JAVA 应用 RUM-APM-LOG 联动分析¶
应用场景介绍¶
企业最重要的营收来源即是业务,而现当下,绝大多数企业的业务都是由对应的 IT 系统承载的,那如何保障企业的业务稳健,归根到企业内部就是如何保障企业内部的 IT 系统。当业务系统出现异常或故障时,往往是业务、应用开发、运维等多方面同事一起协调进行问题的排查,存在跨平台、跨部门、跨专业领域等多种问题,排查既耗时、又费力。
为了解决这一问题,目前业界已经比较成熟的方式,即在基础设施监控之外,对应用层、日志层进行深度监控,通过 RUM+APM+LOG 实现对整个业务系统最核心的前后端应用、日志统一管理,能力强一些的监控还可以将这三方面数据通过关键字段进行打通,实现联动分析,从而提升相关工作人员的工作效率,保障系统平稳运行。
- APM : Application Performance Monitoring 应用性能监控
- RUM : Real User Moitoring 真实用户体验监控
- LOG : 日志
目前观测云已具备这样的能力,本文以若依办公系统作为演示 demo ,将从如何接入 RUM+APM+LOG 这三方监控,以及如何利用观测云进行联动分析的角度进行阐述。
安装 DataKit¶
1 复制安装指令¶
注册并登录观测云,选择「集成」 - 「DataKit」,选择适合自己环境的安装指令,复制。
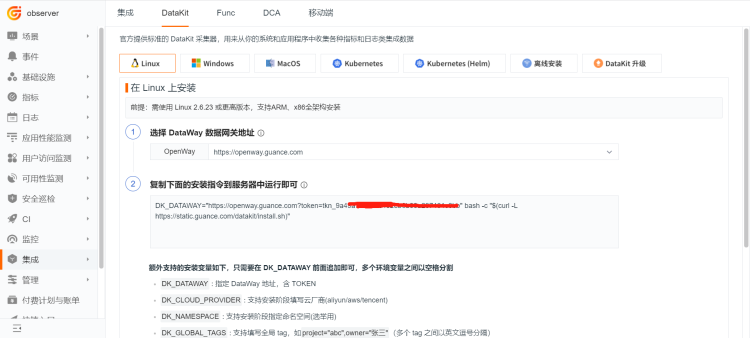
2 在服务器上安装 DataKit¶

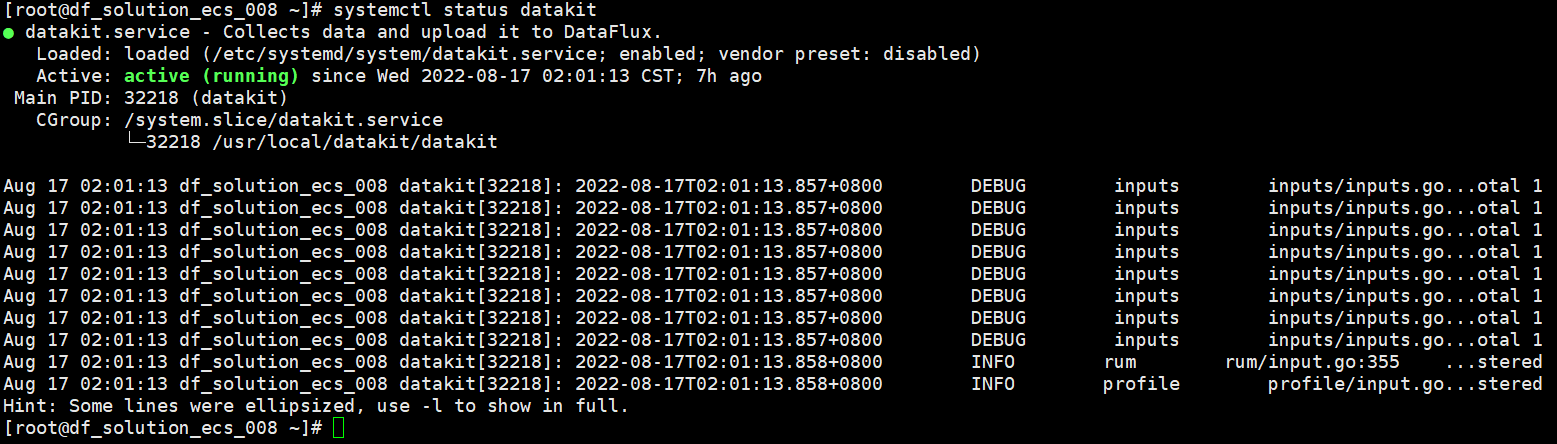
3 查询 DataKit 状态¶
执行命令 systemctl status datakit
4 查看数据¶
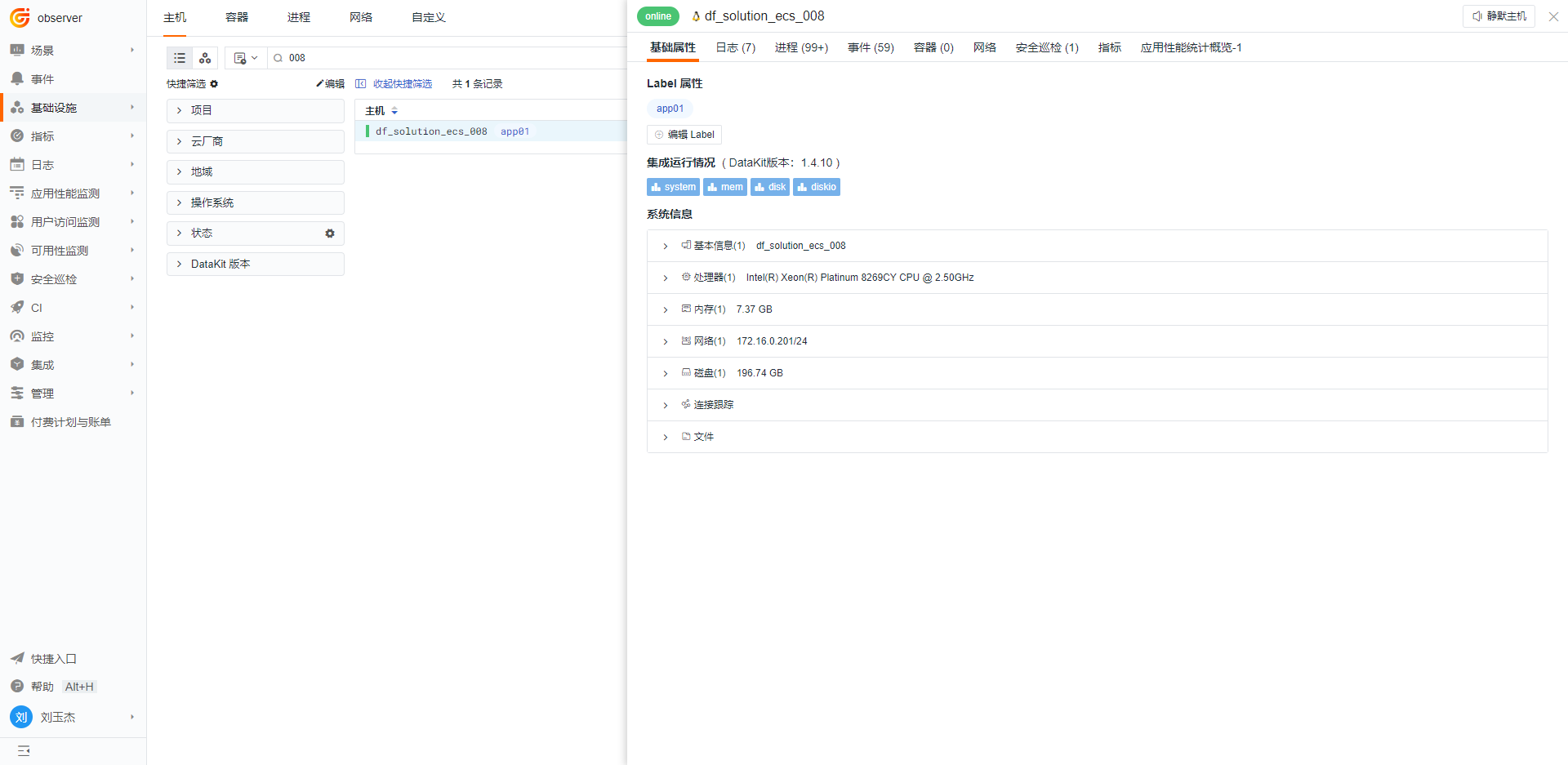
Datakit 安装好后,默认会对如下内容进行采集,可直接在 「观测云」 - 「基础设施」 - 「主机」查看相关数据
| 采集器名称 | 说明 |
|---|---|
| cpu | 采集主机的 CPU 使用情况 |
| disk | 采集磁盘占用情况 |
| diskio | 采集主机的磁盘 IO 情况 |
| mem | 采集主机的内存使用情况 |
| swap | 采集 Swap 内存使用情况 |
| system | 采集主机操作系统负载 |
| net | 采集主机网络流量情况 |
| host_process | 采集主机上常驻 (存活 10min 以上)进程列表 |
| hostobject | 采集主机基础信息 (如操作系统信息、硬件信息等) |
| docker | 采集主机上可能的容器对象以及容器日志 |
选择不同的集成 inputs 名称,就可以查看对应的监控视图,监控视图下方还可以查看其它数据,例如日志、进程、容器等信息。
RUM¶
详细步骤参见文档 web 应用监控(RUM)最佳实践
1 复制 JS 代码¶
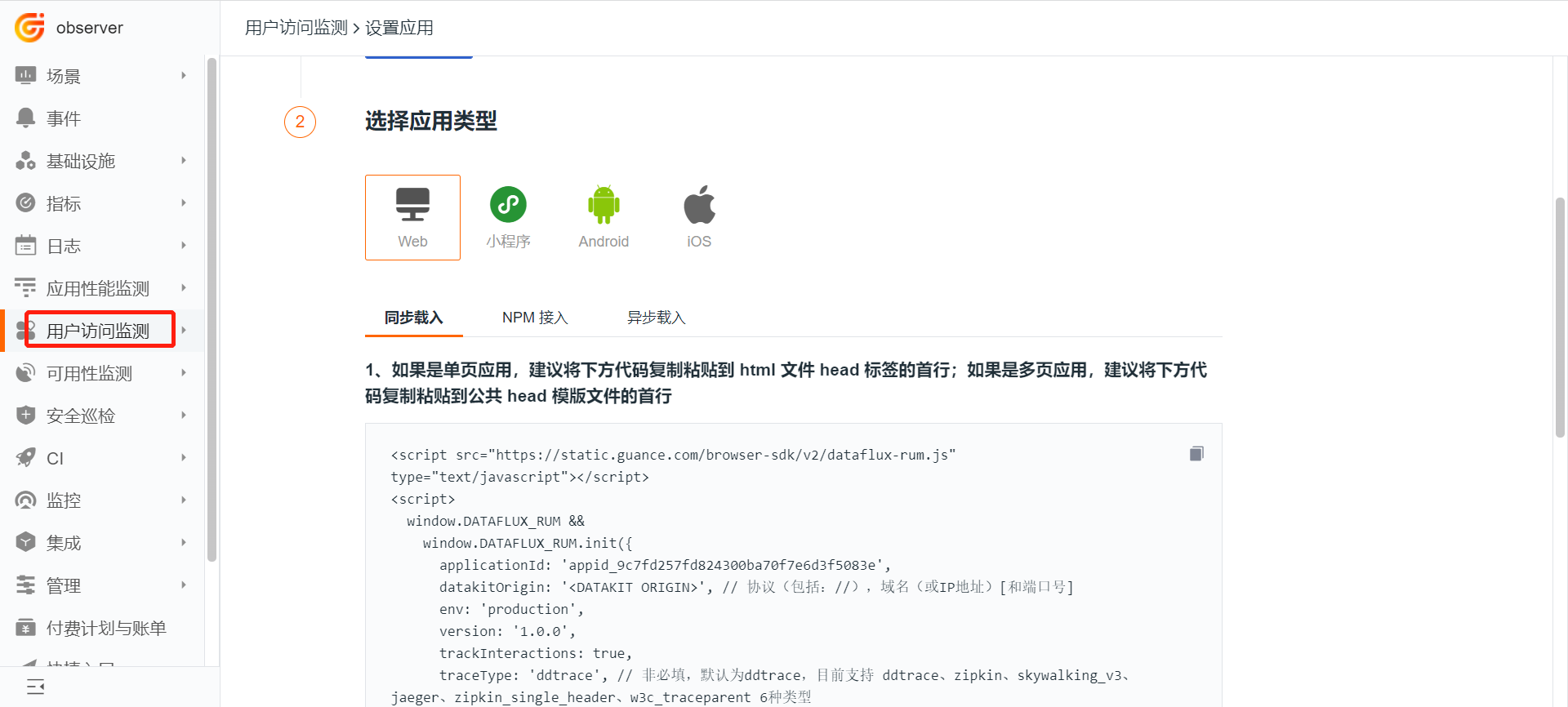
登录观测云,选择「用户访问监测」 - 「新建应用」 - 「Web」- 载入类型选择「同步载入」
2 嵌入 JS¶
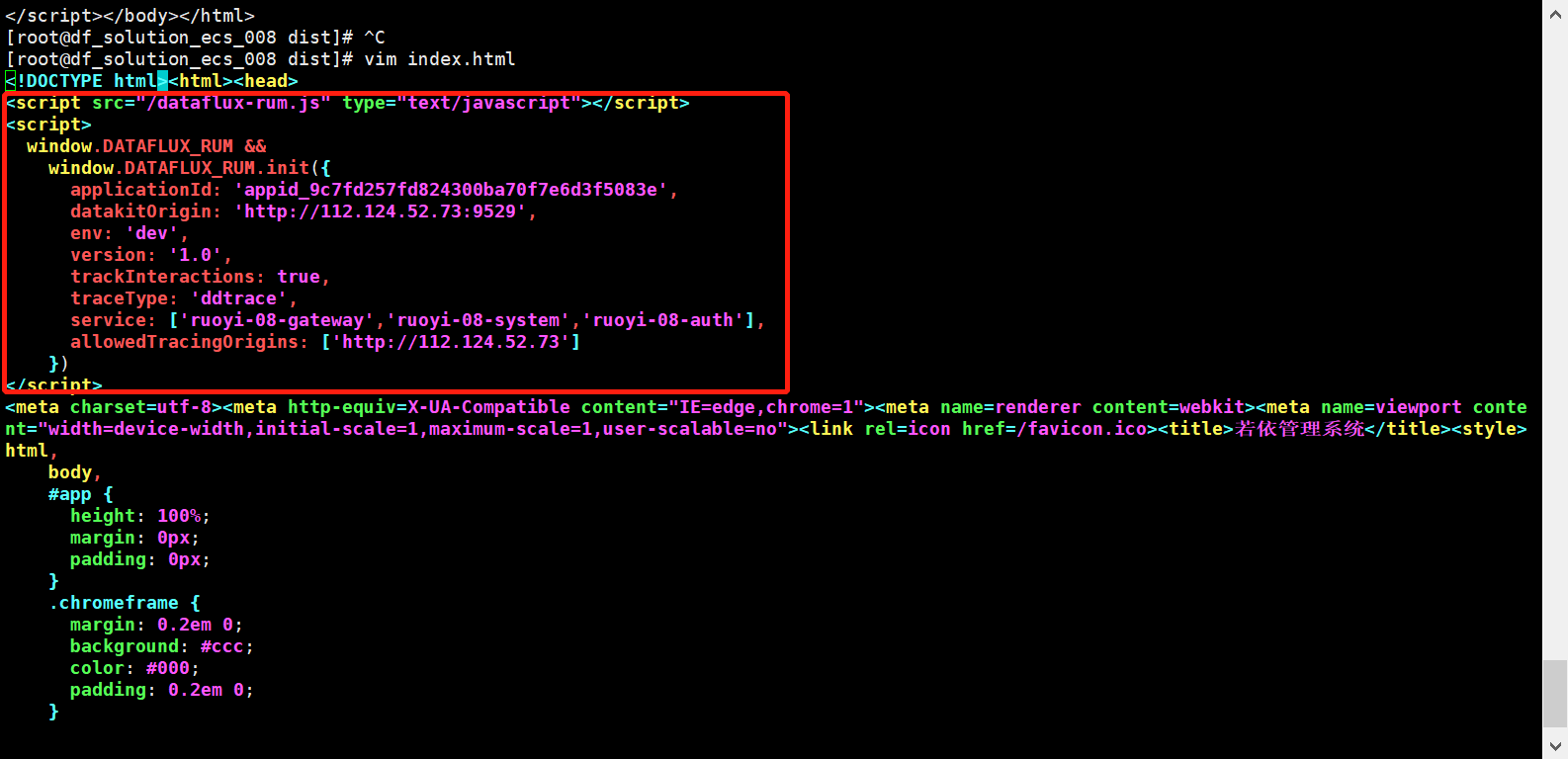
在前端页面 /usr/local/ruoyi/dist/index.html 的 head 中粘贴 JS
<script src="https://static.guance.com/browser-sdk/v2/dataflux-rum.js" type="text/javascript"></script>
<script>
window.DATAFLUX_RUM &&
window.DATAFLUX_RUM.init({
applicationId: 'appid_9c7fd257fd824300ba70f7e6d3f5083e',
datakitOrigin: 'http://112.124.52.73:9529',
env: 'dev',
version: '1.0',
trackInteractions: true,
traceType: 'ddtrace',
allowedTracingOrigins: ['http://112.124.52.73']
})
</script>
参数说明
- datakitOrigin:数据传输地址,生产环境如若配置的是域名,可将域名请求转发至具体任意一台安装有 datakit-9529 端口的服务器,如若前端访问量过大,可在域名与 datakit 所在服务器中间加一层 slb,前端 js 将数据发送至 slb,slb 将请求转发至多台安装 datakit-9529 所在的服务器。多台 datakit 承接 rum 数据,因前端请求复用因素,session 数据不会中断,对 rum 数据展现也无影响。
- allowedTracingOrigins:实现前后端(APM 与 RUM)打通,该场景只有在前端部署 RUM,后端部署 APM 的情况才会生效,需在此处填写与前端页面有交互关系的后端应用服务器所对应的域名(生产环境)或 IP(测试环境)。应用场景:前端用户访问出现慢,是由后端代码逻辑异常导致,可通过前端 RUM 慢请求数据直接跳转至 APM 数据查看当次后端代码调用情况,判定慢的根因。实现原理:用户访问前端应用,前端应用进行资源及请求调用,触发 rum-js 性能数据采集,rum-js 会生成 trace-id 写在请求的 request_header 里,请求到达后端,后端的 ddtrace 会读取到该 trace_id 并记录在自己的 trace 数据里,从而实现通过相同的 trace_id 来实现应用性能监测和用户访问监测数据联动
- env:必填,应用所属环境,是 test 或 product 或其他字段。
- version:必填,应用所属版本号。
- trackInteractions:用户行为统计,例如点击按钮,提交信息等动作。
3 发布¶
保存、验证并发布页面
打开浏览器访问目标页面,通过 F12 检查者模式,查看页面网络请求中是否有 rum 相关的请求,状态码是否是 200。
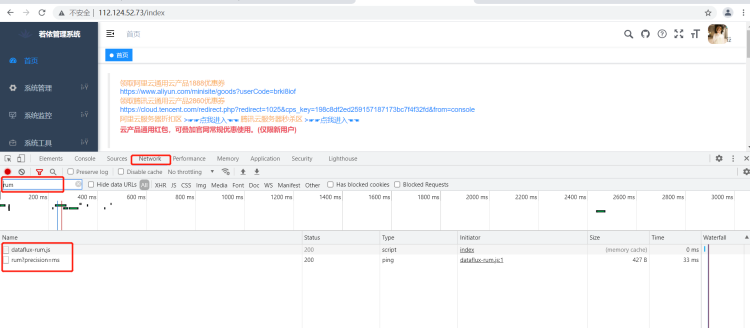
Warning
若 F12 检查者模式发现数据无法上报,显示端口 refused,可 telnet IP:9529 验证端口是否通畅。
若不通,需要修改 /usr/local/datakit/conf.d/datakit.conf ,将首行的 http_listen 修改为 0.0.0.0;
如若还不通,请检查安全组是否已打开 9529 端口。
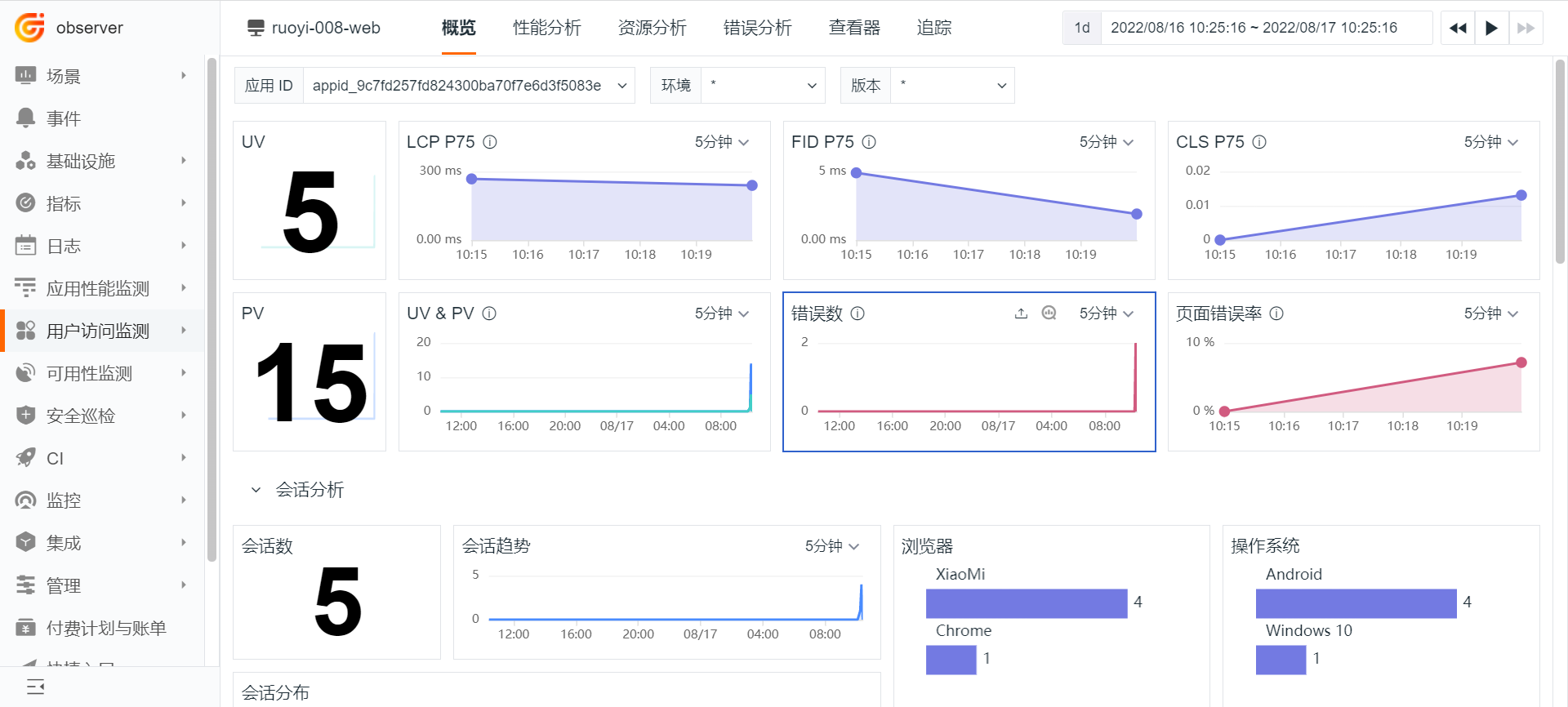
4 查看 RUM 数据¶
在「用户访问监测」可查看 RUM 相关数据
APM¶
详细步骤参见文档 分布式链路追踪(APM)最佳实践
观测云 支持的 APM 接入方式包含 ddtrace、SkyWalking、Zipkin、Jaejer 等多种支持 OpenTracing 协议的 APM 工具,此处示例采用 ddtrace 实现 APM 方面的可观测性。
1 修改 inputs¶
在 DataKit 中修改 APM(ddtrace)的 inputs
默认不需要修改 jvm 的 inputs,仅需复制生成 conf 文件即可
$ cd /usr/local/datakit/conf.d/ddtrace/
$ cp ddtrace.conf.sample ddtrace.conf
$ vim ddtrace.conf
# 默认不需要修改
2 修改 Java 应用启动脚本¶
APM 可观测性,需要在 Java 应用中添加一个 agent,该 agent 在伴随应用启动时,会通过字节码注入的技术实现对应用内部方法层层调用、sql 调用、外部系统调用等相关性能数据的采集,从而实现对应用系统代码质量的可观测性。
#原应用启动脚本
$ cd /usr/local/ruoyi/
$ nohup java -Dfile.encoding=utf-8 -jar ruoyi-gateway.jar > logs/gateway.log 2>&1 &
$ nohup java -Dfile.encoding=utf-8 -jar ruoyi-auth.jar > logs/auth.log 2>&1 &
$ nohup java -Dfile.encoding=utf-8 -jar ruoyi-modules-system.jar > logs/system.log 2>&1 &
——————————————————————————————————————————————————————————————————————————————————————————
#添加 ddtrace-agent 后的应用启动脚本
$ cd /usr/local/ruoyi/
$ nohup java -Dfile.encoding=utf-8 -javaagent:dd-java-agent-0.80.0.jar -XX:FlightRecorderOptions=stackdepth=256 -Ddd.logs.injection=true -Ddd.service.name=ruoyi-gateway -Ddd.service.mapping=redis:redis_ruoyi -Ddd.agent.port=9529 -Ddd.jmxfetch.enabled=true -Ddd.jmxfetch.check-period=1000 -Ddd.jmxfetch.statsd.port=8125 -Ddd.version=1.0 -jar ruoyi-gateway.jar > logs/gateway.log 2>&1 &
$ nohup java -Dfile.encoding=utf-8 -javaagent:dd-java-agent-0.80.0.jar -XX:FlightRecorderOptions=stackdepth=256 -Ddd.logs.injection=true -Ddd.service.name=ruoyi-auth -Ddd.service.mapping=redis:redis_ruoyi -Ddd.env=staging -Ddd.agent.port=9529 -Ddd.jmxfetch.enabled=true -Ddd.jmxfetch.check-period=1000 -Ddd.jmxfetch.statsd.port=8125 -Ddd.version=1.0 -jar ruoyi-auth.jar > logs/auth.log 2>&1 &
$ nohup java -Dfile.encoding=utf-8 -javaagent:dd-java-agent-0.80.0.jar -XX:FlightRecorderOptions=stackdepth=256 -Ddd.logs.injection=true -Ddd.service.name=ruoyi-modules-system -Ddd.service.mapping=redis:redis_ruoyi,mysql:mysql_ruoyi -Ddd.env=dev -Ddd.agent.port=9529 -Ddd.jmxfetch.enabled=true -Ddd.jmxfetch.check-period=1000 -Ddd.jmxfetch.statsd.port=8125 -Ddd.version=1.0 -jar ruoyi-modules-system.jar > logs/system.log 2>&1 &
ddtrace 相关环境变量(启动参数)说明:
- Ddd.env:自定义环境类型,可选项。
- Ddd.tags:自定义应用标签 ,可选项。
- Ddd.service.name: 自定义应用名称 ,必填项。
- Ddd.agent.port:数据上传端口(默认 9529 ),必填项。
- Ddd.version:应用版本,可选项。
- Ddd.trace.sample.rate:设置采样率(默认是全采),可选项,如需采样,可设置 0~1 之间的数,例如 0.6,即采样 60%。
- Ddd.service.mapping:当前应用调用到的 redis、mysql 等,可通过此参数添加别名,用以和其他应用调用到的 redis、mysql 进行区分,可选项,应用场景:例如项目 A 项目 B 都调用了 mysql,且分别调用的 mysql-a,mysql-b,如没有添加 mapping 配置项,在 df 平台上会展现项目 A 项目 B 调用了同一个名为 mysql 的数据库,如果添加了 mapping 配置项,配置为 mysql-a,mysql-b,则在 df 平台上会展现项目 A 调用 mysql-a,项目 B 调用 mysql-b。
- Ddd.agent.host:数据传输目标 IP,默认为本机 localhost,可选项。
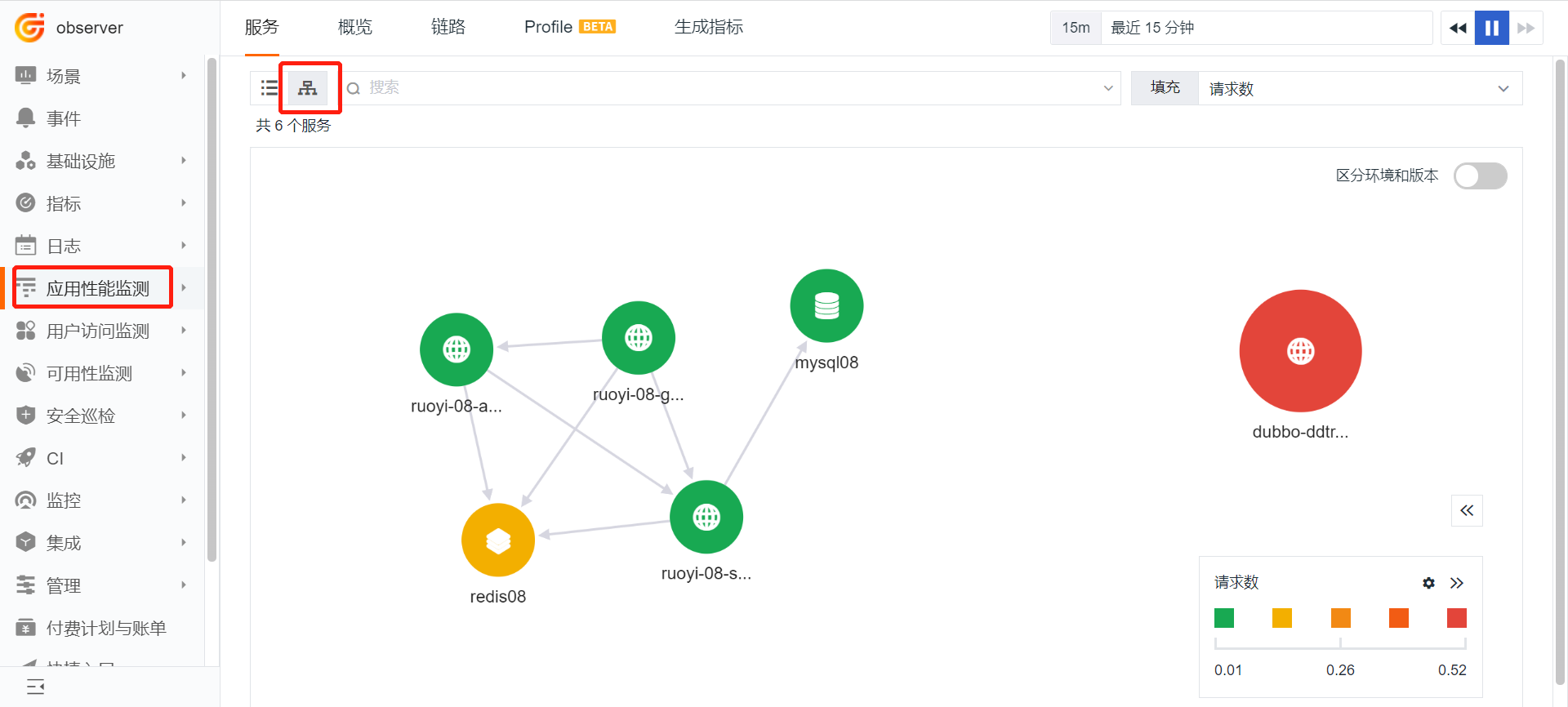
3 查看 APM 数据¶
APM 是观测云默认内置的模块,无需创建场景或视图即可进行查看。
视图示例:
通过该视图即可快速查看应用调用情况、拓扑图、异常数据等其他 APM 相关数据
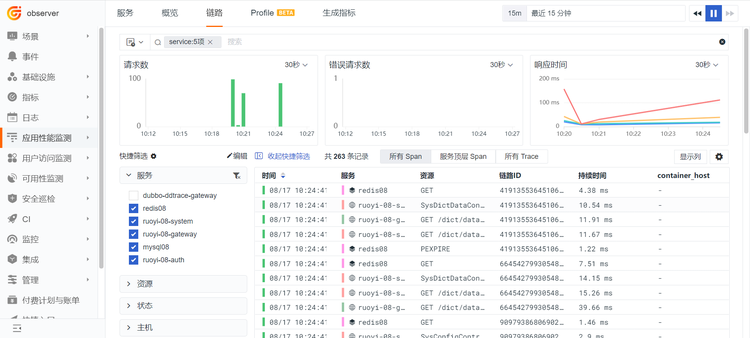
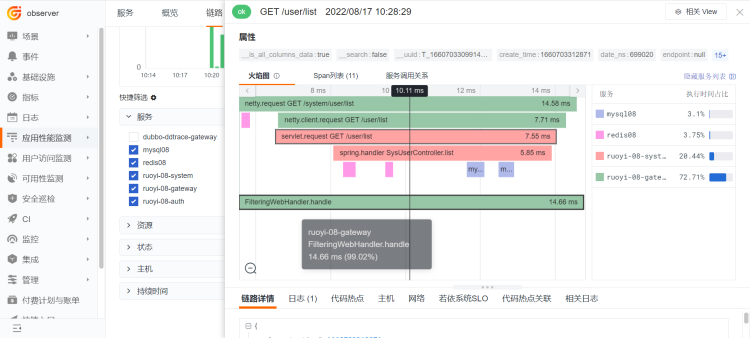
调用链路的问题追踪:
可以排查接口、数据库等问题
LOG¶
1 标准日志采集¶
如:Nginx、MySQL、Redis 等
通过开启 Datakit 内置的各种 inputs,可以直接开启相关的日志采集,例如 Ngnix、 Redis、容器、ES 等。
示例:Nginx
$ cd /usr/local/datakit/conf.d/nginx/
$ cp nginx.conf.sample nginx.conf
$ vim nginx.conf
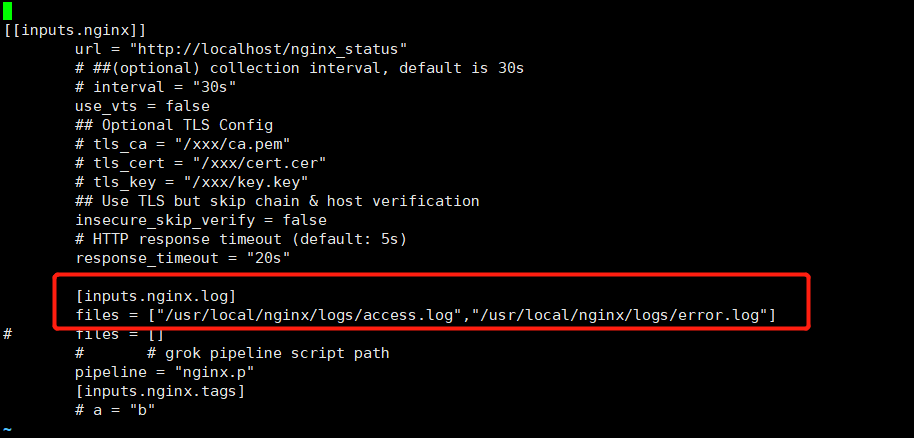
## 修改 log 路径为正确的 nginx 路径
$ [inputs.nginx.log]
$ files = ["/usr/local/nginx/logs/access.log","/usr/local/nginx/logs/error.log"]
$ pipeline = "nginx.p"
## pipeline 即为 grok 语句,主要用来进行文本日志切割,datakit 已内置多种 pipeline,包括nginx、mysql 等,pipeline 默认目录为 /usr/local/datakit/pipeline/ ,此处无需修改 pipeline 路径,datakit 默认会自动读取。
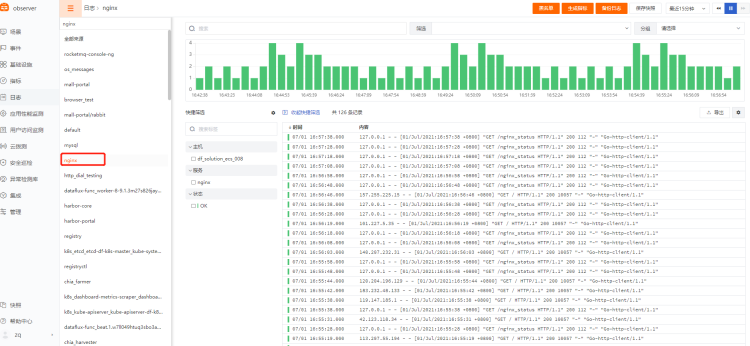
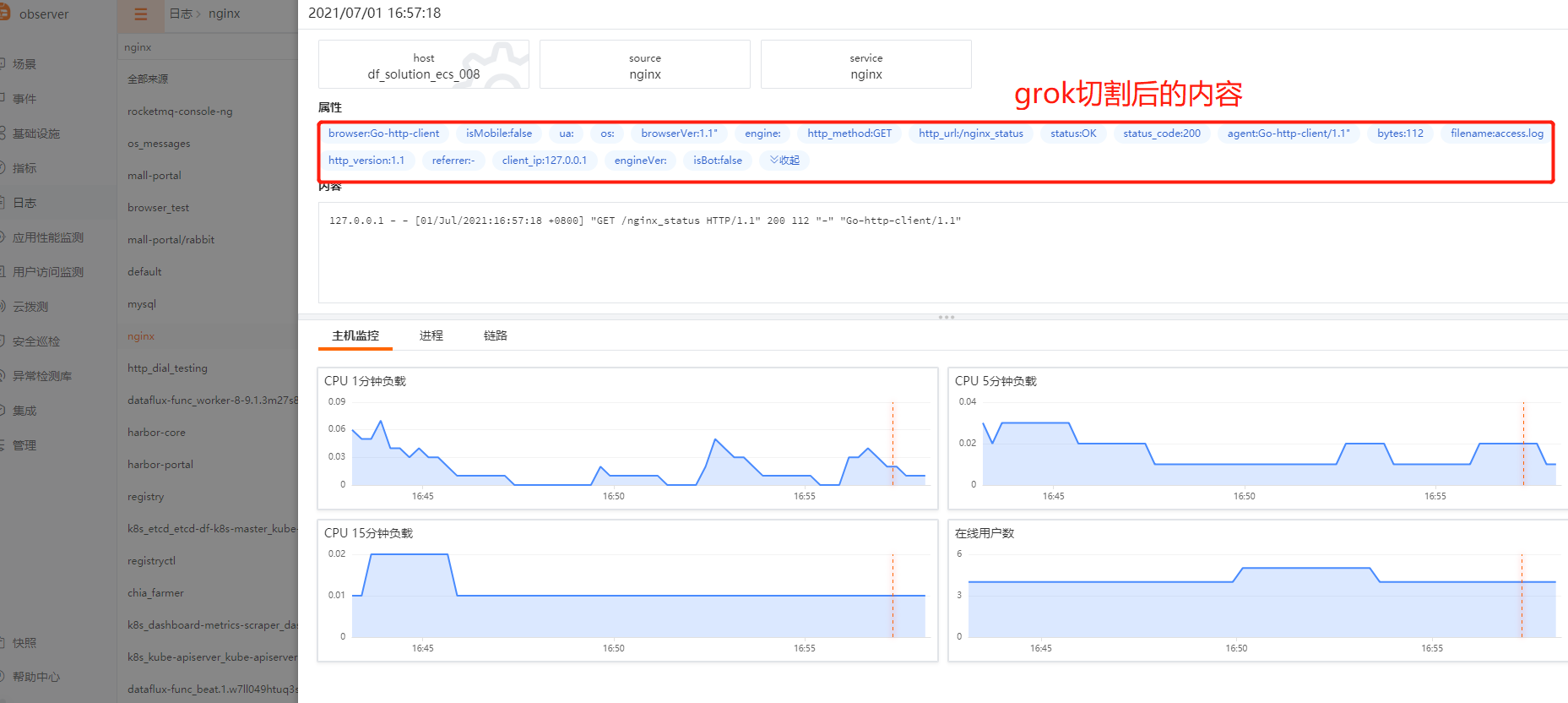
视图展示:
2 自定义日志采集¶
如:应用日志、业务日志等
示例:应用日志 Pipeline(日志 grok 切割)官方文档
$ cd /usr/local/datakit/conf.d/log/
$ cp logging.conf.sample system-logging.conf
$ vim system-logging.conf
## 修改 log 路径为正确的应用日志的路径
## source 与 service 为必填字段,可以直接用应用名称,用以区分不同的日志名称
[[inputs.logging]]
## required
logfiles = [
"/usr/local/java/ruoyi/logs/ruoyi-system/info.log",
"/usr/local/java/ruoyi/logs/ruoyi-system/error.log",
]
## glob filteer
ignore = [""]
## your logging source, if it's empty, use 'default'
source = "system-log"
## add service tag, if it's empty, use $source.
service = "system-log"
## grok pipeline script path
pipeline = "log_demo_system.p"
## optional status:
## "emerg","alert","critical","error","warning","info","debug","OK"
ignore_status = []
## optional encodings:
## "utf-8", "utf-16le", "utf-16le", "gbk", "gb18030" or ""
character_encoding = ""
## The pattern should be a regexp. Note the use of '''this regexp'''
## regexp link: https://golang.org/pkg/regexp/syntax/#hdr-Syntax
multiline_match = '''^\d{4}-\d{2}-\d{2}'''
## removes ANSI escape codes from text strings
remove_ansi_escape_codes = false
## pipeline 即为 grok 语句,主要用来进行文本日志切割,如果该配置不放开,默认 df 平台上展示日志原始文本内容,如若填写,会对对应日志进行 grok 切割,此处填写的 .p文件 需要自己手动编写
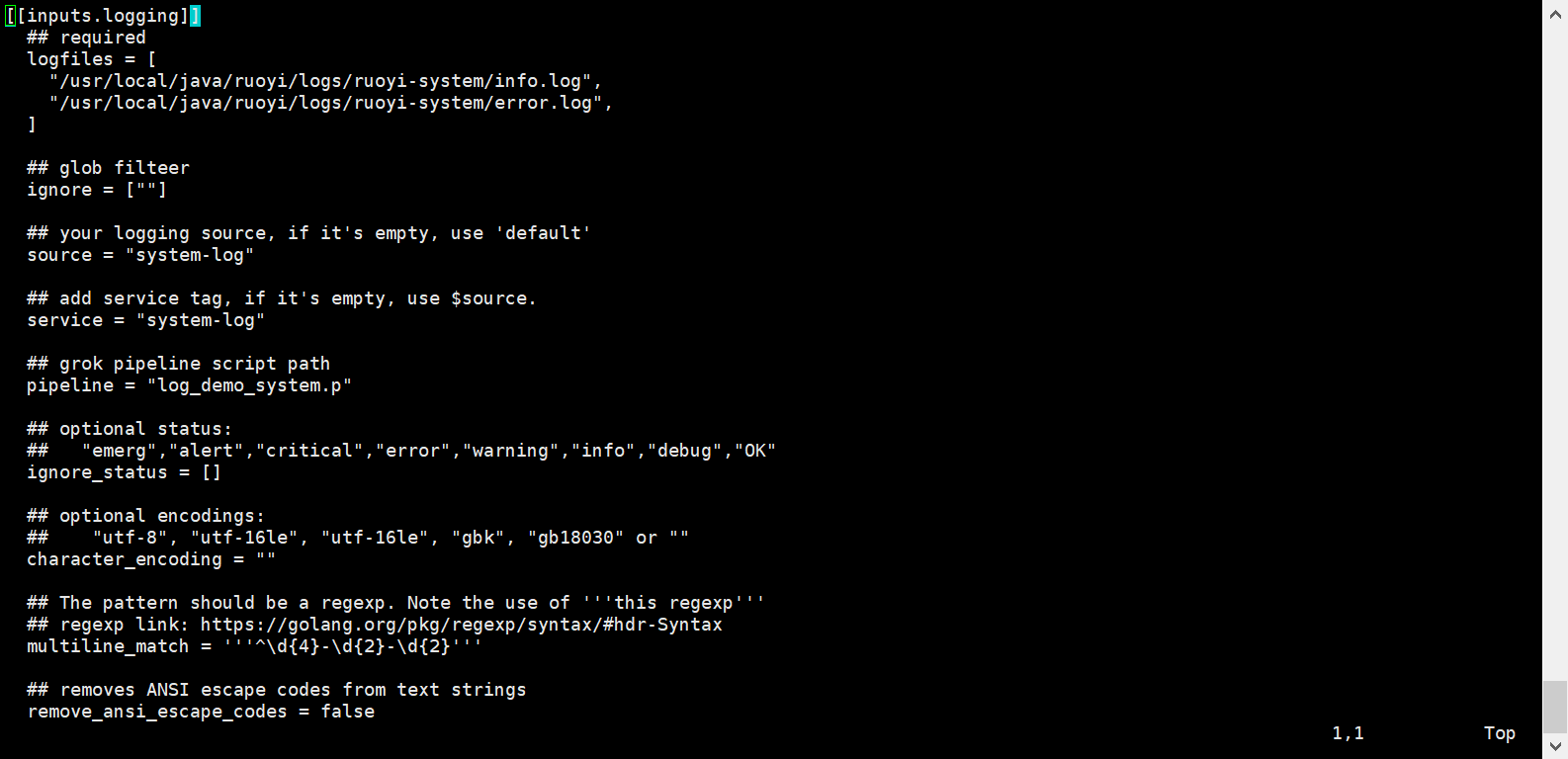
$ /usr/local/datakit/pipeline/
$ vim ruoyi_system.p
grok(_, "%{TIMESTAMP_ISO8601:time} %{NOTSPACE:thread_name} %{LOGLEVEL:status}%{SPACE}%{NOTSPACE:class_name} - \\[%{NOTSPACE:method_name},%{N
UMBER:line}\\] - %{DATA:service1} %{DATA:trace_id} %{DATA:span_id} - %{GREEDYDATA:msg}")
default_time(time)
3 查看日志数据¶
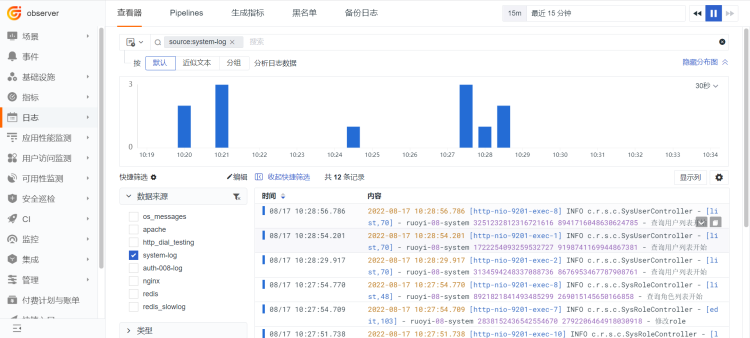
RUM 与 APM 数据联动演示¶
原理介绍:用户访问前端应用(已添加 rum 监控且已配置 allowedTracingOrigins 字段),前端应用调用资源及请求,触发 rum-js 性能数据采集,rum-js 会生成 trace-id 写在请求的 request_header 里,请求到达后端,后端的 ddtrace 会读取到该 trace_id 并记录在自己的 trace 数据里,从而实现通过相同的 trace_id 来实现应用性能监测和用户访问监测数据联动分析。
应用场景:前后端关联,前端请求与后端方法执行性能数据进行一对一绑定,从而更方便定位前后端关联的问题,例如前端用户登录缓慢,是因为后端服务调用数据库查询用户耗时过长导致的,就可通过前后端联动分析迅速跨团队跨部门进行问题定位,示例如下:
配置方式:web 应用监控(RUM)最佳实践
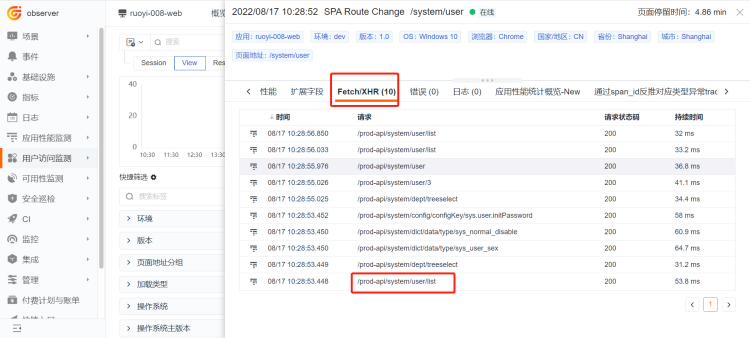
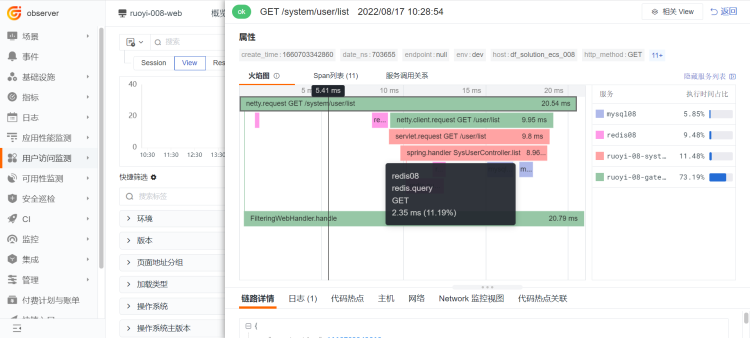
1 前端 RUM 数据¶
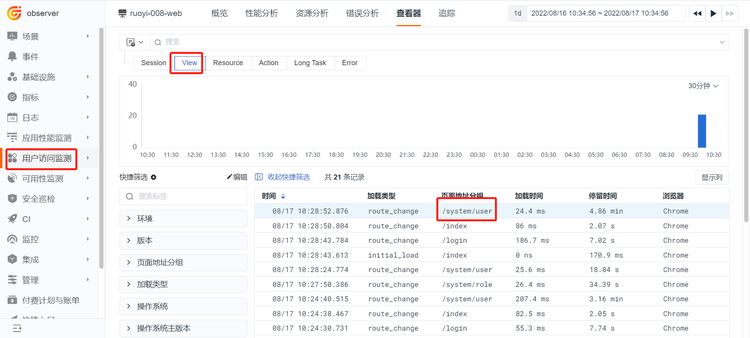
2 跳转至后端 APM 数据¶
APM 跟 LOG 数据联动演示¶
1 开启 APM 监控¶
参考 Kubernetes 应用的 RUM-APM-LOG 联动分析 APM 部分,无需额外操作。
2 修改应用日志输出格式¶
此步骤需开发介入,修改应用日志输出格式文件 logback/log4j
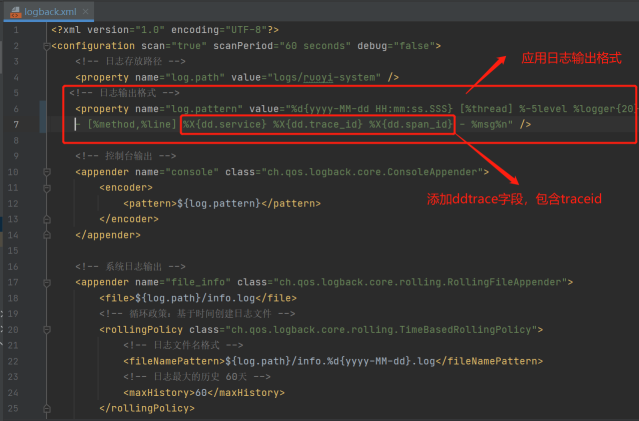
<!-- 日志输出格式 -->
<property name="log.pattern" value="%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{20} - [%method,%line] %X{dd.service} %X{dd.trace_id} %X{dd.span_id} - %msg%n" />
保存该 xml 文件并重新发布应用。
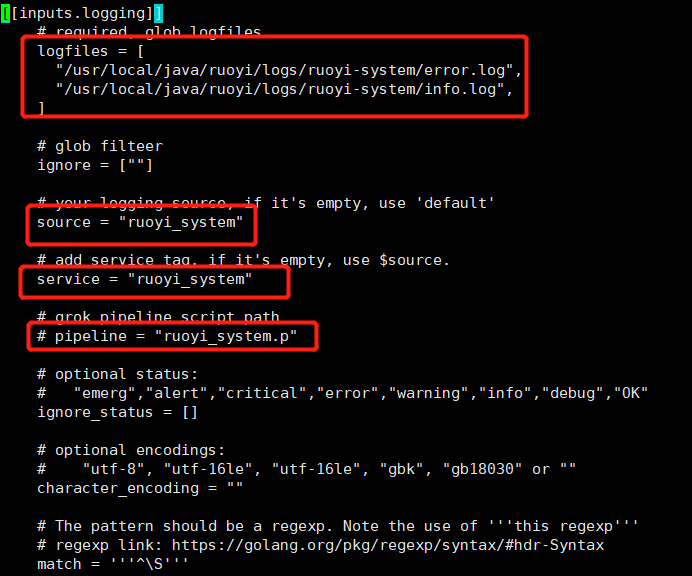
3 开启日志监控¶
举例:
$ cd /usr/local/datakit/conf.d/log/
$ cp log.conf.sample ruoyi-system.conf
$ vim ruoyi-system.conf
## 修改如下图内容
## logfiles 为应用日志绝对路径
## service 与 source 为必填字段,方便在 df 平台上进行查找
## Pipeline 可根据需求进行设置,pipeline 主要用作对日志进行字段切割,切割后的日志内容可转存成指标进行可视化展示,trace-id 相关内容没有可视化展示的必要,所以可以不用进行切割。
4 APM & LOG 联动分析¶
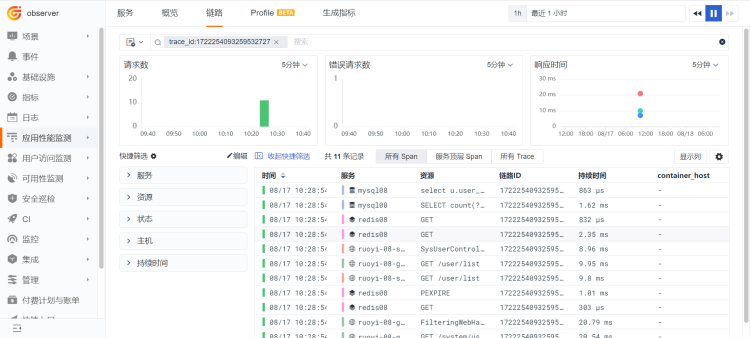
- 正向关联[APM——日志]
在 APM 链路数据中,下方日志模块直接搜索trace_id,即可查看此次链路调用所对应产生的应用日志。
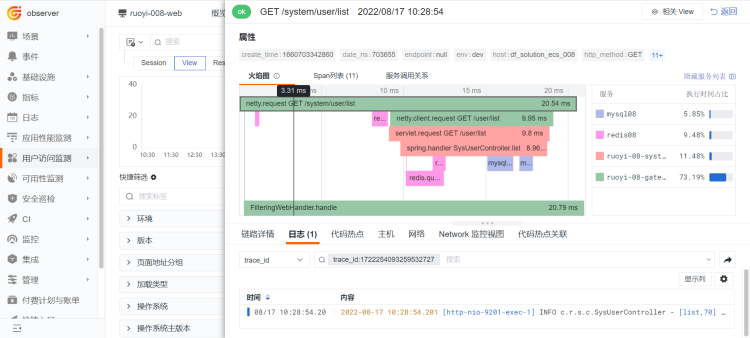
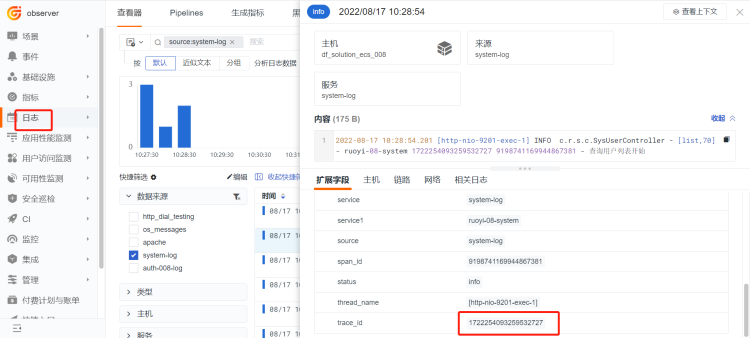
- 反向关联[日志——APM]
查看异常日志,在日志中复制trace_id,在链路追踪页面搜索框直接检索该trace_id,即可搜出于该 id 相关的所有 trace 及 span 数据,点击查看即可。