DataKit 开发手册¶
如何新增采集器¶
假定新增采集器 zhangsan,一般遵循如下步骤:
- 在
plugins/inputs下新增模块zhangsan,创建一个input.go - 在
input.go中新建一个结构体
// 统一命名为 Input
type Input struct {
// 采集周期间隔
Interval datakit.Duration
// 用户自定义 tag
Tags map[string]string
// (可选)采集到的指标缓存,在每个采集周期必须重新 make
collectCache []*point.Point
// (可选)采集到的日志缓存,在每个采集周期必须重新 make
loggingCache []*point.Point
// 操作系统类型
platform string
// 触发停止采集器
semStop *cliutils.Sem
// (可选)和选举功能有关
Election bool `toml:"election"`
// (可选)和选举功能有关,json:"-" 是为了比对采集器不误判
pause bool `json:"-"`
// (可选)和选举功能有关,json:"-" 是为了比对采集器不误判
pauseCh chan bool `json:"-"`
}
- 该结构体实现如下几个接口,具体示例,参见
demo采集器:
// 采集器分类,比如 MySQL 采集器属于 `db` 分类
Catalog() string
// 采集器入口函数,一般会在这里进行数据采集,并且将数据发送给 `io` 模块
Run()
// 采集器配置文件示例
SampleConfig() string
// 采集器文档生成辅助结构
SampleMeasurement() []Measurement
// 采集器适用的操作系统
AvailableArchs() []string
// 读取环境变量
ReadEnv(envs map[string]string)
// (可选)单例模式,有这个的采集器,只可以存在单个实例
Singleton()
// 触发采集器停止
Terminate()
// (可选)选举功能,设定本采集器不采集数据。
Pause() error
// (可选)选举功能,设定本采集器采集数据。
Resume() error
// (可选)选举功能,设定该采集器是否参与选举。
ElectionEnabled() bool
Note
由于不断会新增一些采集器功能,新增的采集器应该尽可能实现 plugins/inputs/inputs.go 中的所有 interface。
- 建议
Run()方法的结构:
func (ipt *Input) Run() {
// (可选) ... 连接资源、准备资源
tick := time.NewTicker(ipt.Interval.Duration)
defer tick.Stop()
// 主要的采集循环流程
for {
select {
// case ipt.pause = <-ipt.pauseCh: // 选举才需要
case <-datakit.Exit.Wait():
return
case <-ipt.semStop.Wait():
// ... 其他关闭连接、资源操作
return
default:
}
start := time.Now()
// if ipt.pause { // 如果开选举,需要的代码
// l.Debugf("not leader, skipped") // 如果开选举,需要的代码
// } else { // 如果开选举,需要的代码
// 采集数据
ipt.collectCache = make([]inputs.Measurement, 0) // 也可以放到 Collect()
ipt.loggingCache = make([]*point.Point, 0) // 也可以放到 Collect()
if err := ipt.Collect(); err != nil {
l.Errorf("Collect: %s", err)
metrics.FeedLastError(inputName, err.Error())
}
// ... 上传指标和日志
// } // 如果开选举,需要的代码
// 控制循环间隔
<-tick.C
}
}
- 建议
Run()方法的结构:
func (ipt *Input) Run() {
// (可选) .. 连接资源、准备资源
tick := time.NewTicker(ipt.Interval.Duration)
defer tick.Stop()
// 主要的采集循环流程
for {
select {
// case ipt.pause = <-ipt.pauseCh: // 选举才需要
case <-datakit.Exit.Wait():
return
case <-ipt.semStop.Wait():
// ... 其他关闭连接、资源操作
return
default:
}
start := time.Now()
// if ipt.pause { // 如果开选举,需要的代码
// l.Debugf("not leader, skipped") // 如果开选举,需要的代码
// } else { // 如果开选举,需要的代码
// 采集数据
ipt.collectCache = make([]inputs.Measurement, 0) // 也可以放到 Collect()
ipt.loggingCache = make([]*point.Point, 0) // 也可以放到 Collect()
if err := ipt.Collect(); err != nil {
l.Errorf("Collect: %s", err)
metrics.FeedLastError(inputName, err.Error())
}
// ... 上传指标和日志
// } // 如果开选举,需要的代码
// 控制循环间隔
<-tick.C
}
}
- 建议
Run()方法的结构:
func (ipt *Input) Run() {
// (可选) ... 连接资源、准备资源
tick := time.NewTicker(ipt.Interval.Duration)
defer tick.Stop()
// 主要的采集循环流程
for {
select {
// case ipt.pause = <-ipt.pauseCh: // 选举才需要
case <-datakit.Exit.Wait():
return
case <-ipt.semStop.Wait():
// ... 其他关闭连接、资源操作
return
default:
}
start := time.Now()
// if ipt.pause { // 如果开选举,需要的代码
// l.Debugf("not leader, skipped") // 如果开选举,需要的代码
// } else { // 如果开选举,需要的代码
// 采集数据
ipt.collectCache = make([]inputs.Measurement, 0) // 也可以放到 Collect()
ipt.loggingCache = make([]*point.Point, 0) // 也可以放到 Collect()
if err := ipt.Collect(); err != nil {
l.Errorf("Collect: %s", err)
metrics.FeedLastError(inputName, err.Error())
}
// ... 上传指标和日志
// } // 如果开选举,需要的代码
// 控制循环间隔
<-tick.C
}
}
- 在
input.go中,新增如下模块初始化入口:
func init() {
inputs.Add("zhangsan", func() inputs.Input {
return &Input{
// 这里可初始化一堆该采集器的默认配置参数
platform: runtime.GOOS,
Interval: datakit.Duration{Duration: time.Second * 10},
semStop: cliutils.NewSem(),
Tags: make(map[string]string),
// (可选)选举功能
pauseCh: make(chan bool, inputs.ElectionPauseChannelLength),
// (可选)选举功能
Election: true,
}
})
}
- 开放选举功能,除了上述不同,还需要修改以下位置:
LineProto() 要修改
func (m *zhangsanMeasurement) LineProto() (*point.Point, error) {
// 不选举用这个
return point.NewPoint(m.name, m.tags, m.fields, point.MOpt())
// 选举用这个
return point.NewPoint(m.name, m.tags, m.fields, point.MOptElectionV2(m.election))
}
AvailableArchs() 要修改,使得文档展示「选举」图标
本采集器的配置文件 zhangsan.conf 要加上
- 在
plugins/inputs/all/all.go中新增import:
import (
... // 其它已有采集器
_ "gitlab.jiagouyun.com/cloudcare-tools/datakit/internal/plugins/inputs/zhangsan"
)
-
执行
make lint: 进行代码检查 -
执行
make ut: 运行所有的测试用例 -
执行编译,将编译完的二进制替换掉已有 DataKit,以 Mac 平台为例:
$ make
$ tree dist/
dist/
└── datakit-darwin-amd64
└── datakit # 将该 datakit 替换掉已有的 datakit 二进制,一般在 /usr/local/datakit/datakit
sudo datakit service stop # 停掉现有 datakit
sudo truncate -s 0 /var/log/datakit/log # 清空日志
sudo cp -r dist/datakit-darwin-amd64/datakit /usr/local/datakit # 覆盖二进制
sudo datakit service start # 重启 datakit
datakit monitor # datakit 运行情况监测
- 此时,一般会在 /usr/local/datakit/conf.d/<Catalog>/ 目录下有个
zhangsan.conf.sample。注意,这里的 <Catalog> 就是上面接口Catalog() string的返回值。 - 开启
zhangsan采集器,将zhangsan.conf.sample复制出一份zhangsan.conf,如果有对应的配置(如用户名、目录配置等),修改之,然后重启 DataKit - 执行如下命令检查采集器情况:
-
增加
man/docs/zh/zhangsan.md文档,这个可参考demo.md,安装里面的模板来写即可 -
对于文档中的指标集,默认是将所有能采集到的指标集以及各自的指标都列在文档中。某些特殊的指标集或指标,如果有前置条件,需在文档中做说明。
- 如果某个指标集需满足特定的条件,那么应该在指标集的
MeasurementInfo.Desc中做说明 - 如果是指标集的某个指标有特定前置条件,应该在
FieldInfo.Desc上做说明
- 如果某个指标集需满足特定的条件,那么应该在指标集的
-
建议通过执行
./b.sh进行测试版本编译发布,交付测试岗位进行测试
编译环境搭建¶
安装 Golang¶
当前 Go 版本 1.18.3
CI 设置¶
假定 go 安装在 /root/golang 目录下
- 设置目录
- 设置如下环境变量
export GO111MODULE=on
# Set the GOPROXY environment variable
export GOPRIVATE=gitlab.jiagouyun.com/*
export GOPROXY=https://goproxy.io
# 假定 golang 安装在 /root 目录下
export GOROOT=/root/golang-1.18.3
# 将 go 代码 clone 到 GOPATH 里面
export GOPATH=/root/go
export PATH=$GOROOT/bin:~/go/bin:$PATH
在 ~/.ossenv 下创建一组环境变量,填写 OSS Access Key 以及 Secret Key,用于版本发布:
export RELEASE_OSS_ACCESS_KEY='LT**********************'
export RELEASE_OSS_SECRET_KEY='Cz****************************'
export RELEASE_OSS_BUCKET='zhuyun-static-files-production'
export RELEASE_OSS_PATH=''
export RELEASE_OSS_HOST='oss-cn-hangzhou-internal.aliyuncs.com'
安装常见工具¶
treemakegoyacc:go install golang.org/x/tools/cmd/goyacc@mastergolangci-lint:go install github.com/golangci/golangci-lint/cmd/golangci-lint@v1.46.2gofumpt:go install mvdan.cc/gofumpt@v0.1.1wget- Docker
curl- LLVM: 版本 >= 10.0
- Clang: 版本 >= 10.0
- Linux 内核(>= 5.4.0-99-generic)头文件:
apt-get install -y linux-headers-$(uname -r) - cspell:
npm install -g cspell@6.31.1 - markdownlint-cli:
npm install -g markdownlint-cli@0.34.0
安装第三方库¶
gcc-multilib
# Debian/Ubuntu
sudo apt-get install -y gcc-multilib
sudo apt-get install -y linux-headers-$(uname -r)
# Centos: TODO
- IBM Db2 ODBC/CLI driver(仅限 Linux 操作系统)。方法参见 IBM Db2 的集成文档。
暂不支持
暂不支持
安装、升级测试¶
DataKit 新功能发布,大家最好做全套测试,包括安装、升级等流程。现有的所有 DataKit 安装文件,全部存储在 OSS 上,下面我们用另一个隔离的 OSS bucket 来做安装、升级测试。
大家试用下这个预设 OSS 路径:oss://df-storage-dev/(华东区域),以下 AK/SK 有需要可申请获取:
可下载 OSS Browser 客户端工具来查看 OSS 中的文件。
- AK:
LTAIxxxxxxxxxxxxxxxxxxxx - SK:
nRr1xxxxxxxxxxxxxxxxxxxxxxxxxx
在这个 OSS bucket 中,我们规定,每个开发人员,都有一个子目录,用于存放其 DataKit 测试文件。具体脚本在源码 scripts/build.sh 中。将其拷贝到 DataKit 源码根目录,稍作修改,即可用于本地编译、发布。
自定义目录运行 DataKit¶
默认情况下,DataKit 以服务的形式,运行在指定的目录(Linux 下为 /usr/local/datakit),但通过额外的方式,可以自定义 DataKit 工作目录,让它以非服务的方式运行,且从指定的目录读取配置和数据,主要用于开发的过程中调试 DataKit 的功能。
- 更新最新的代码(dev 分支)
- 编译
- 创建预期的 DataKit 工作目录,比如
mkdir -p ~/datakit/conf.d - 生成默认 datakit.conf 配置文件。以 Linux 为例,执行
-
修改上面生成的 datakit.conf:
- 填写
default_enabled_inputs,加入希望开启的采集器列表,一般是cpu,disk,mem等这些 http_api.listen地址改一下dataway.urls里面的 token 改一下- 如有必要,logging 目录/level 都改一下
- 填写
-
启动 DataKit,以 Linux 为例:
DK_DEBUG_WORKDIR=~/datakit ./dist/datakit-linux-amd64/datakit - 可在本地 bash 中新加个 alias,这样每次编译完 DataKit 后,直接运行
ddk即可(即 Debugging-DataKit)
echo 'alias ddk="DK_DEBUG_WORKDIR=~/datakit ./dist/datakit-linux-amd64/datakit"' >> ~/.bashrc
source ~/.bashrc
这样,DataKit 不是以服务的方式运行,可直接 ctrl+c 结束 DataKit
$ ddk
2021-08-26T14:12:54.647+0800 DEBUG config config/load.go:55 apply main configure...
2021-08-26T14:12:54.647+0800 INFO config config/cfg.go:361 set root logger to /tmp/datakit/log ok
[GIN-debug] [WARNING] Running in "debug" mode. Switch to "release" mode in production.
- using env: export GIN_MODE=release
- using code: gin.SetMode(gin.ReleaseMode)
[GIN-debug] GET /stats --> gitlab.jiagouyun.com/cloudcare-tools/datakit/http.HttpStart.func1 (4 handlers)
[GIN-debug] GET /monitor --> gitlab.jiagouyun.com/cloudcare-tools/datakit/http.HttpStart.func2 (4 handlers)
[GIN-debug] GET /man --> gitlab.jiagouyun.com/cloudcare-tools/datakit/http.HttpStart.func3 (4 handlers)
[GIN-debug] GET /man/:name --> gitlab.jiagouyun.com/cloudcare-tools/datakit/http.HttpStart.func4 (4 handlers)
[GIN-debug] GET /restart --> gitlab.jiagouyun.com/cloudcare-tools/datakit/http.HttpStart.func5 (4 handlers)
...
也可以直接用 ddk 执行一些命令行工具:
# 安装 IPDB
ddk install --ipdb iploc
# 查询 IP 信息
ddk debug --ipinfo 1.2.3.4
city: Brisbane
province: Queensland
country: AU
isp: unknown
ip: 1.2.3.4
测试¶
DataKit 中测试主要分成两类,一类是集成测试,一类是单元测试,它们本质上并无太大区别。只是集成测试需要更多的外部环境。
一般情况下,运行 make ut 即可运行所有的测试用例。但这些测试用例中,包括集成测试和单元测试。而集成测试需要有 Docker 参与,这里提供一个开发过程中跑测试的例子。
- 配置一个远端的 Docker,或者本机有安装 Docker 也行,如果是远端 Docker,需配置其远程连接功能。
- 做一个 shell alias,在其中启动
make ut:
额外的配置:
- 如果要排除部分 package 的测试(它可能临时无法通过测试),在
make ut后面增加对应 package 名称即可,例如:UT_EXCLUDE="gitlab.jiagouyun.com/cloudcare-tools/datakit/internal/plugins/inputs/snmp" - 如果要将测试的指标发送到观测云,添加一个 Dataway 地址以及对应工作空间的 token 即可,比如
DATAWAY_URL="https://openway.guance.com/v1/write/logging?token=<YOUR-TOKEN>"
完整的例子如下:
alias ut='REMOTE_HOST=<YOUR-DOCKER-REMOTE-HOST> make ut UT_EXCLUDE="<package-name>" DATAWAY_URL="https://openway.guance.com/v1/write/logging?token=<YOUR-TOKEN>"'
版本发布¶
DataKit 版本发布包含俩部分:
- DataKit 版本发布
- 语雀文档发布
DataKit 版本发布¶
DataKit 当前的版本发布,是在 GitLab 中实现的,一旦特定分支的代码被推送到 GitLab,就会触发对应的版本发布,详见 .gitlab-ci.yml。
在 1.2.6(含) 以前的版本中,DataKit 版本发布依赖于命令 git describe --tags 的输出。自 1.2.7 之后,DataKit 版本不再依赖这个机制,而是通过手动指定版本号,其步骤如下:
注:当前 script/build.sh 中依然依赖
git describe --tags,这只是一个版本获取策略问题,不影响主流程。
- 编辑 .gitlab-ci.yml,修改里面的
VERSION变量,如:
每次版本发布,都需要手动编辑 .gitlab-ci.yml 指定该版本号。
- 版本发布完成后,在代码上新增一个 tag
注意: Mac 版本的发布,目前只能在 amd64 架构上的 Mac 发布,因为开启了 CGO 的原因,在 GitLab 上无法发布 Mac 版本的 DataKit。其实现如下:
DataKit 版本号机制¶
- 稳定版:其版本号为
x.y.z,其中y必须是偶数 - 非稳定版:其版本号为
x.y.z,其中y必须是奇数
文档发布¶
文档的发布,只能在开发机器上发布,需安装 MkDocs。其流程如下:
- 执行 mkdocs.sh(更多命令行参数,请执行
./mkdocs.sh -h查看)
如果不指定版本,会以最新的一个 tag 名称作为版本号。
注意,如果是线上代码发布,最好保证跟线上 DataKit 当前的稳定版版本号保持一致,不然会导致用户困扰。
关于代码规范¶
这里不强调具体的代码规范,现有工具能帮助我们规范各自的代码习惯,目前引入 golint 工具,可单独检查现有代码:
在 check.err 中即可看到各种修改建议。对于误报,我们可以用 //nolint 来显式关闭:
// 显而易见,16 是最大的单字节 16 进制数,但 lint 中的 gomnd 会报错:
// mnd: Magic number: 16, in <return> detected (gomnd)
// 但此处可加后缀来屏蔽这个检查
func digitVal(ch rune) int {
switch {
case '0' <= ch && ch <= '9':
return int(ch - '0')
case 'a' <= ch && ch <= 'f':
return int(ch - 'a' + 10)
case 'A' <= ch && ch <= 'F':
return int(ch - 'A' + 10)
}
// larger than any legal digit val
return 16 //nolint:gomnd
}
何时使用
nolint,参见这里
但我们不建议频繁加上 //nolint:xxx,yyy 来掩耳盗铃,如下几种情况可用 lint:
- 中所众所周知的一些 magic number,比如 1024 表示 1K, 16 为最大的单字节值
- 一些确实无关的安全告警,比如要在代码中运行个命令,但命令参数是外面传入的,但既然 lint 工具有提及,就有必要考虑是否有可能的安全问题。
- 其它可能确实需要关闭检查的地方,慎重对待
排查 DATA RACE 问题¶
在 DataKit 中存在较多的 DATA RACE 问题,这些问题可以通过在编译 DataKit 时加入特定的 option,让编译出来的二进制在运行期间自动检测出现 DATA RACE 的代码。
编译带 DATA RACE 自动检测的 DataKit 需满足如下条件:
- 必须开启 CGO,故只能 make local(默认执行 make 即可)
- 必须传入 Makefile 变量:
make RACE_DETECTION=on
编译出来的二进制会增加一点,但无关紧要,我们只需要本地测试它。DATA RACE 自动检测有一个特征,只有代码运行到特定的代码才能检测到,故建议大家在日常测试自己的功能时,自动带上 RACE_DETECTION=on 编译,以尽早发现所有导致 DATA RACE 的代码。
DATA RACE 不一定真的导致数据错乱¶
带有 DATA RACE 检测功能的二进制运行时,如果碰到 >=2 的 goroutine 访问同一份数据,且其中一个 goroutine 执行的是 write 逻辑,那么会在终端打印出类似如下的代码:
==================
WARNING: DATA RACE
Read at 0x00c000d40160 by goroutine 33:
gitlab.jiagouyun.com/cloudcare-tools/datakit/vendor/github.com/GuanceCloud/cliutils/dialtesting.(*HTTPTask).GetResults()
/Users/tanbiao/go/src/gitlab.jiagouyun.com/cloudcare-tools/datakit/vendor/github.com/GuanceCloud/cliutils/dialtesting/http.go:208 +0x103c
...
Previous write at 0x00c000d40160 by goroutine 74:
gitlab.jiagouyun.com/cloudcare-tools/datakit/vendor/github.com/GuanceCloud/cliutils/dialtesting.(*HTTPTask).Run.func2()
/Users/tanbiao/go/src/gitlab.jiagouyun.com/cloudcare-tools/datakit/vendor/github.com/GuanceCloud/cliutils/dialtesting/http.go:306 +0x8c
...
通过这两个信息,即可得知两处的代码共同操作了某个数据对象,且其中至少有一个是 Write 操作。但要注意的是,这里打印的只是 WARNING 信息,即表示这段代码不一定会导致数据问题,最终的问题还需需要我们人工来甄别,比如以下的代码并不会有数据问题:
排查 DataKit 内存泄露¶
Version-1.9.2 已默认开启 pprof 功能。
编辑 datakit.conf,顶部增加如下配置字段即可开启 DataKit 远程 pprof 功能:
如果是 DaemonSet 安装 DataKit,可注入环境变量:
重启 DataKit 生效。
获取 pprof 文件¶
# 下载当前 DataKit 活跃内存 pprof 文件
wget http://<datakit-ip>:6060/debug/pprof/heap
# 下载当前 DataKit 总分配内存 pprof 文件(含已经被释放的内存)
wget http://<datakit-ip>:6060/debug/pprof/allocs
这里的 6060 端口是固定死的,暂时无法修改
另外通过 web 访问 http://<datakit-ip>:6060/debug/pprof/heap?=debug=1 也能查看一些内存分配信息。
查看 pprof 文件¶
下载到本地后,运行如下命令,进入交互命令后,可输入 top 即可查看内存消耗的 top10 热点:
$ go tool pprof heap
File: datakit
Type: inuse_space
Time: Feb 23, 2022 at 9:06pm (CST)
Entering interactive mode (type "help" for commands, "o" for options)
(pprof) top <------ 查看 top 10 的内存热点
Showing nodes accounting for 7719.52kB, 88.28% of 8743.99kB total
Showing top 10 nodes out of 108
flat flat% sum% cum cum%
2048.45kB 23.43% 23.43% 2048.45kB 23.43% gitlab.jiagouyun.com/cloudcare-tools/datakit/vendor/github.com/alecthomas/chroma.NewLexer
1031.96kB 11.80% 35.23% 1031.96kB 11.80% regexp/syntax.(*compiler).inst
902.59kB 10.32% 45.55% 902.59kB 10.32% compress/flate.NewWriter
591.75kB 6.77% 52.32% 591.75kB 6.77% bytes.makeSlice
561.50kB 6.42% 58.74% 561.50kB 6.42% gitlab.jiagouyun.com/cloudcare-tools/datakit/vendor/golang.org/x/net/html.init
528.17kB 6.04% 64.78% 528.17kB 6.04% regexp.(*bitState).reset
516.01kB 5.90% 70.68% 516.01kB 5.90% io.glob..func1
513.50kB 5.87% 76.55% 513.50kB 5.87% gitlab.jiagouyun.com/cloudcare-tools/datakit/vendor/github.com/gdamore/tcell/v2/terminfo/v/vt220.init.0
513.31kB 5.87% 82.43% 513.31kB 5.87% gitlab.jiagouyun.com/cloudcare-tools/datakit/vendor/k8s.io/apimachinery/pkg/conversion.ConversionFuncs.AddUntyped
512.28kB 5.86% 88.28% 512.28kB 5.86% encoding/pem.Decode
(pprof)
(pprof) pdf <------ 输出成 pdf,即在当前目录下会生成 profile001.pdf
Generating report in profile001.pdf
(pprof)
(pprof) web <------ 直接在浏览器上查看,效果跟 PDF 一样
通过
go tool pprof -sample_index=inuse_objects heap可看对象的分配情况,详询go tool pprof -help。
用同样的方式,可查看总分配内存 pprof 文件 allocs。PDF 的效果大概如下:
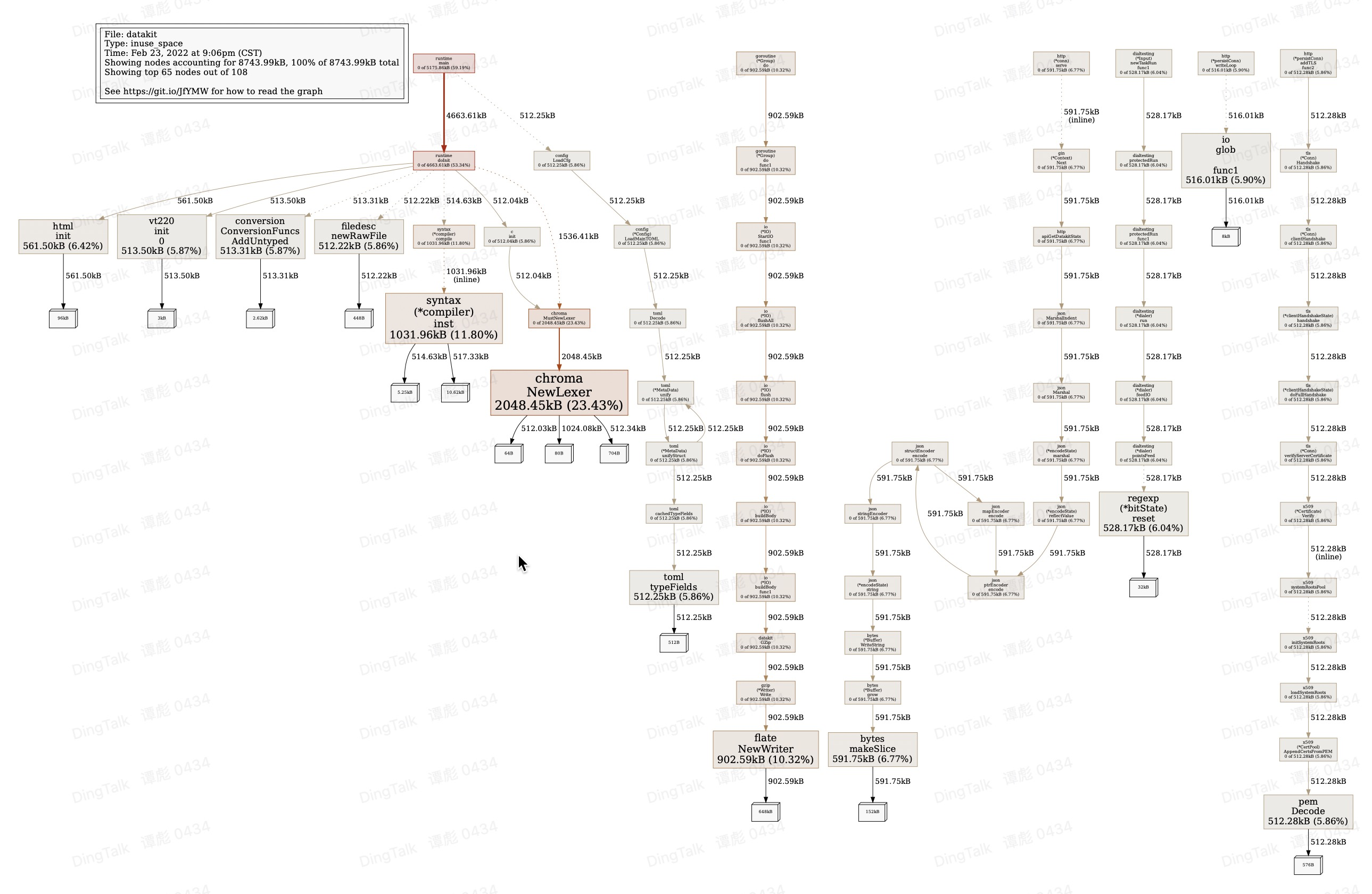
更多 pprof 的使用方法,参见这里。
DataKit 辅助功能¶
除了官方文档列出的部分辅助功能外,DataKit 还支持其它功能,这些主要在开发过程中使用。
检查 sample config 是否正确¶
datakit check --sample
------------------------
checked 52 sample, 0 ignored, 51 passed, 0 failed, 0 unknown, cost 10.938125ms
导出文档¶
将 DataKit 现有文档,导出到指定目录,同时指定文档版本,将文档中标记为 TODO 的用 - 代替,同时忽略采集器 demo
man_version=`git tag -l | sort -nr | head -n 1` # 获取最近发布的 tag 版本
datakit doc --export-docs /path/to/doc --version $man_version --TODO "-" --ignore demo
接入组件健康检查¶
采集器可通过 internal/health 注册组件实例,并通过统一的 Reporter 接口上报存活或恢复失败。组件退出时应注销对应实例。健康状态由 /v1/health 统一输出,不应为 liveness 单独增加 Prometheus 指标。只有无法自行恢复、需要重启 DataKit 的组件才应注册。