Pipeline 各类别数据处理¶
自 DataKit 1.4.0 起,可通过内置的 Pipeline 功能直接操作 DataKit 采集数据,支持目前所有的数据类型
Attention
- Pipeline 应用到所有数据,目前处于实验阶段,不保证后面会对机制或行为做不兼容的调整。
- 即使是通过 DataKit API 上报的数据也支持 Pipeline 处理。
- 用 Pipeline 对现有采集的数据进行处理(特别是非日志类数据),极有可能破坏已有的数据结构,导致数据在观测云上表现异常
- 应用 Pipeline 之前,请大家务必使用 Pipeline 调试工具确认数据处理是否符合预期
Pipeline 可以对 DataKit 采集的数据执行如下操作:
输入的数据结构¶
所有类别的数据在被 Pipeline 脚本处理前均会封装成 Point 结构,其结构可以视为:
struct Point {
Name: str # 等价于 Metric(时序) 数据的指标集名、Logging(日志) 数据的 source、
# Network 数据的 source、Object/CustomObject(对象) 数据的 class ...
Tags: map[str]str # 存储数据的所有标签,对于非时序类别数据,tag 与 field 的界限较模糊
Fields: map[str]any # 存储数据的所有字段(时序类别数据称为指标)
Time: int64 # 作为数据的时间,通常解释为数据产生的时间戳,单位纳秒
DropFlag: bool # 标记该数据是否应被丢弃
}
以一条 nginx 日志数据为例,其被日志采集器采集到后生成的数据作为 Pipeline 脚本的输入大致为:
Point {
Name: "nginx"
Tags: map[str]str {
"host": "your_hostname"
},
Fields: map[str]any {
"message": "127.0.0.1 - - [12/Jan/2023:11:51:38 +0800] \"GET / HTTP/1.1\" 200 612 \"-\" \"curl/7.81.0\""
},
Time: 1673495498000123456,
DropFlag: false,
}
提示:
-
其中
name可以通过函数set_measurement()修改。 -
在 point 的 tags/fields map,任意一个 key 不能也不会同时出现在 tags 和 fields 中;
-
可以在 Pipeline 中通过自定义标识符或函数
get_key()读取 point 的 tags/fields map 中的对应键的值;但修改 Tags 或 Fields 中键的值需要通过其他内置函数进行,如add_key等函数;其中_可以视为message这个 key 的别名。 -
在脚本运行结束后,如果在 point 的 tags/fields map 中存在名为
time的 key,将被删除;当其值为 int64 类型,则将其值赋予 point 的 time 后删除。如果 time 为字符串,可以尝试使用函数default_time()将其转换为 int64。 -
可以使用
drop()函数将输入 Point 标记为待丢弃,在脚本执行结束后,该数据将不会被上传。
Pipeline 脚本的存储、索引、匹配¶
脚本存储与索引¶
目前 Pipeline 脚本按来源划分为四个命名空间,索引优先级递减,如下表所示:
| 命名空间 | 目录 | 支持的数据类别 | 描述 |
|---|---|---|---|
remote |
[DataKit 安装目录]/pipeline_remote | CO, E, L, M, N, O, P, R, S, T | 观测云控制台管理的脚本 |
confd |
[DataKit 安装目录]/pipeline_cond | CO, E, L, M, N, O, P, R, S, T | Confd 管理的脚本 |
gitrepo |
[DataKit 安装目录]/pipeline_gitrepos/[repo-name] | CO, E, L, M, N, O, P, R, S, T | Git 管理的脚本 |
default |
[DataKit 安装目录]/pipeline | CO, E, L, M, N, O, P, R, S, T | DataKit 生成的脚本或用户编写的 |
注意:
- 请勿修改 pipeline 目录下的自动生成的采集器默认脚本,如果修改,在 DataKit 启动后,脚本将被覆盖;
- 建议在 pipeline/[category]/ 目录下添加对应数据类别的本地脚本;
- 除 pipeline 目录外,请勿对其他脚本目录(remote、confd、gitrepo)请勿进行任何形式的修改。
DataKit 在选择对应的 Pipeline 时,这四个命名空间内的脚本的索引优先级是递减的。以 cpu 指标集为例,当需要 metric/cpu.p 时,DataKit 查找顺序如下:
pipeline_remote/metric/cpu.ppipeline_confd/metric/cpu.pgitrepo/<repo-name>/metric/cpu.ppipeline/metric/cpu.p
注:此处
<repo-name>视大家 git 的仓库名而定。
我们会为每一个数据类别下的脚本分别创建索引,该功能不会导致 use() 函数跨命名空间引用脚本;Pipeline 的脚本存储和脚本索引的实现见下图所示,在建立脚本索引时,高优先级命名空间的脚本将遮盖低优先级的:
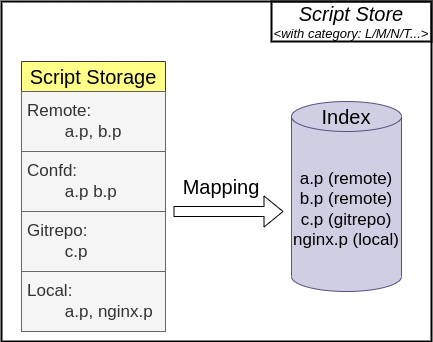
以上四个来源的 Pipeline 目录均按照如下方式来存放 Pipeline 脚本:
├── pattern <-- 专门存放自定义 pattern 的目录
├── apache.p
├── consul.p
├── sqlserver.p <--- 所有顶层目录下的 Pipeline 默认作用于日志,以兼容历史设定
├── tomcat.p
├── other.p
├── custom_object <--- 专用于自定义对象的 pipeline 存放目录
│ └── some-object.p
├── keyevent <--- 专用于事件的 pipeline 存放目录
│ └── some-event.p
├── logging <--- 专用于日志的 pipeline 存放目录
│ └── nginx.p
├── metric <--- 专用于时序指标的 pipeline 存放目录
│ └── cpu.p
├── network <--- 专用于网络指标的 pipeline 存放目录
│ └── ebpf.p
├── object <--- 专用于对象的 pipeline 存放目录
│ └── HOST.p
├── rum <--- 专用于 RUM 的 pipeline 存放目录
│ └── error.p
├── security <--- 专用于 scheck 的 pipeline 存放目录
│ └── scheck.p
└── tracing <--- 专用于 APM 的 pipeline 存放目录
└── service_a.p
数据与脚本匹配策略¶
数据和脚本名的匹配策略有四条,将从第 4(最高优先级) 条到第 1 条进行判断,若满足高优先级策略则不执行低优先级的策略:
- 根据输入数据生成的数据特征字符串,加上 Pipeline 的脚本文件扩展名
.p,查找对应类别的脚本 - 在观测云控制台为该类别下所有数据设置的数据类别的默认脚本
- 在观测云控制台设定的的数据与脚本的映射关系
- 在采集器配置文件指定脚本
以上所有的数据与脚本的匹配策略都依赖于数据的数据特征字符串;对于不同类别的数据,其数据特征字符串的生成策略有所不同:
- 以特定的 point tag/field 来生成数据特征字符串:
- APM 的 Tracing 与 Profiling 类别数据:
- 以 tags/fields 中的
service的值来生成数据特征字符串。例如,DataKit 采集到一条数据,如果service值为service-a,则会将生成service-a,对应脚本名service-a.p,之后将在 Tracing/Profiling 类别的脚本索引下进行查找;
- 以 tags/fields 中的
-
Scheck 的 Security 类别数据特征字符串:
- 以 tags/fields 中的
category的值来生成数据特征字符串。例如,DataKit 接收到一条 Security 数据,如果category值为system,则会生成system,对应脚本名system.p。
- 以 tags/fields 中的
-
以特定的 point tag/field 和 point name 来生成数据特征字符串:
-
RUM 的 RUM 类别数据:
- 以 tags/fields 中的
app_id的值和 point name 的值生成数据特征字符串;以 point name 值为action为例,生成<app_id>_action,对应脚本名<app_id>_action.p;
- 以 tags/fields 中的
-
以 point name 来生成数据特征字符串:
- Logging/Metric/Network/Object/... 等其他所有类别:
- 均以 point name 来生成数据特征字符串。以时序指标集
cpu为例,会生成cpu,对应脚本cpu.p;而对象数据中 class 为HOST的主机对象而言,会生成HOST,对应脚本HOST.p。
- 均以 point name 来生成数据特征字符串。以时序指标集
Pipeline 处理示例¶
示例脚本仅供参考,具体使用请根据需求编写
处理时序数据¶
以下示例用于展示如何通过 Pipeline 来修改 tag 和 field。通过 DQL,我们可以得知一个 CPU 指标集的字段如下:
dql > M::cpu{host='u'} LIMIT 1
-----------------[ r1.cpu.s1 ]-----------------
core_temperature 76
cpu 'cpu-total'
host 'u'
time 2022-04-25 12:32:55 +0800 CST
usage_guest 0
usage_guest_nice 0
usage_idle 81.399796
usage_iowait 0.624681
usage_irq 0
usage_nice 1.695563
usage_softirq 0.191229
usage_steal 0
usage_system 5.239674
usage_total 18.600204
usage_user 10.849057
---------
编写如下 Pipeline 脚本,
# file pipeline/metric/cpu.p
set_tag(script, "metric::cpu.p")
set_tag(host2, host)
usage_guest = 100.1
重启 DataKit 后,新数据采集上来,通过 DQL 我们可以得到如下修改后的 CPU 指标集:
dql > M::cpu{host='u'}[20s] LIMIT 1
-----------------[ r1.cpu.s1 ]-----------------
core_temperature 54.250000
cpu 'cpu-total'
host 'u'
host2 'u' <--- 新增的 tag
script 'metric::cpu.p' <--- 新增的 tag
time 2022-05-31 12:49:15 +0800 CST
usage_guest 100.100000 <--- 改写了具体的 field 值
usage_guest_nice 0
usage_idle 94.251269
usage_iowait 0.012690
usage_irq 0
usage_nice 0
usage_softirq 0.012690
usage_steal 0
usage_system 2.106599
usage_total 5.748731
usage_user 3.616751
---------
处理对象数据¶
以下 Pipeline 示例用于展示如何丢弃(过滤)数据。以 Nginx 进程为例,当前主机上的 Nginx 进程列表如下:
$ ps axuwf | grep nginx
root 1278 0.0 0.0 55288 1496 ? Ss 10:10 0:00 nginx: master process /usr/sbin/nginx -g daemon on; master_process on;
www-data 1279 0.0 0.0 55856 5212 ? S 10:10 0:00 \_ nginx: worker process
www-data 1280 0.0 0.0 55856 5212 ? S 10:10 0:00 \_ nginx: worker process
www-data 1281 0.0 0.0 55856 5212 ? S 10:10 0:00 \_ nginx: worker process
www-data 1282 0.0 0.0 55856 5212 ? S 10:10 0:00 \_ nginx: worker process
www-data 1283 0.0 0.0 55856 5212 ? S 10:10 0:00 \_ nginx: worker process
www-data 1284 0.0 0.0 55856 5212 ? S 10:10 0:00 \_ nginx: worker process
www-data 1286 0.0 0.0 55856 5212 ? S 10:10 0:00 \_ nginx: worker process
www-data 1287 0.0 0.0 55856 5212 ? S 10:10 0:00 \_ nginx: worker process
通过 DQL 我们可以知道,一个具体进程的指标集字段如下:
dql > O::host_processes:(host, class, process_name, cmdline, pid) {host='u', pid=1278}
-----------------[ r1.host_processes.s1 ]-----------------
class 'host_processes'
cmdline 'nginx: master process /usr/sbin/nginx -g daemon on; master_process on;'
host 'u'
pid 1278
process_name 'nginx'
time 2022-05-31 14:19:15 +0800 CST
---------
编写如下 Pipeline 脚本:
if process_name == "nginx" {
drop() # drop() 函数将该数据标记为待丢弃,且执行后会继续运行 pl
exit() # 可通过 exit() 函数终止 Pipeline 运行
}
重启 DataKit 后,对应的 NGINX 进程对象就不会再采集上来(中心对象有个过期策略,需等 5~10min 让原 NGINX 对象自动过期)。