DataKit 日志采集综述
日志数据对于整体的可观测性,其提供了足够灵活、多变的的信息组合方式,正因如此,相比指标和 Tracing,日志的采集、处理方式方案更多,以适应不同环境、架构以及技术栈的采集场景。
总体而言,DataKit 有如下几种日志采集方案:
- 从磁盘文件获取日志
- 采集容器 stdout 日志
- 远程推送日志给 DataKit
- Sidecar 形式的日志采集
以上各种采集方式,因具体环境不同,又会有一些变种,但总体上是这几种方式之间的组合。下面分门别类,一一加以介绍。
从磁盘文件获取日志¶
这是最原始的日志处理方式,不管是对开发者而言,还是传统的日志收集方案而言,日志最开始一般都是直接写到磁盘文件的,写到磁盘文件的日志有如下几个特点:
- 序列式写入:一般的日志框架,都能保证磁盘文件中的日志,保持时间的序列性
- 自动切片:由于磁盘日志文件都是物理递增的,为避免日志将磁盘打爆,一般日志框架都会自动做切割,或者通过一些外部常驻脚本来实现日志切割
基于以上特征,我们很容易想到,DataKit 只需要要持续盯住这些文件的变更即可(即采集最新的更新),一旦有日志写入,则 DataKit 就能采集到,而且其部署也很简单,只需要在日志采集器的 conf 中填写要采集的文件路径(或通配路径)即可。
这里建议使用通配路径(甚至可以配置当前不存在、但将来会冒出来的文件),而不是将日志路径写死,因为应用的日志可能不会立即出现(比如部分应用的 error log 只有 error 发生的时候才会出现)。
磁盘文件采集有一点需要注意,即它只会采集自 DataKit 启动后有更新的日志文件,如果配置的日志文件(自 DataKit 启动后)没有更新,其历史数据是不会采集的。
正因为这个特性,如果日志文件持续在更新,中间停止 DataKit,该空窗期的日志也不会被采集到,后面可能会做一些策略来缓解这个问题。
容器 stdout 日志¶
这种采集方式目前主要针对容器环境中的 stdout 日志,这种日志要求运行在容器(或 Kubernetes Pod)中的应用将日志输出到 stdout,这些 stdout 日志实际上会在 Node 上落盘,DataKit 通过对应的容器 ID 能找到对应的日志文件,然后按照普通磁盘文件的方式对其进行采集。
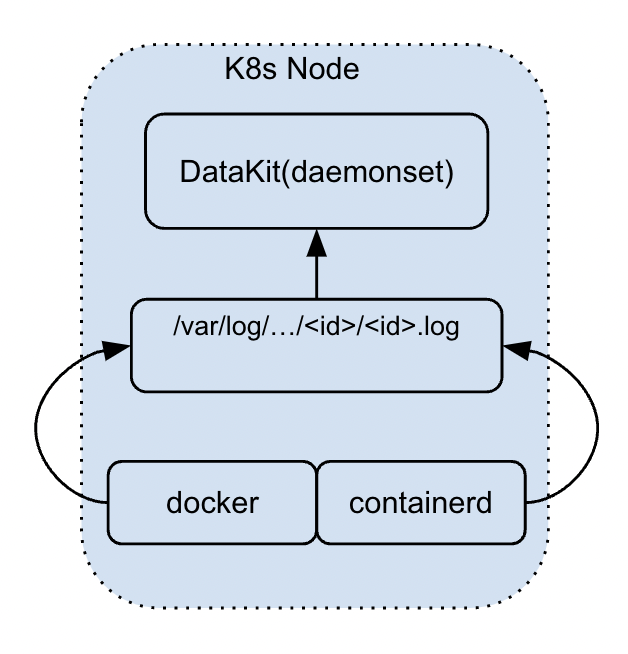
在 DataKit 现有 stdout 采集方案中(主要针对 k8s 环境),日志的采集有如下几个特点:
-
由于部署在容器环境中的应用,均需构建对应的容器镜像。对 DataKit 而言,可以基于镜像名称,选择性的针对某些应用做日志采集
- 通过在 ConfigMap 的 container.conf 中,选择部分镜像名称(或其通配)来定点采集 stdout 日志
- 染色标记:通过 Annotation 修改 Pod 标注,DataKit 能识别到这些特殊的 Pod,进而对其 stdout 日志进行采集
这也是这种策略的一个缺陷,即要求应用将日志输出到 stdout,在一般的应用开发中,日志不太会直接写到 stdout(但主流的日志框架一般都支持输出到 stdout),需要开发者调整日志配置。但是,随着容器化部署方案不断普及,这种方案不失为一种可行的日志采集方式。
远程推送日志给 DataKit¶
对远程日志推送而言,其主要是
-
开发者直接将应用日志推送到 DataKit 指定的服务上,比如 Java 的 log4j 以及 Python 原生的
SocketHandler均支持将日志发送给远端服务。
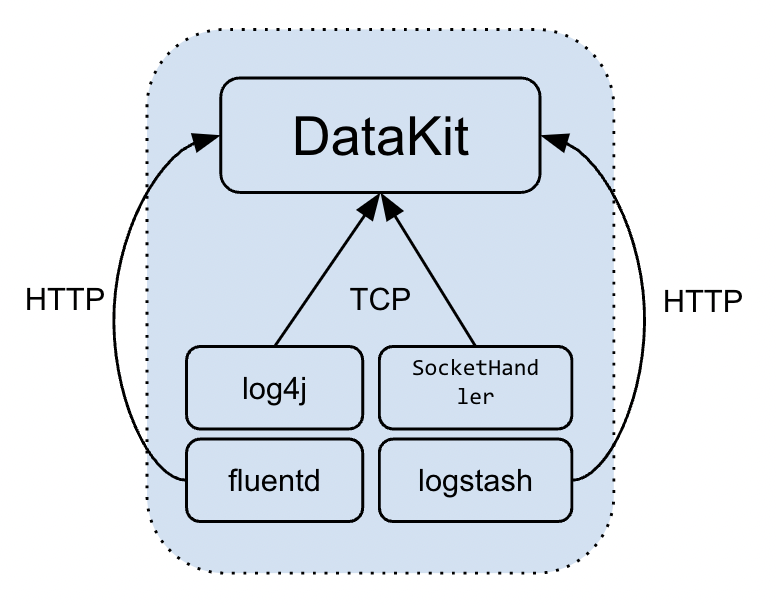
这种形式的特点是日志直接发送给 DataKit,中间无需落盘。这种形式的日志采集,需注意以下几点:
- 对 TCP 形式的日志推送,其日志类型(
source/service)如果多变,那么需要在 DataKit 上开多个 TCP 端口
如果希望 DataKit 上只开启单个(或少数几个)TCP 端口,那么需要在后续 Pipeline 处理中,对切割出来的字段,识别其特征,并通过函数
set_tag()来标记其service(目前无法修改日志的source字段,且该功能只有 1.2.8 以上的版本才支持)。
- 对 HTTP 形式的日志推送,开发者需在 HTTP 请求参数上标记好特征,便于 DataKit 做后续处理
Sidecar 形式的日志采集¶
这种方式的采集实际上是综合了磁盘日志采集和日志远程推送俩种方式,具体而言,就是在用户的 Pod 中添加一个跟 DataKit 配套(即 logfwd)的 Sidecar 应用,其采集方式如下:
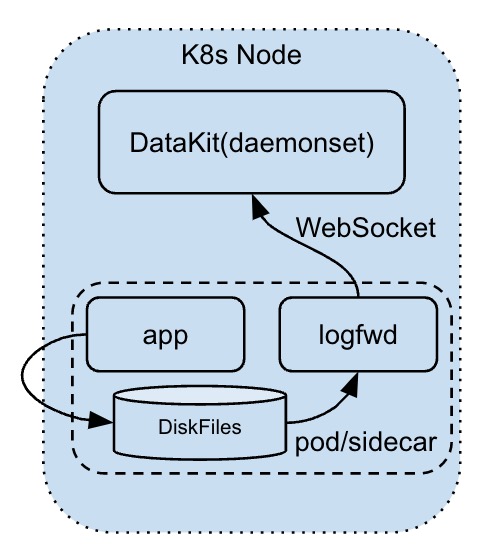
- 通 logfwd 以磁盘文件的方式先获取到日志
- 然后 logfwd 再将日志远程推送(WebSocket)给 DataKit
这种方式目前只能在 k8s 环境下使用,其有如下几个特点:
- 相比单纯的远程日志推送,它能自动追加一些 Pod 的 k8s 属性字段,如 Pod 名称以及 k8s namespace 信息
- 开发者可以不用修改日志的配置,依然将日志输出到磁盘即可。在 k8s 环境中,甚至可以不用外挂存储,logfwd 直接从 pod 自身存储捞取日志推送出来(但日志需做好自动切割设置,避免将 pod 存储打满)
日志的处理¶
以上的日志采集到之后,均支持后续 Pipeline 的切割,但配置形式稍有差异:
- 磁盘日志采集:直接配置在 logging.conf 中,其中指定 Pipeline 名称即可
- 容器 stdout 日志采集:不能在 container.conf 中配置 Pipeline,因为这里针对的是所有容器的日志采集,很难用一个通用的 Pipeline 处理所有的日志。故必须通过 Annotation 的方式,指定相关 Pod 的 Pipeline 配置
- 远程日志采集:对 TCP/UDP 传输方式,可以也是在 logging.conf 中指定 Pipeline 配置。而对于 HTTP 传输方式,开发者需在 HTTP 请求参数上来配置 Pipeline
- Sidecar 日志采集:在 logfwd 的配置中,配置宿主 Pod 的 Pipeline,其本质上跟容器 stdout 相似,都是针对 Pod 的定点标记
日志采集通用的额外选项¶
所有的日志采集,不管其使用何种采集方式,除了上面提及的 Pipeline 切割外,均支持如下采集配置:
- 多行切割:大部分日志都是单行日志,但某些日志是多行形式,如调用栈日志、部分特殊应用的日志(如 MySQL 慢日志)
- 编码:最终的日志都需要转换成 UTF8 存储,对于一些 Windows 日志,可能需要做编解码处理
总结¶
上面整体介绍了 DataKit 目前的日志采集方案。总体上而言,目前这几种方案,基本能覆盖住主流的日志数据场景。随着软件技术的不断迭代,新的日志数据形式也将不断涌现出来,届时 DataKit 也会做出对应的调整,以适应新的场景。