"logging": [
"{ source = 'datakit' and ( host in ['ubt-dev-01', 'tanb-ubt-dev-test'] )}"
]
},
"pull_interval": 10000000000,
"remote_pipelines": null
}
这里 JSON 中的 filters 字段就是拉取到的过滤器,目前里面只有针对日志的黑名单。