Kubernetes 健康巡检¶
背景¶
现如今 Kubernetes 已经席卷了整个容器生态系统,它充当着容器分布式部署的大脑,旨在使用跨主机集群分布的容器来管理面向服务的应用程序。Kubernetes 提供了用于应用程序部署、调度、更新、服务发现和扩展的机制,但是该如何来保障 Kubernetes 节点的健康呢,通过智能巡检可以根据当前节点的资源状态、应用性能管理、服务故障日志等信息的检索和问题发现,从而加快事件调查、减轻工程师的压力、减少平均修复时间并改善最终用户体验。
前置条件¶
- 在观测云中开启「 容器数据采集 」
- 自建 DataFlux Func 观测云特别版 ,或者开通 DataFlux Func 托管版
- 在观测云「管理 / API Key 管理」中创建用于进行操作的 API Key
注意:如果考虑采用云服务器来进行 DataFlux Func 离线部署的话,请考虑跟当前使用的观测云 SaaS 部署在同一运营商同一地域。
开启巡检¶
在自建的 DataFlux Func 中,通过「脚本市场」安装「 观测云自建巡检(K8S 健康巡检)」并根据提示配置观测云 API Key 完成开启。
在 DataFlux Func 脚本市场中选择需要开启的巡检场景点击安装,配置观测云 API Key 和 GuanceNode 后选择部署启动脚本即可
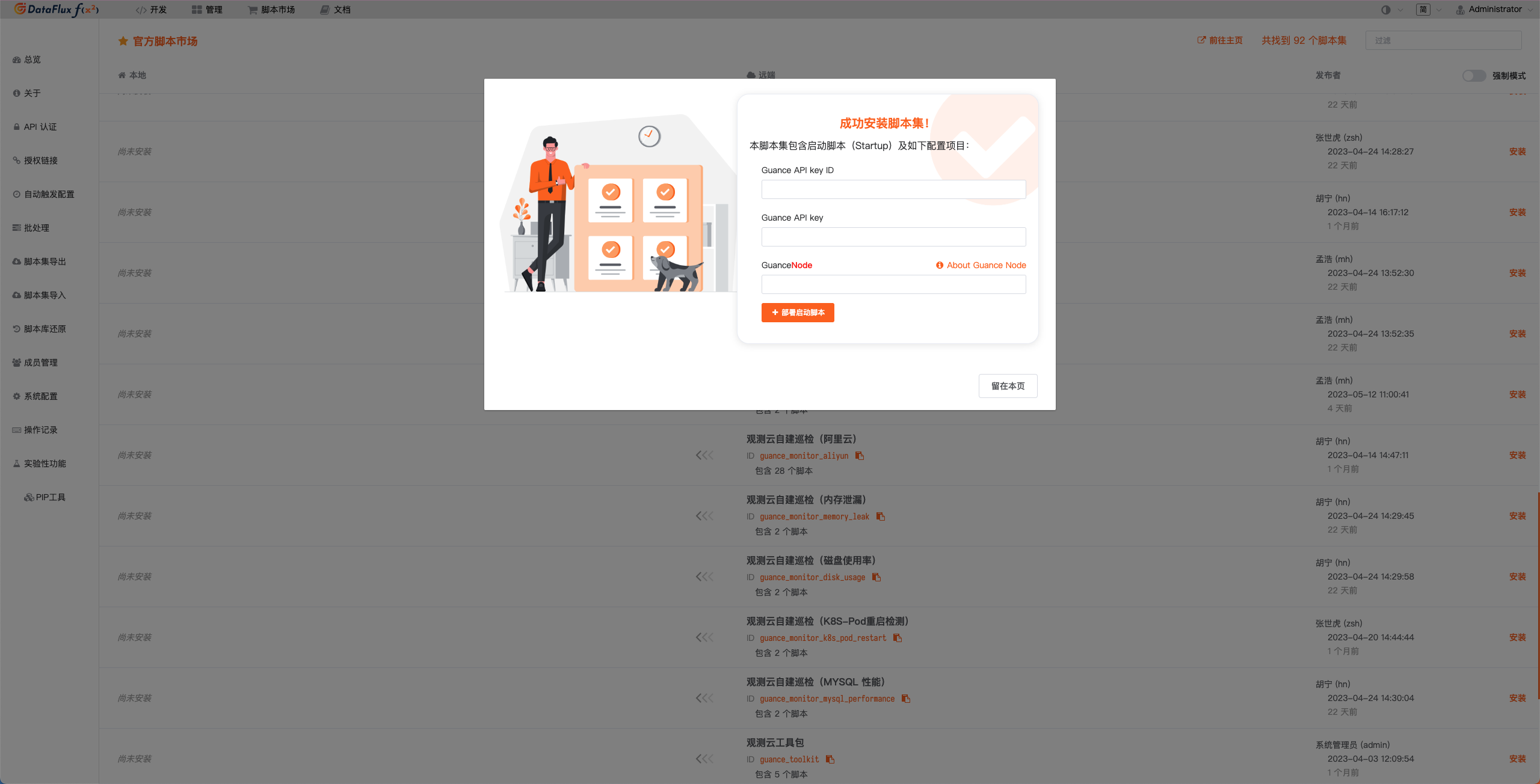
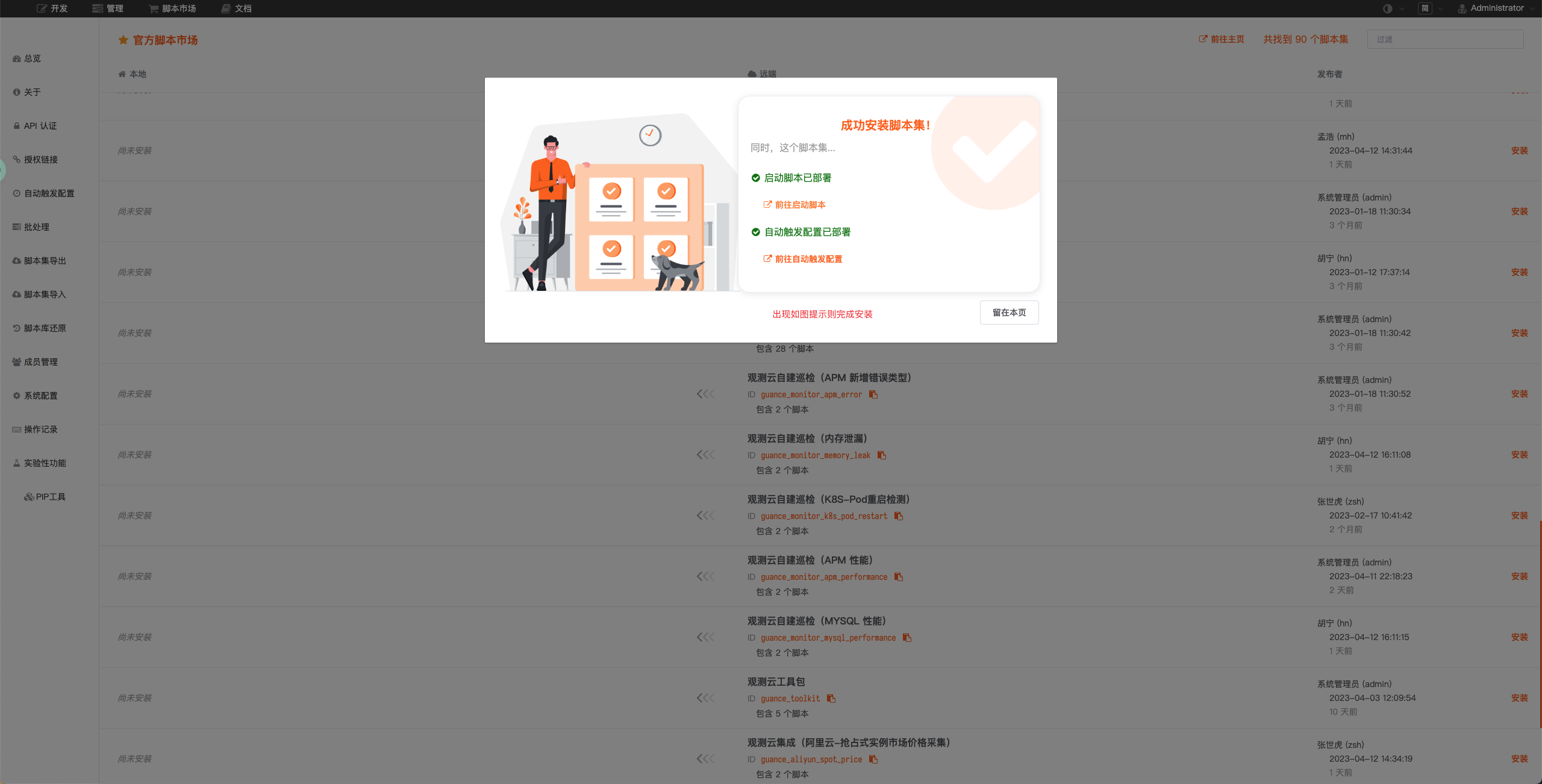
启动脚本部署成功后,会自动创建启动脚本和自动触发配置,可以通过链接直接跳转查看对应配置。
配置巡检¶
在观测云中配置巡检¶
启用/禁用¶
Kubernetes 健康巡检默认是「开启」状态,可手动「关闭」,开启后,将对配置好的 Kubernetes 健康巡检配置列表进行巡检。
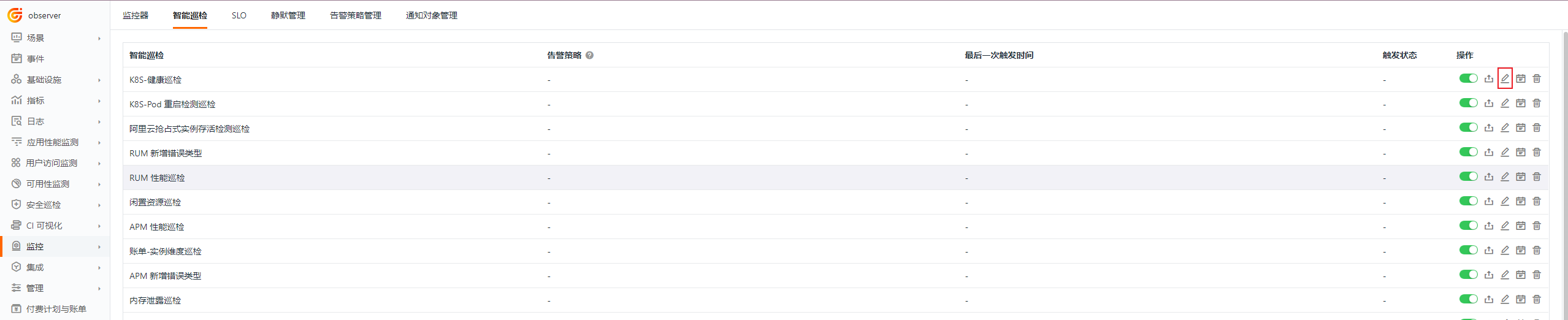
编辑¶
智能巡检「 Kubernetes 健康巡检 」支持用户手动添加筛选条件,在智能巡检列表右侧的操作菜单下,点击编辑按钮,即可对巡检模版进行编辑。
- 筛选条件:配置 cluster_name 集群名称,host 需要检测的节点
- 告警通知:支持选择和编辑告警策略,包括需要通知的事件等级、通知对象、以及告警沉默周期等
配置入口参数点击编辑后在参数配置中填写对应的检测对象点击保存开始巡检:
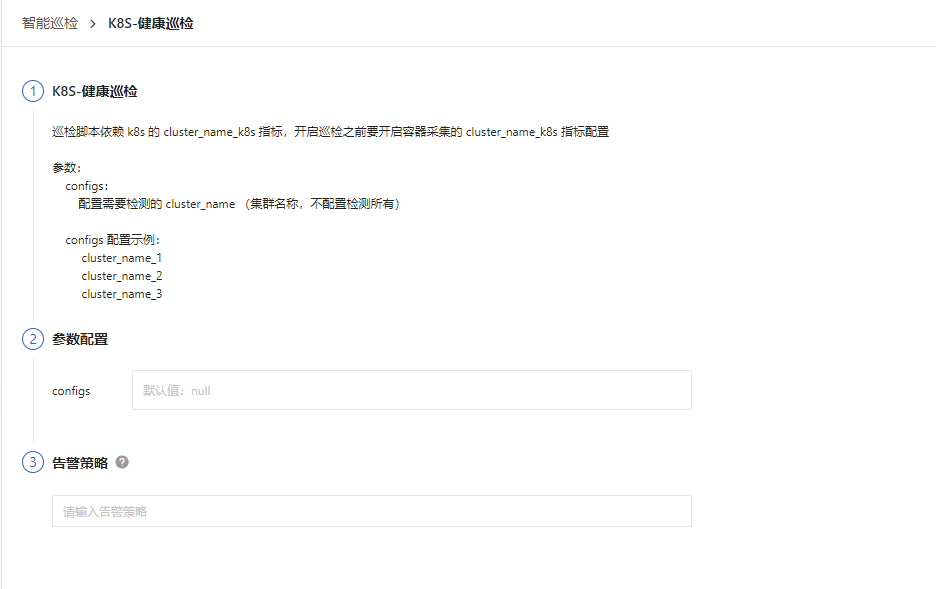
可以参考如下的 JSON 配置多个应用信息
注意:在自建的 DataFlux Func 中,编写自建巡检处理函数时也可以添加过滤条件(参考示例代码配置),要注意的是在观测云 studio 中配置的参数会覆盖掉编写自建巡检处理函数时配置的参数
在 DataFlux Func 中配置巡检¶
在 DataFlux Func 中在配置好巡检所需的过滤条件之后可以通过直接再页面中选择 run() 方法进行点击运行进行测试,在点击发布之后脚本就会正常执行了。也可以在观测云「监控 / 智能巡检」中查看或更改配置。
from guance_monitor__runner import Runner
from guance_monitor__register import self_hosted_monitor
import guance_monitor_k8s_health__main as main
# Support for using filtering functions to filter the objects being inspected, for example:
def filter_cluster(cluster_name_k8s):
'''
过滤 cluster_name_k8s,自定义符合要求 cluster_name_k8s 的条件,匹配的返回 True,不匹配的返回 False
return True|False
'''
if cluster_name_k8s in ['ningxia']:
return True
@self_hosted_monitor(account['api_key_id'], account['api_key'])
@DFF.API('K8S-健康巡检', timeout=900, fixed_crontab='*/15 * * * *')
def run(configs=None):
"""
巡检脚本依赖 k8s 的 cluster_name_k8s 指标,开启巡检之前要开启容器采集的 cluster_name_k8s 指标配置
参数:
configs:
配置需要检测的 cluster_name (集群名称,不配置检测所有)
configs 配置示例:
cluster_name_1
cluster_name_2
cluster_name_3
"""
checkers = [
k8s__health__inspection.K8SHealthCheck(configs=configs, filters=[filter_cluster]), # Support for user-configured multiple filtering functions that are executed in sequence.
]
Runner(checkers, debug=False).run()
查看事件¶
观测云会根据当前的 Kubernetes 集群的状态进行巡检当发现内存、磁盘、CPU、POD 异常时,智能巡检会生成相应的事件,在智能巡检列表右侧的操作菜单下,点击查看相关事件按钮,即可查看对应异常事件。

事件详情页¶
点击事件,可查看智能巡检事件的详情页,包括事件状态、异常发生的时间、异常名称、基础属性、事件详情、告警通知、历史记录和关联事件。
- 点击详情页右上角的「查看监控器配置」小图标,支持查看和编辑当前智能巡检的配置详情
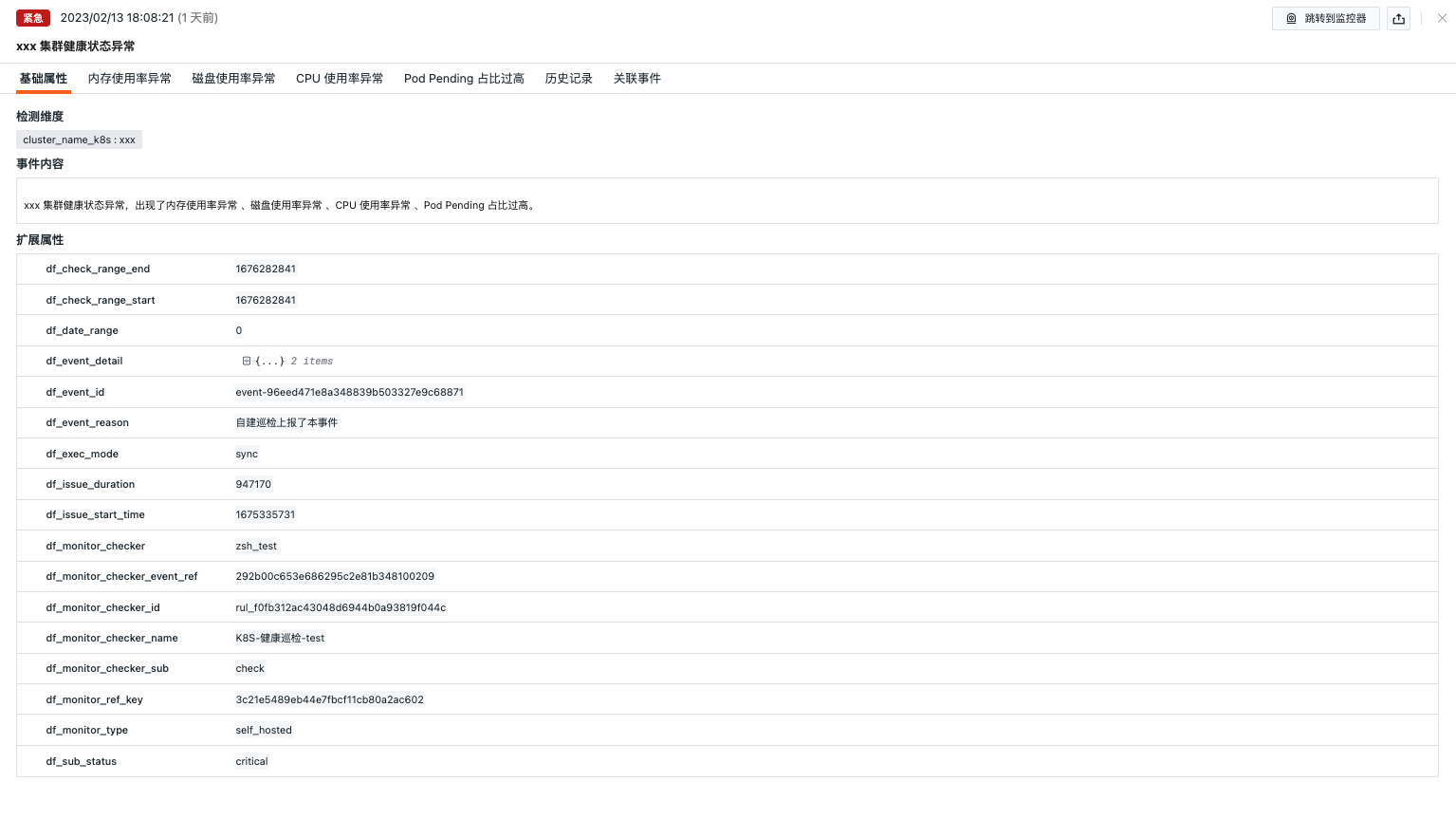
基础属性¶
- 检测维度:基于智能巡检配置的筛选条件,支持将检测维度
key/value复制、添加到筛选、以及查看相关日志、容器、进程、安全巡检、链路、用户访问监测、可用性监测以及 CI 等数据 - 扩展属性:选择扩展属性后支持以
key/value的形式复制、正向/反向筛选
事件详情¶
内存使用率异常¶
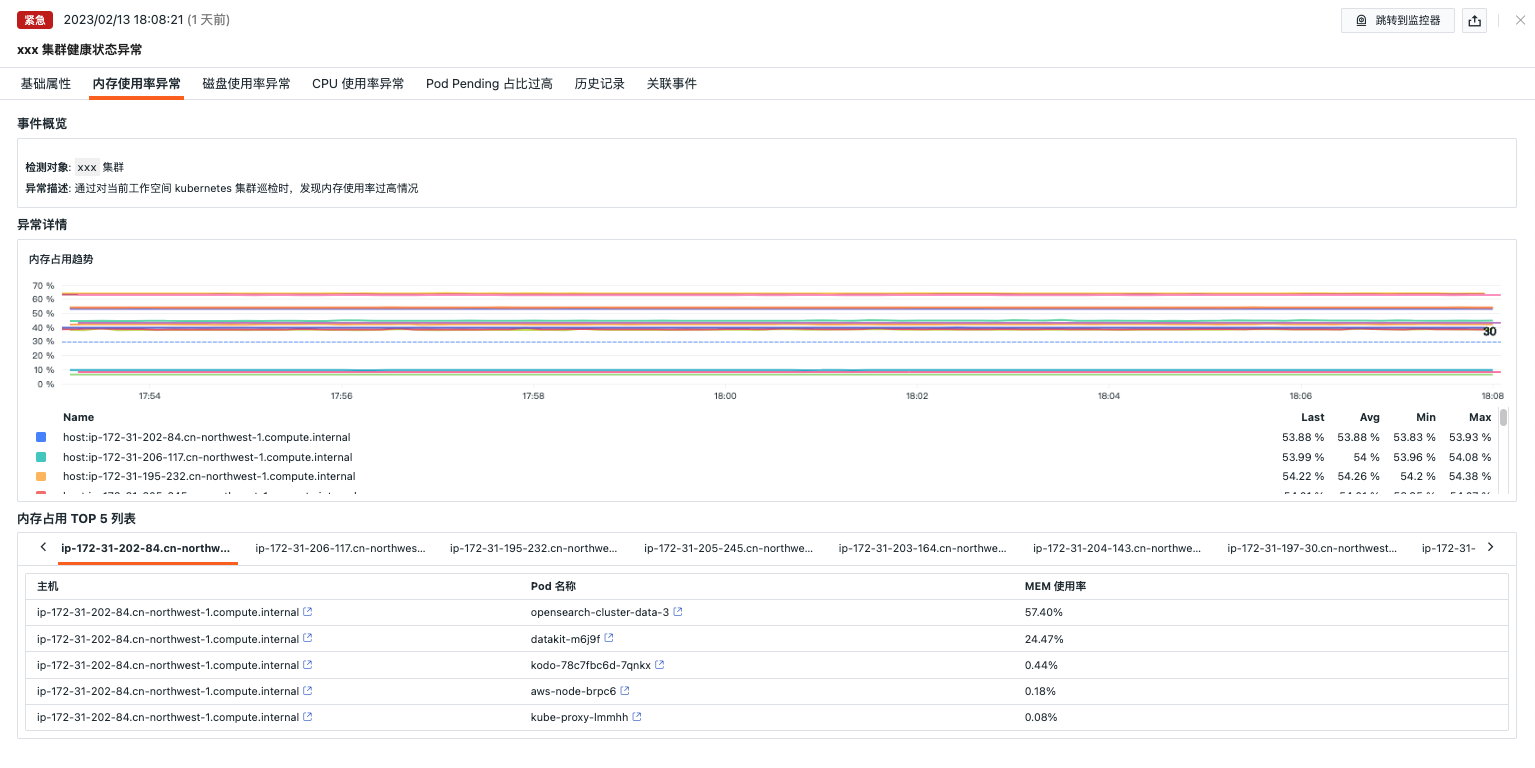
- 事件概览:描述异常巡检事件的对象、内容等
- 异常详情:可查看内存异常指标详情
- 内存占用 TOP 5 列表:可以查看内存占用前 5 的 POD 信息,可以点击 POD 跳转到 POD 详情页查看更多信息
磁盘使用率异常¶
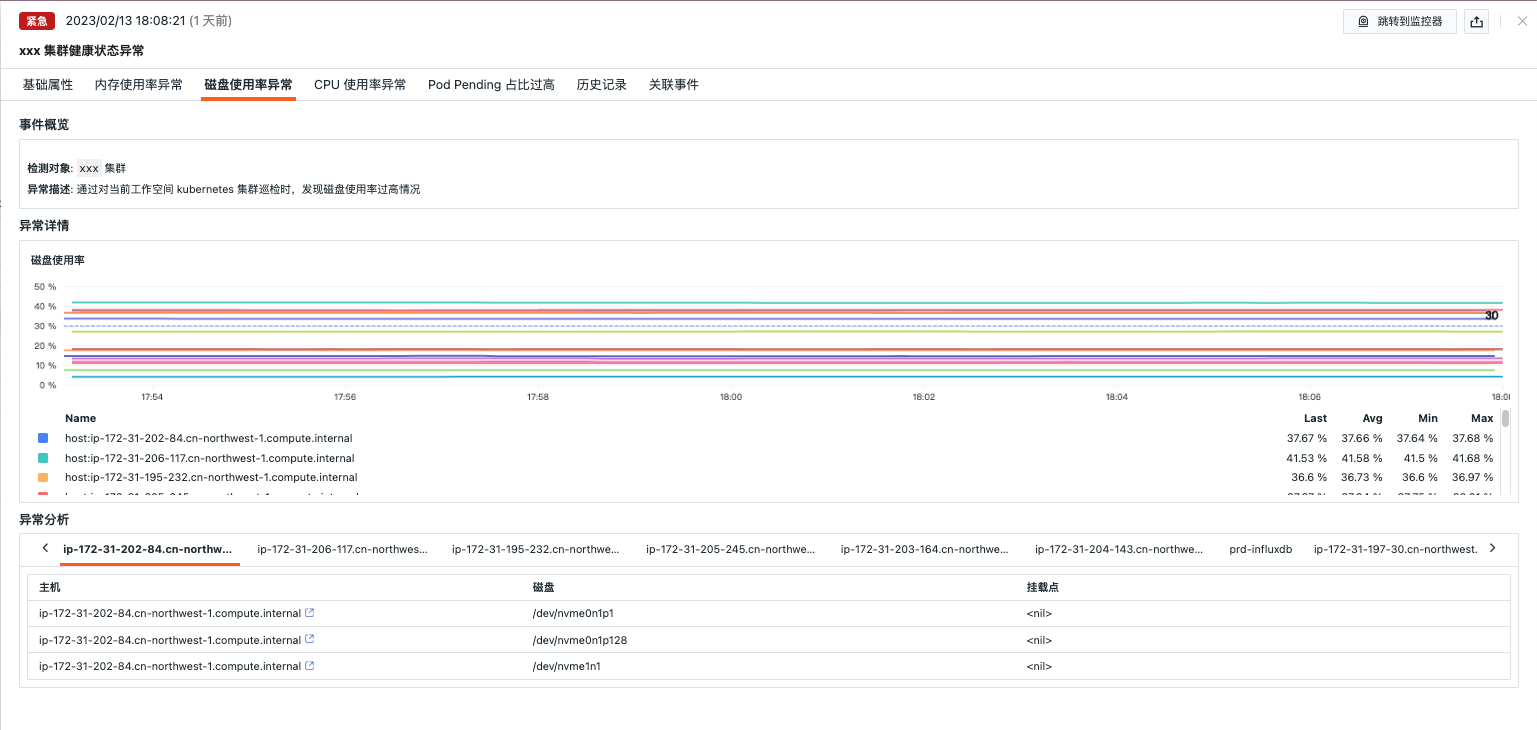
- 事件概览:描述异常巡检事件的对象、内容等
- 异常详情:可查看磁盘异常指标详情
- 异常分析:可以查看磁盘使用率异常主机的使用情况,可以点击主机跳转到主机详情页查看更多信息
CPU 使用率异常¶
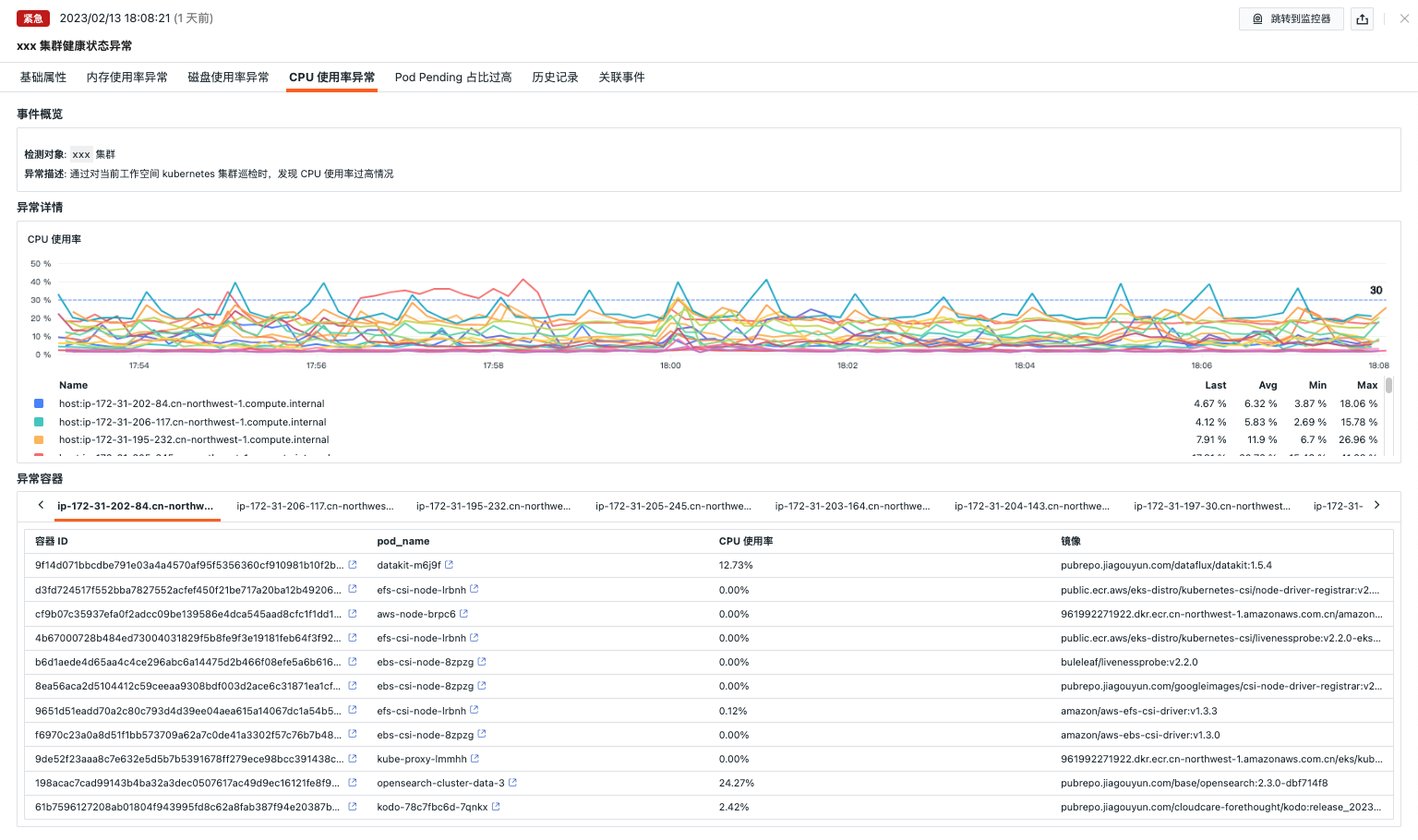
- 事件概览:描述异常巡检事件的对象、内容等
- 异常详情:可查看 CPU 使用率异常指标详情
- 异常容器:可查看 CPU 使用率前 10 的 POD 信息,可以点击 POD 跳转到 POD 详情页查看更多信息
Pod Pending 占比过高¶
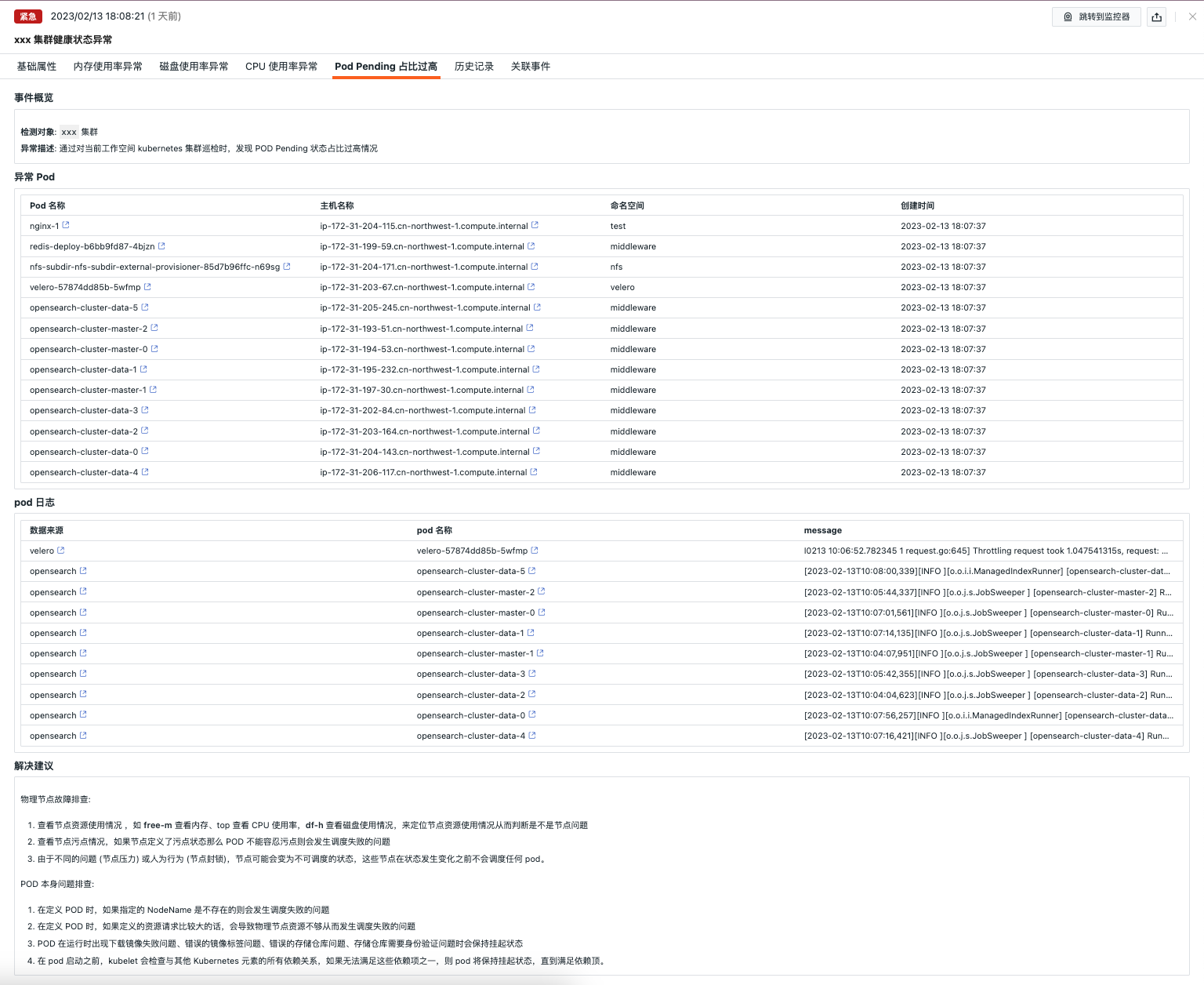
- 事件概览:描述异常巡检事件的对象、内容等
- 异常 POD:可查看异常 Pod 的详细信息,也可以通过 Pod 名称跳转到对应的 Pod 详情
- Pod 日志:可以查看对应异常 Pod 日志,可以通过日志来源、异常 Pod 跳转到相应的异常详情
历史记录¶
支持查看检测对象、异常/恢复时间和持续时长。

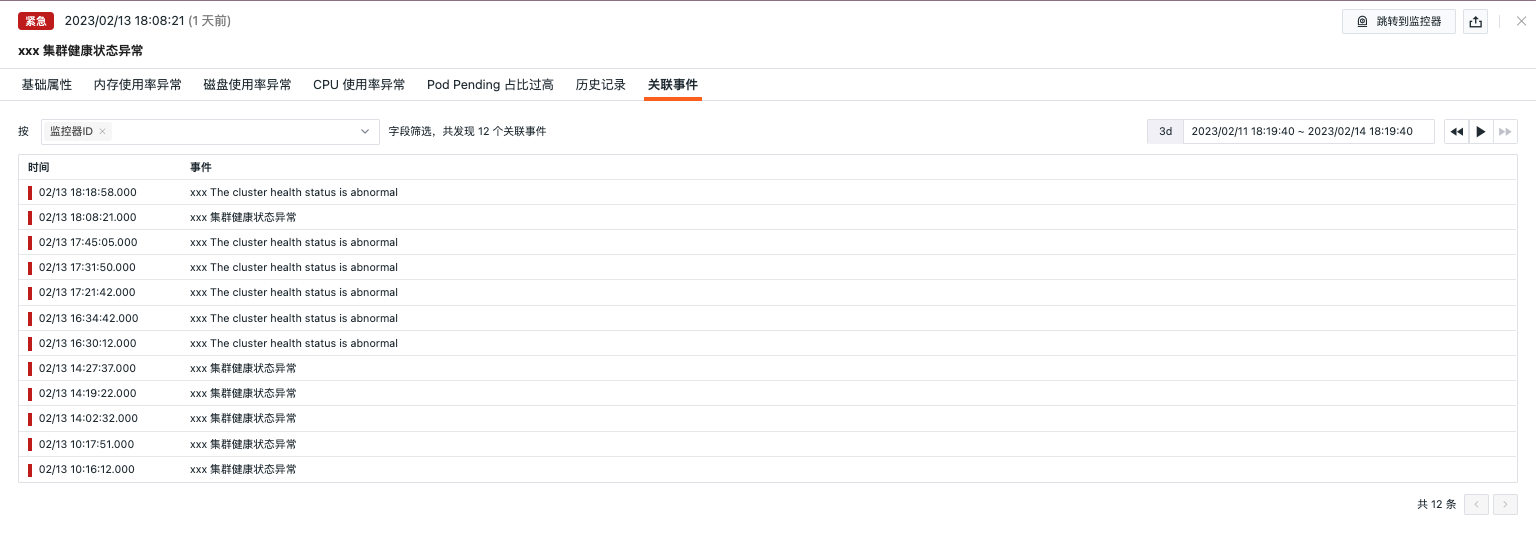
关联事件¶
支持通过筛选字段和所选取的时间组件信息,查看关联事件。
常见问题¶
1.Kubernetes 健康巡检的检测频率如何配置
- 在自建的 DataFlux Func 中,编写自建巡检处理函数时在装饰器中添加
fixed_crontab='*/15 * * * *', timeout=900, 后在「管理 / 自动触发配置」中配置。
2.Kubernetes 健康巡检触发时可能会没有异常分析
在出现巡检报告中没有异常分析时,请检查当前 datakit 的数据采集状态。
3.在巡检过程中发现以前正常运行的脚本出现异常错误
请在 DataFlux Func 的脚本市场中更新所引用的脚本集,可以通过变更日志来查看脚本市场的更新记录方便即时更新脚本。
4.在升级巡检脚本过程中发现 Startup 中对应的脚本集无变化
请先删除对应的脚本集后,再点击升级按钮配置对应观测云 API key 完成升级。
5.开启巡检后如何判断巡检是否生效
在「管理 / 自动触发配置」中查看对应巡检状态,首先状态应为已启用,其次可以通过点击执行来验证巡检脚本是否有问题,如果出现 xxx 分钟前执行成功字样则巡检正常运行生效。