DataKit Pipeline Offload¶
可以使用 DataKit 的 Pipeline Offload 功能来降低由数据处理导致的数据高延迟和主机高负载。
配置方式¶
需要在 datakit.conf 主配置文件中进行配置开启,配置见下,当前支持的目标 receiver 有 datakit-http 和 ploffload,允许配置多个 DataKit 地址以实现负载均衡。
注意:
- 当前只支持卸载日志(
Logging)类别数据的处理任务; - 在
addresses配置项中不能填写当前DataKit的地址,否则将形成循环,导致数据永远在当前DataKit中; - 请使目标
DataKit的DataWay配置与当前DataKit一致,否则数据接受方发送到其DataWay地址; - 若将
receiver配置为ploffload,接收端的 DataKit 需要开启的ploffload采集器。
请检查目标网络地址是否可以在本机访问,如目标监听的是环回地址则无法访问
参考配置:
[pipeline]
# Offload data processing tasks to post-level data processors.
[pipeline.offload]
receiver = "datakit-http"
addresses = [
# "http://<ip>:<port>"
]
若接收端 DataKit 开启 ploffload 采集器,可配置为:
[pipeline]
# Offload data processing tasks to post-level data processors.
[pipeline.offload]
receiver = "ploffload"
addresses = [
# "http://<ip>:<port>"
]
工作原理¶
DataKit 在查找到 Pipeline 数据处理脚本后将判断其是否为来自 观测云 的远程脚本,如果是则将数据转发到后级数据处理器处理(如 DataKit)。负载均衡方式为轮询。
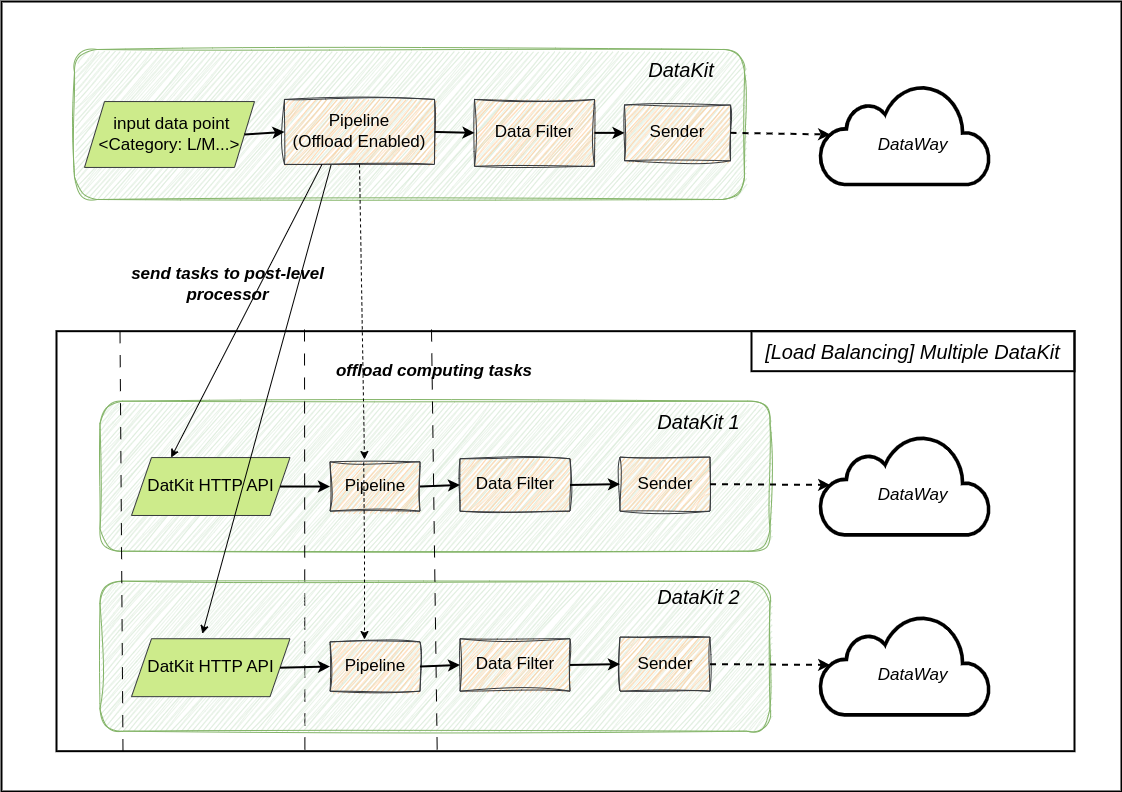
部署后级数据处理器¶
有以下几个方式部署用于接收计算任务的数据处理器(DataKit):
- 主机部署
暂不支持专用于数据处理的 DataKit;主机部署 DataKit 见文档
- 容器部署
需要设置环境变量 ENV_DATAWAY、ENV_HTTP_LISTEN,其中 DataWay 地址需要与配置了 Pipeline Offload 功能的 DataKit 一致;建议将容器内运行的 DataKit 监听的端口映射到宿主机。
参考命令: