Switching from Line Protocol to Protobuf¶
Line Protocol¶
Due to historical reasons, DataKit internally uses InfluxDB's line protocol as the basic data structure to represent a specific data point. Its basic form is as follows:
The so-called line protocol uses a line of text like this to represent a specific data point, such as the following data point that represents a basic disk usage situation:
disk,device=/dev/disk3s1s1,fstype=apfs free=167050518528i,total=494384795648i,used=327334277120i,used_percent=66.21042556354438 1685509141064064000
Here, disk is the measurement, device and fstype are two tags, followed by a series of specific metrics at this point, and the last large integer represents the Unix timestamp in nanoseconds.
The values ending with i indicate signed integers. The data point above represents the specific usage of the disk. In addition to i, it also supports:
- Floating point (such as
used_percenthere, with no type suffix) - Unsigned integers (suffixed with
u) - Strings
- Booleans
If there are multiple data points, they are represented on separate lines (hence the name line protocol):
disk,device=/dev/disk3s1s1,fstype=apfs free=167050518528i,total=494384795648i,used=327334277120i,used_percent=66.21042556354438 1685509141064064000
disk,device=/dev/disk3s6,fstype=apfs free=167050518528i,total=494384795648i,used=327334277120i,used_percent=66.21042556354438 1685509141064243000
disk,device=/dev/disk3s2,fstype=apfs free=167050518528i,total=494384795648i,used=327334277120i,used_percent=66.21042556354438 1685509141064254000
disk,device=/dev/disk3s4,fstype=apfs free=167050518528i,total=494384795648i,used=327334277120i,used_percent=66.21042556354438 1685509141064260000
Line protocol, due to its strong readability and basic data expression capabilities, met our initial needs.
Protobuf¶
As data collection continues to deepen, we are facing two problems:
- The data types that line protocol can represent are somewhat limited; for example, it does not support array-type fields.
In the collection of processes, we need to collect the list of ports opened by the process, which can only be represented by embedding JSON within a string. For binary data, it is basically unsupported.
-
The official InfluxDB line protocol SDK is poorly designed and has some performance issues:
- After the data point (Point) is constructed, secondary operations on it (such as Pipeline) require the Point to be unpacked again, causing a waste of CPU/memory.
- The performance of encoding/decoding is not good, which affects data processing under high throughput conditions.
For the above reasons, we have abandoned the line protocol data structure (v1) and have instead adopted a completely custom data structure (v2), which is then transmitted using Protobuf. Compared to version v1, v2 supports more features:
-
The data types are fully customized, free from the constraints of InfluxDB's Point, and we have added support for arrays/map/binary, etc.
- With binary support, we can directly add binary files in the Point, such as appending the corresponding Profile file directly in the profile data point.
- Protobuf's JSON structure can be directly used for HTTP requests, while line protocol does not provide a corresponding JSON form, causing developers to passively become familiar with the line protocol.
-
The constructed data points are not encapsulated and can still be freely modified.
- In terms of encoding volume, since the line protocol is entirely in text form, after gzip compression, its volume is slightly smaller (the difference within 0.1% for a 1MB payload), and Protobuf is not weak in this regard.
- Protobuf has higher encoding/decoding efficiency. Benchmarks show that the encoding efficiency is about 10 times higher, and the decoding efficiency is about 5 times higher:
# Encoding
BenchmarkEncode/bench-encode-lp
BenchmarkEncode/bench-encode-lp-10 250 4777819 ns/op 8674069 B/op 41042 allocs/op
BenchmarkEncode/bench-encode-pb
BenchmarkEncode/bench-encode-pb-10 2710 433151 ns/op 1115021 B/op 16 allocs/op
# Decoding
BenchmarkDecode/decode-lp
BenchmarkDecode/decode-lp-10 72 15973900 ns/op 4670584 B/op 90286 allocs/op
BenchmarkDecode/decode-pb
BenchmarkDecode/decode-pb-10 393 3044680 ns/op 3052845 B/op 70025 allocs/op
Based on the improvements of v2 in various aspects, we have conducted some basic tests on our observability, and there are obvious improvements in memory and CPU usage:
On DataKit with medium to low load, the performance difference between v2 and v1 is very obvious:
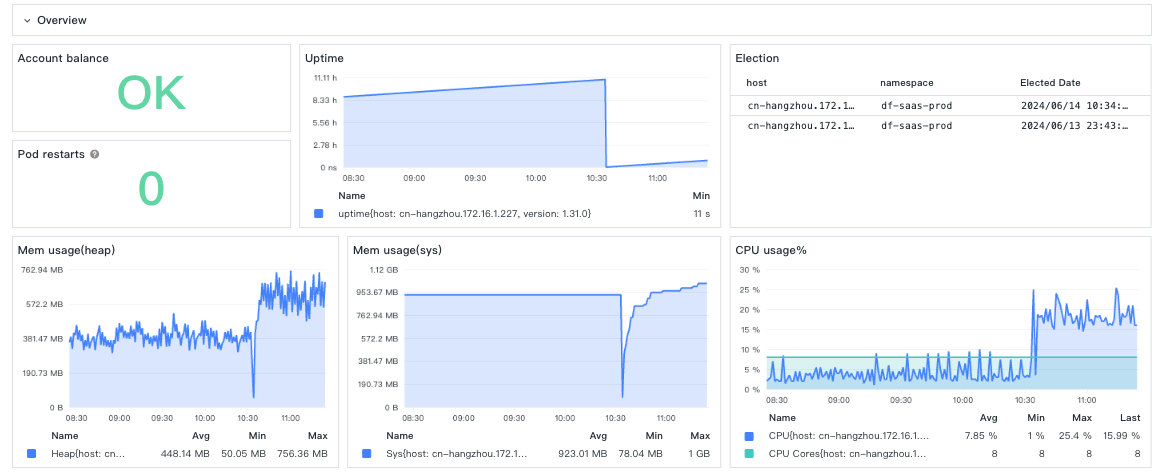
At 10:30, when switching from v2 to v1, it can be seen that CPU and memory have a noticeable increase. On DataKit with high load, the performance difference is also obvious:
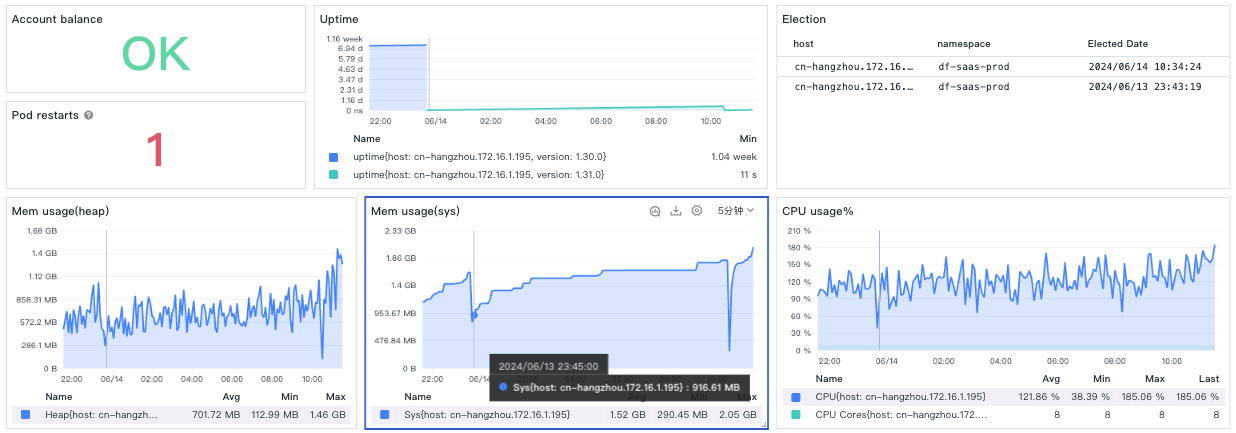
At 23:45, when switching to v2, the sys/heap memory is much lower compared to 10:30 the next day when switching to v1. In terms of CPU, after switching to v1 at 10:30, there is an increase in CPU, but it is not very obvious, mainly because the main CPU of the high-load DataKit is not in data encoding.
Conclusion¶
Compared to v1, v2 not only has significant performance improvements but is also no longer limited in terms of extensibility. At the same time, v2 also supports encoding in the form of v1 to be compatible with old deployment versions and development habits. In DataKit, we can use point-pool to achieve better memory/CPU performance.