DataKit 整体架构简介¶
DataKit 是运行在用户本地机器上的一种基础数据采集工具,主要用于采集系统运行的各种指标、日志等数据,将它们汇总给 观测云,在观测云中,用户可以查看并分析自己的各种指标、日志等数据。
DataKit 是观测云中至关重要的一个数据采集组件,几乎所有观测云中的数据都是来源于 DataKit。
DataKit 基础网络模型¶
DataKit 网络模型主要分为三层,可以简单概括为用户环境、DataWay 以及观测云中心,如下图所示:
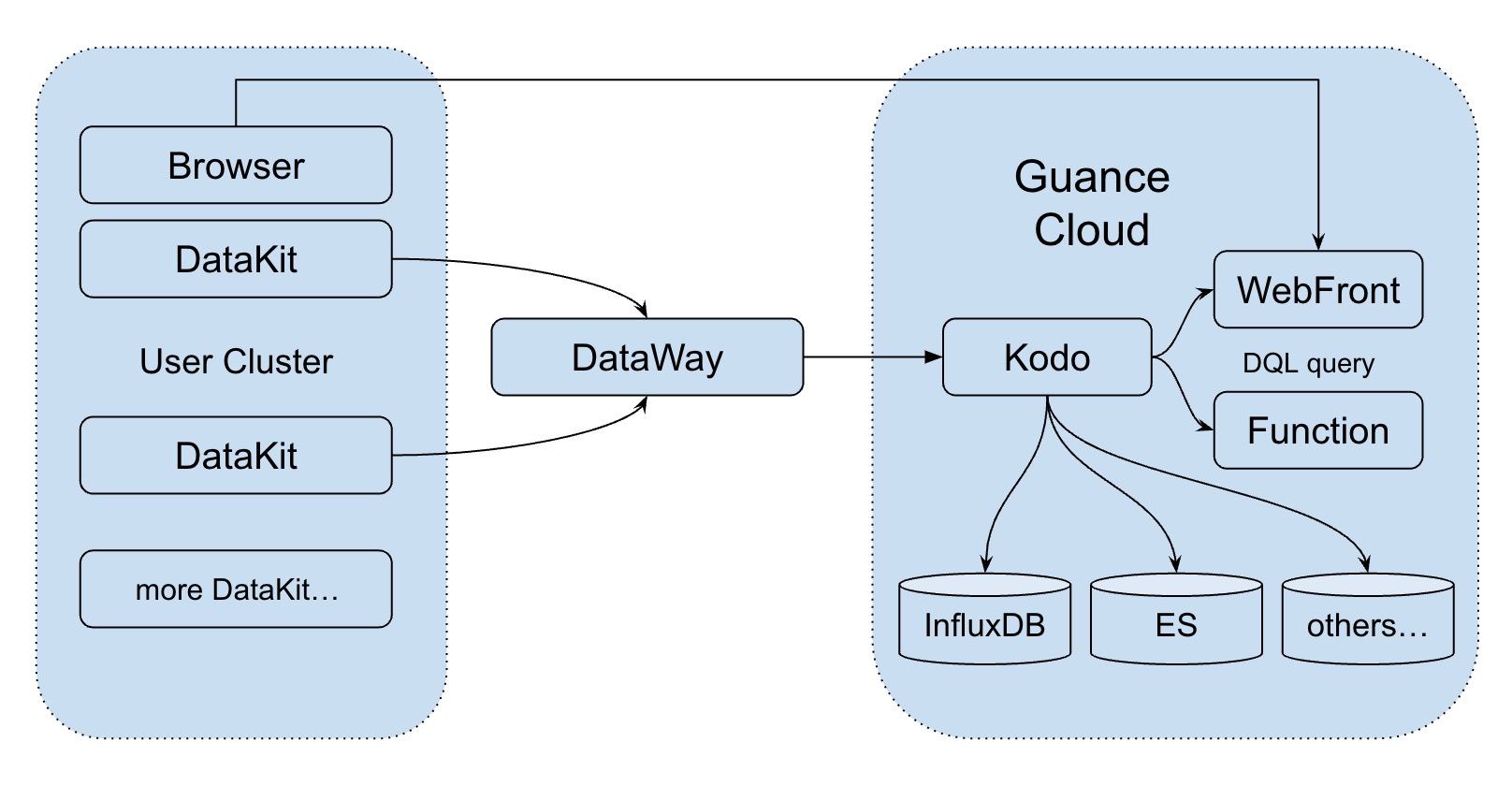
- DataKit 主要通过定期采集的方式,采集各种不同的指标,然后定时、定量通过 HTTP(s) 将数据发送给 DataWay。每个 DataKit 都会配置对应的 token,用于标识不同的用户
注意:如果用户内网环境没有开通外网请求,可以通过 Nginx 做一层代理出来,也可以通过 DataKit 内置的 Proxy 采集器 来实现流量代理
- DataWay 收到数据后,转发给观测云,在发给观测云的数据中,带有 API 签名
- 观测云收到合法的数据后,根据不同的数据类型,分别写入不同的存储中
对于采集类的数据业务,一般情况下,允许部分数据丢失(因为本身数据就是间歇采集的,间歇期内的数据,可视为一种数据丢失),目前整个数据传输链路做了如下丢失保护:
- DataKit 因为某些网络原因,发送 DataWay 失败,此时 DataKit 会缓存最大一千个点的数据。当缓存的数据超过这个量,这个缓存会被清理掉
- DataWay 可能因为某些原因,发送观测云失败,或者因为流量较大,来不及发送给观测云,DataWay 会将这些数据持久化到磁盘。后续待流量降低或网络恢复时,再将这些数据发送给观测云。延迟发送的数据,不影响时效性,时间戳是附着在缓存的数据中的。
在 DataWay 上,为保护磁盘,这个磁盘的最大用量也是可以配置的,以免将所在节点的存储撑爆。对于超过用量的数据,DataWay 也是选择丢弃数据。不过这个容量一般设置得比较大。
DataKit 内部架构¶
DataKit 内部架构相对比较简单,如下图所示:
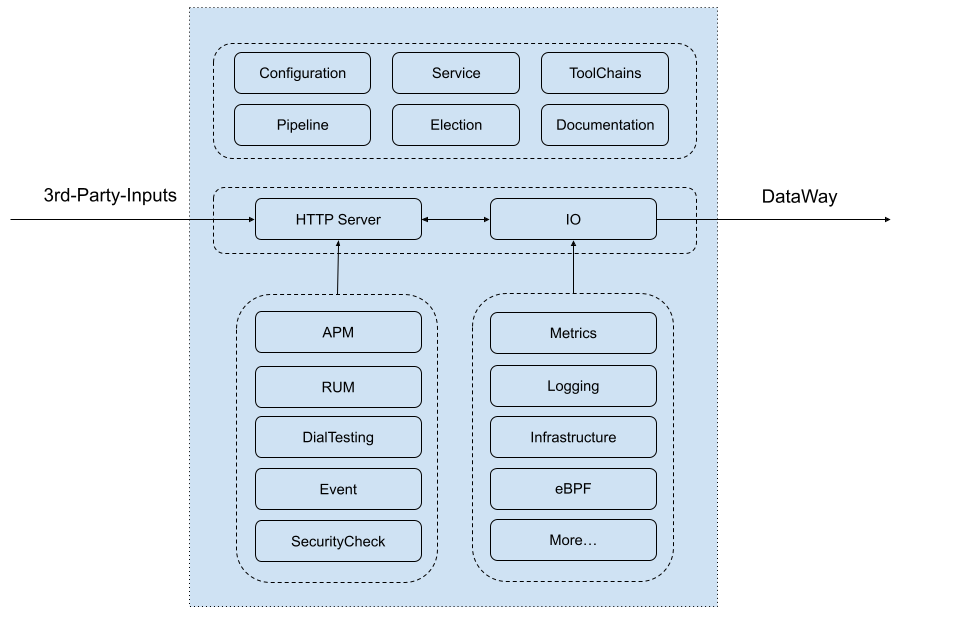
自上往下,DataKit 内部主要分成三层:
-
顶层:包括程序入口模块以及一些公共模块
- 配置加载模块:DataKit 除了自己的主配置(即
conf.d/datakit.conf)之外,各个采集器的配置都是分开配置的,如果放一起,这个配置文件可能非常大,不便于编辑 - 服务管理模块:主要负责整个 DataKit 服务的管理
- 工具链模块:DataKit 作为一个客户端程序,除了采集数据之外,还提供了很多其它的周边功能,这些都是在工具链模块实现的,如查看文档、重启服务、更新等
- Pipeline 模块:在日志处理中,通过 Pipeline 脚本,实现对日志的切割,将非结构的日志数据,转换成结构化数据。在其它非日志类数据中,也可以进行对应的数据处理
- 选举模块:当部署的 DataKit 特别多时,用户可以将所有 DataKit 的配置做成一样,然后通过自动化批量部署将配置下发给各个 DataKit。选举模块的意义在于,在一个集群中,某些数据的采集(如 Kubernetes 集群指标),只应有一个 DataKit 实施采集(不然数据重复,且给被采集方造成压力)。在集群中所有 DataKit 配置都一样的情况下,通过选举模块,即可实现任意时间,最多只会有一个 DataKit 实施采集
- 文档模块:DataKit 的文档通过自身代码生成,便于文档的自动发布
- 配置加载模块:DataKit 除了自己的主配置(即
-
传输层:负责几乎所有数据的输入输出
- HTTP 服务模块:DataKit 支持第三方数据的接入,比如 Telegraf/Prometheus,后续还可以接入更多的数据源。目前这些数据都是通过 HTTP 接入
- IO 模块:各个数据采集插件,每次采集完成后,都会将数据发送给 IO 模块。IO 模块封装了统一的数据构建、处理和发送接口,便于接入各个采集器插件采集的数据。另外,IO 模块会以一定的节奏(定期、定量),通过 HTTP(s) 将数据发送给 DataWay
-
采集层:负责各种数据的采集。按照采集的类型,分成两类:
- 主动采集型:这类采集器按照配置的固定频率来采集,比如 CPU、网卡流量、云拨测等
- 被动采集型:这类采集器通常是以外部数据输入来实现采集,比如 RUM、Tracing等。它们一般运行在 DataKit 之外,可通过 DataKit 开放的数据上传 API,对数据经过一定的标准化处理,然后再上传到观测云
每个不同的采集器,都单独运行在独立的 goroutine 中,且做了外层保护,即使单个采集器因为某些原因奔溃(每个采集器运行期最大允许崩溃 6 次),也不会影响 DataKit 整体的运行。
为避免采集器对用户环境造成意外的性能损耗,比如采集频率设置过高(手抖将
1m设置成了1ms),DataKit 有全局的保护模式(保护模式可全局关闭,类似系统防火墙),对这些意外的错误设置,DataKit 会自动调整成相对正常的设置。
DataKit 绝大部分代码(98+%)都用 Golang 开发,目前支持主流的 Linux/Mac/Windows 平台。由于 DataKit 在用户环境以服务的 方式(常驻)运行,DataKit 不能对运行环境有太多的依赖,且不应对用户的环境造成明显的性能消耗。目前 DataKit 的基本运行表现如下:
- 极少环境依赖:绝大部分采集器都是跟 DataKit 主程序集成在一起的(也即它们都是以 Golang 开发),极少数有动态库依赖或环境依赖(比如依赖 Python 环境)的数据集采集,用户通过简单的操作即可满足
- 控制资源消耗:常驻内存消耗大概在 30MB 左右,CPU 消耗控制在 3% 左右(测试 CPU 为 Intel(R) Core(TM) i5-5200U CPU @ 2.20GHz 还有优化空间);磁盘消耗几乎可以忽略。网络流量则视具体采集的数量而定,DataKit 出来的流量均以行协议压缩的形式发送,在保持可读性的情况下,数据体积也很小
理论上,任何可被观测的数据,都可以通过 DataKit 来采集,随着用户观测数据的需求日益增长,DataKit 将逐步增加更多不同类型的数据采集;得益于 DataKit 插件模型的高扩展性,这一目标的实现,变得异常简单。