Introduction to the Overall Architecture of DataKit¶
DataKit is a basic data collection tool running on the user's local machine, which is mainly used to collect various metrics, logs and other data of system operation, and summarize them to Guance. In Guance, users can view and analyze their own metrics, logs and other data.
DataKit is an important data collection component in Guance, and almost all the data in Guance come from DataKit.
DataKit Basic Network Model¶
The DataKit network model is mainly divided into three layers, which can be simply summarized as user environment, DataWay and Guance center, as shown in the following figure:
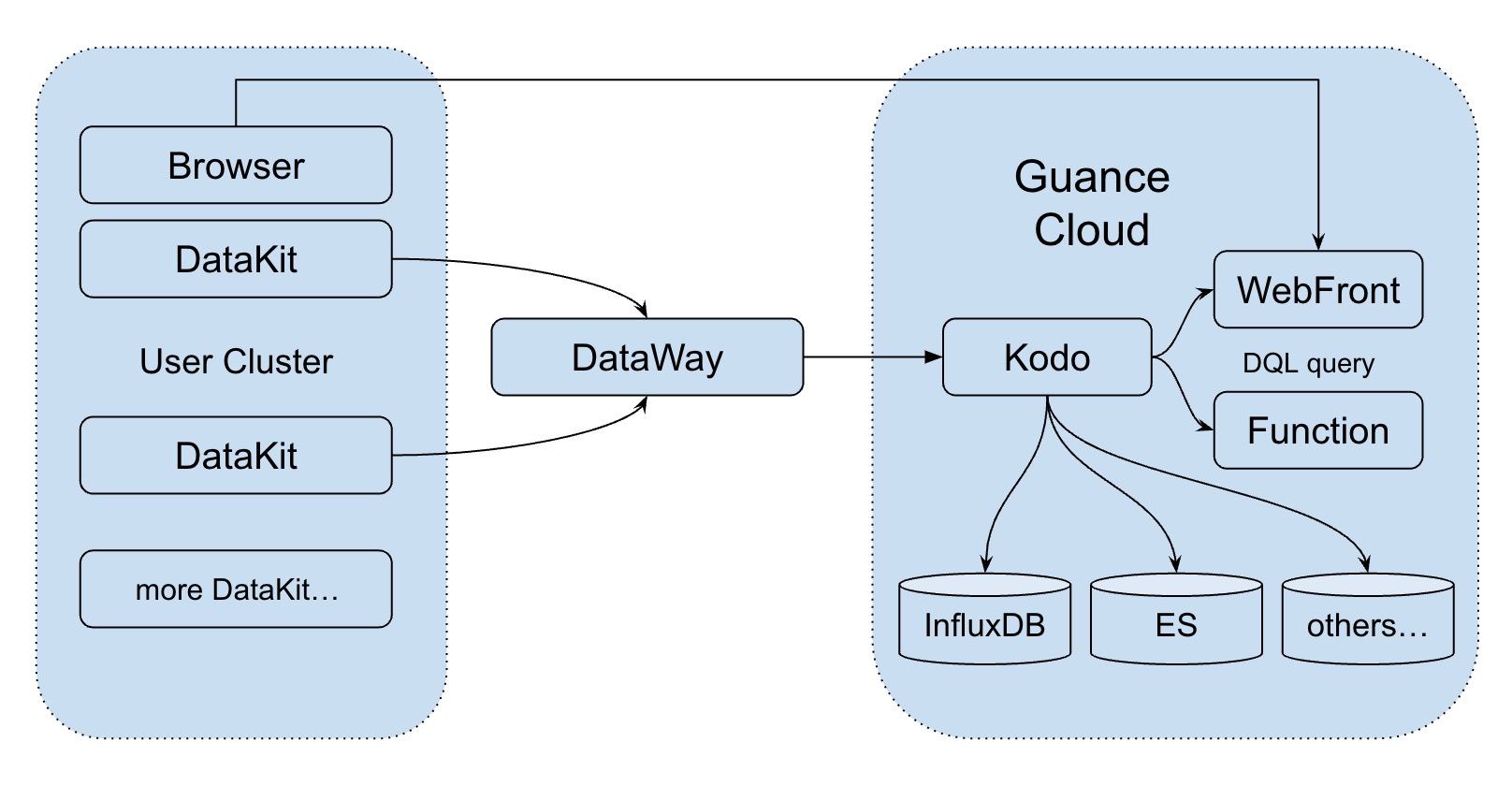
- DataKit mainly collects various metrics through regular collection, and then sends the data to DataWay through HTTP (s) regularly and quantitatively. Each DataKit is configured with a corresponding token to identify different users.
If the user's intranet environment does not open the external request, Nginx can be used as a layer Proxy, and Proxy collector built in DataKit can also be used to realize traffic Proxy.
- After DataWay receives the data, it forwards to Guance, and the data sent to Guance has API signature.
- After Guance receives the legal data, it writes it into different storage according to different data types.
For data collection services, under normal circumstances, part of the data is allowed to be lost (because the data itself is collected intermittently, and the data in the intermittent period can be regarded as a kind of data loss). At present, the whole data transmission link is protected as follows:
- When DataKit fails to send a DataWay for some network reason, DataKit caches up to a thousand points of data. When the cached data exceeds this amount, the cache will be cleaned up.
- DataWay may fail to send Guance for some reason, or because the traffic is too large to send it to Guance, DataWay will persist the data to disk. When the traffic is reduced or the network is restored, these data will be sent to Guance. Delayed data does not affect timeliness, and timestamps are attached to cached data.
The maximum amount of this disk can also be configured to protect the disk on DataWay in order not to burst the storage of the node. For data that exceeds the usage, DataWay also chooses to discard the data. However, this capacity is generally set to be relatively large.
DataKit Internal Architecture¶
The internal architecture of DataKit is relatively simple, as shown in the following figure:
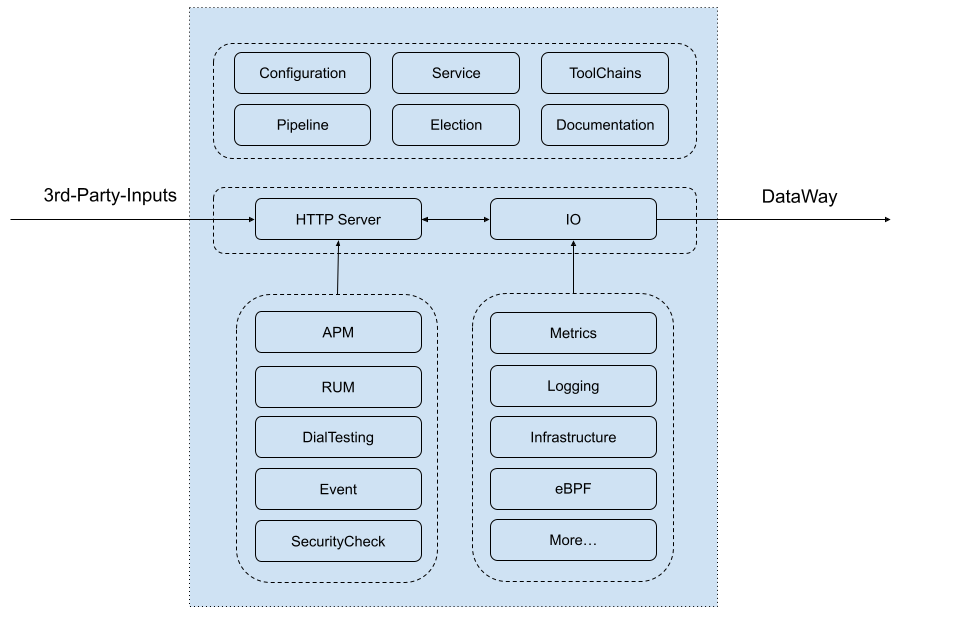
From top to bottom, the interior of DataKit is mainly divided into three layers:
-
Top level: including program entry module and some public modules
- Configuration loading module: Except for DataKit's own main configuration (
conf.d/datakit.conf), the configuration of each collector is configured separately. If put together, this configuration file may be very large and not easy to edit. - Service management module: Mainly responsible for the management of the whole DataKit service.
- Tool chain module: DataKit, as a client program, not only collects data, but also provides many other peripheral functions, which are implemented in the tool chain module, such as viewing documents, restarting services, updating and so on.
- Pipeline module: In log processing, through Pipeline script, the log is cut, and the unstructured log data is converted into structured data. In other non-log data, corresponding data processing can also be performed.
- Election module: When a large number of DataKits are deployed, users can make the configuration of all DataKits the same, and then distribute the configuration to each DataKit through automated batch deployment The significance of the election module is that in a cluster, when collecting some data (such as Kubernetes cluster index), should only have one DataKit to collect (otherwise, the data will be repeated and pressure will be caused to the collected party). When all DataKit configurations in the cluster are identical, only one DataKit can be collected at any time through the election module.
- Document module: DataKit documents are generated by its own code, which is convenient for automatic publication of documents.
- Configuration loading module: Except for DataKit's own main configuration (
-
Transport layer: responsible for almost all data input and output.
- HTTP service module: DataKit supports access to third-party data, such as Telegraf/Prometheus, and more data sources can be accessed later. At present, these data are accessed through HTTP.
- IO module: Each data collection plug-in will send data to IO module after each collection. IO module encapsulates a unified data construction, processing and sending interface, which is convenient to access the data collected by various collector plug-ins. In addition, the IO module sends data to DataWay over HTTP (s) at a certain rhythm (periodic, quantitative).
-
Collection layer: responsible for collecting various data. According to the type of collection, it is divided into two categories:
- Active collection type: This type of collector collects according to the configured fixed frequency, such as CPU, network traffic, cloud dial test, etc.
- Passive acquisition type: This kind of collector usually realizes acquisition by external data input, such as RUM、Tracing, etc. They generally run outside of DataKit, and can standardize the data through DataKit's openData Upload API, and then upload it to Guance.
Each different collector runs independently in an independent goroutine, and is protected by an outer layer. Even if a single collector collapses for some reasons (each collector can crash up to 6 times during the running period), it will not affect the overall operation of DataKit.
In order to avoid unexpected performance loss caused by the collector to the user environment, such as setting the collection frequency too high (sets
1mto1ms), DataKit has a global protection mode (the protection mode can be turned off globally, similar to the system firewall), and for these unexpected wrong settings, DataKit will automatically adjust to relatively normal settings.
Most of the DataKit code (98 +%) is developed in Golang and currently supports the mainstream Linux/Mac/Windows platform. Because DataKit runs as a service (resident) in the user environment, DataKit should not depend too much on the running environment and should not cause obvious performance consumption in the user environment. At present, the basic operation performance of DataKit is as follows:
- Few environment dependencies: Most collectors are integrated with the DataKit main program (that is, they are all developed in Golang), and very few data set collections have dynamic library dependencies or environment dependencies (such as relying on Python environment), which can be satisfied by users through simple operations。
- Control resource consumption: the resident memory consumption is about 30MB, and the CPU consumption is controlled at about 3% (the test CPU is Intel (R) Core (TM) i5-5200U CPU @ 2.20 GHz and there is room for optimization); Disk consumption is almost negligible. The network traffic depends on the amount of data collected. The traffic from DataKit is sent in the form of line protocolcompression, and the data volume is very small while maintaining readability.
In theory, any observable data can be collected through DataKit. With the increasing demand of users for observation data, DataKit will gradually increase more different types of data collection; Thanks to the high scalability of the DataKit plug-in model, achieving this goal becomes extremely simple.