时间线计费项¶
更新说明¶
观测云已于 2023 年 4 月 23 日完成了 GuanceDB 自研时序数据库 的升级上线。全新的 GuanceDB 与旧的时序引擎不同,是一种单指标的时序引擎,虽然其仍然存在指标集(Measurement)的概念,但每个指标将拥有独立的时间线。
由此,观测云对于时间线的统计逻辑也发生了改变:
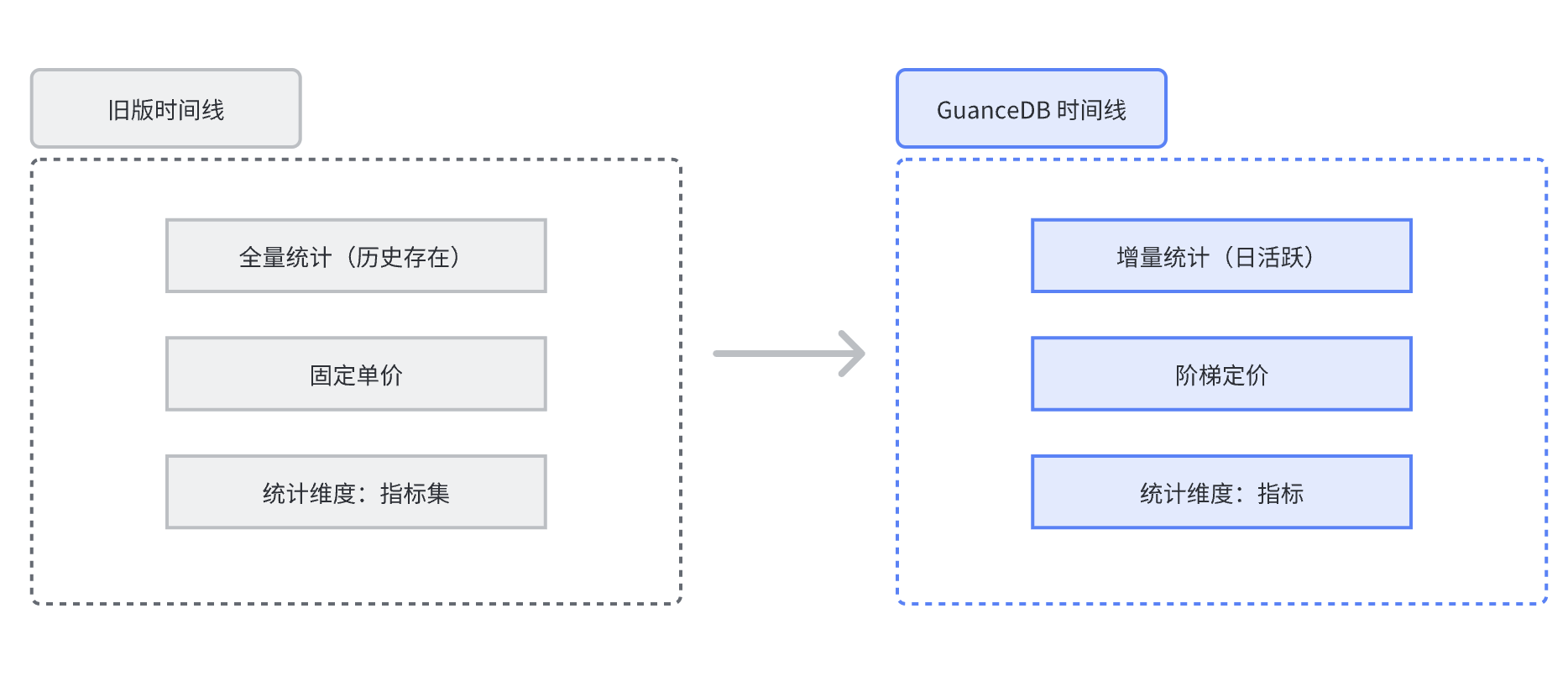
在新逻辑下:
-
全量统计变更为增量统计:即,从之前统计用户历史存储的所有数据带来产生的时间线变更成每一天可能会产生的活跃的时间线的数量;
-
固定单价变更为阶梯定价:即,阶梯定价会根据选择的数据保存策略来对应不同的价格;
-
统计维度由指标集变更为指标:即,之前的统计维度基于指标集维度来统计指标集下的标签组合。在新的观测 GuanceDB 时间线里,观测云基于指标维度来统计当天上报的数据里所有的标签产生的组合数量。
不再是之前统计用户存储在时序数据库内对应的时间线数量,其单价相对来说较为固定;同时基于指标集的维度来统计指标集下所有的标签组合。
您首先需要知道¶
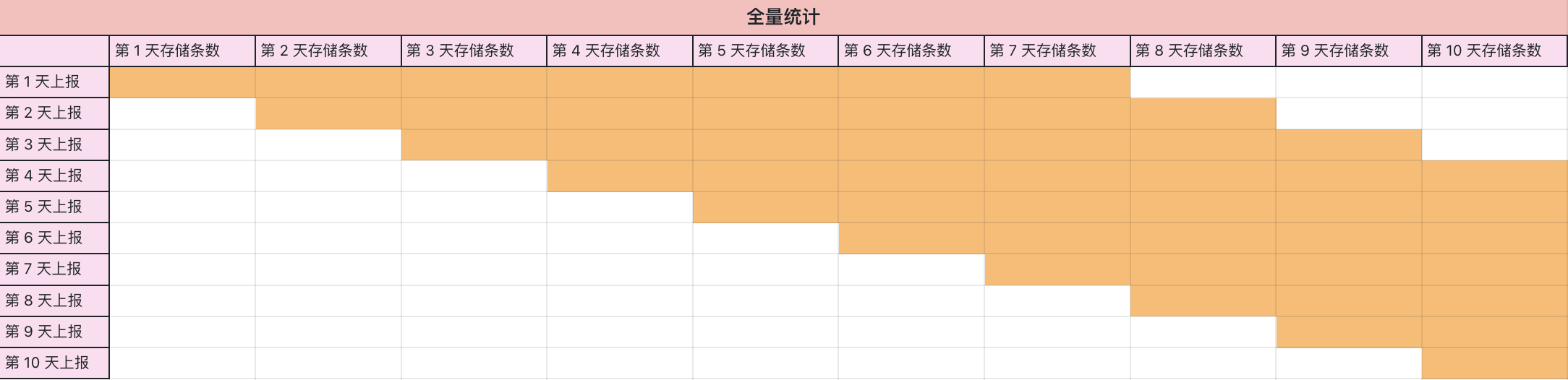
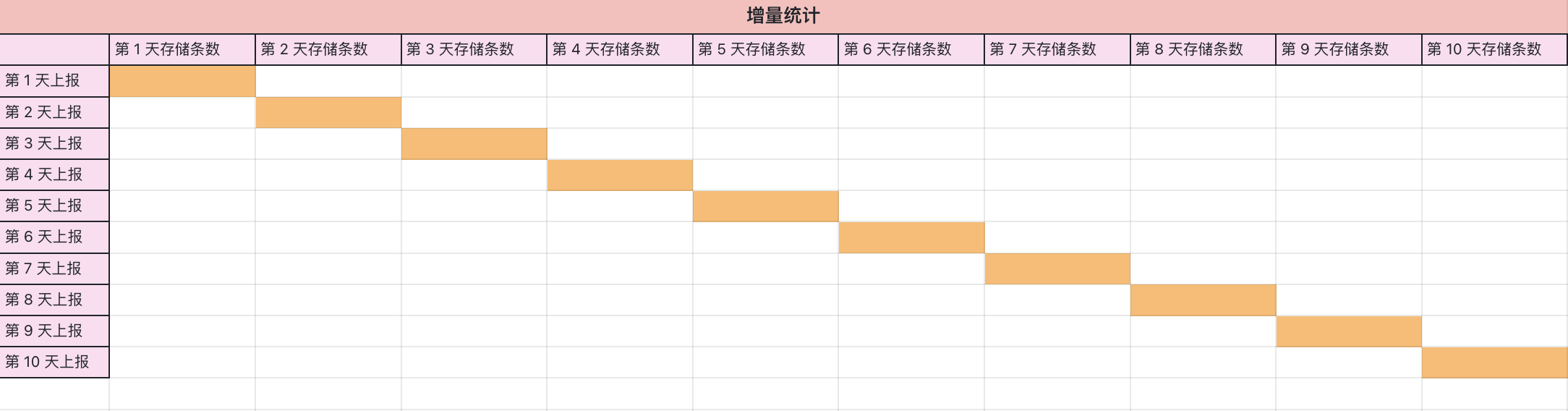
两张图告诉您,如何理解全量统计与增量统计:
观测云的时序数据库主要涉及到以下几个基本概念:
| 名词 | 说明 |
|---|---|
| 日活跃时间线 | 指当天产生新指标数据的时间线数量。我们将当天有产生数据的时间线作为统计的依据,即,如果您停止数据采集,在新的一天将不会收取时间线的费用,而之前采集的指标数据仍然可以被查询。 |
| 指标集 | 一般意义上用于表示某种统计值对应的一个集合,从原理上讲更像关系型数据库中的 table 概念。 |
| 数据点 | 应用于指标数据上报场景则指代一条指标数据样本,具体可类比关系型数据库中的 row 数据。 |
| 时间 | 时间戳,代表数据点产生的时间,这里也可以理解为 DataKit 采集到某条指标数据产生行协议上报的时间。 |
| 指标 | Field,一般情况下存放的是会随着时间戳的变化而变化的数值类型的数据。例如我们在 CPU 指标集中常见的 cpu_total,cpu_use,cpu_use_pencent 等都是指标。 |
| 标签 | Tags,一般存放的是并不随着时间戳变化的属性信息。例如我们在 CPU 指标集中常见的 host、project 等字段都是标签属性,用来标识指标的实际对象属性。 |
计费产生¶
通过 DataKit 采集指标数据上报到某个工作空间。特指 DQL 中 M 为 NameSpace 查询得到的数据。
数据保存策略¶
| 增量统计 | |||||||
|---|---|---|---|---|---|---|---|
| 数据存储策略 | 3 天 | 7 天 | 14 天 | 30 天 | 180 天 | 360 天 | |
| 单价(每千条) | 中国站(中国区) | ¥ 0.6 | ¥ 0.7 | ¥ 0.8 | ¥ 1 | ¥ 4 | ¥ 7 |
| 中国站(海外区-俄勒冈) | ¥ 1.6 | ¥ 1.8 | ¥ 2.2 | ¥ 2.4 | ¥ 8 | ¥ 14 | |
| 国际站 | $ 0.23 | $ 0.26 | $ 0.32 | $ 0.35 | $ 1.2 | $ 2 |
计费项统计¶
以每小时的时间间隔统计当天内新增的时间线数量,最终得到 24 个数据点之后,取最大值作为实际计费数量。
示例¶
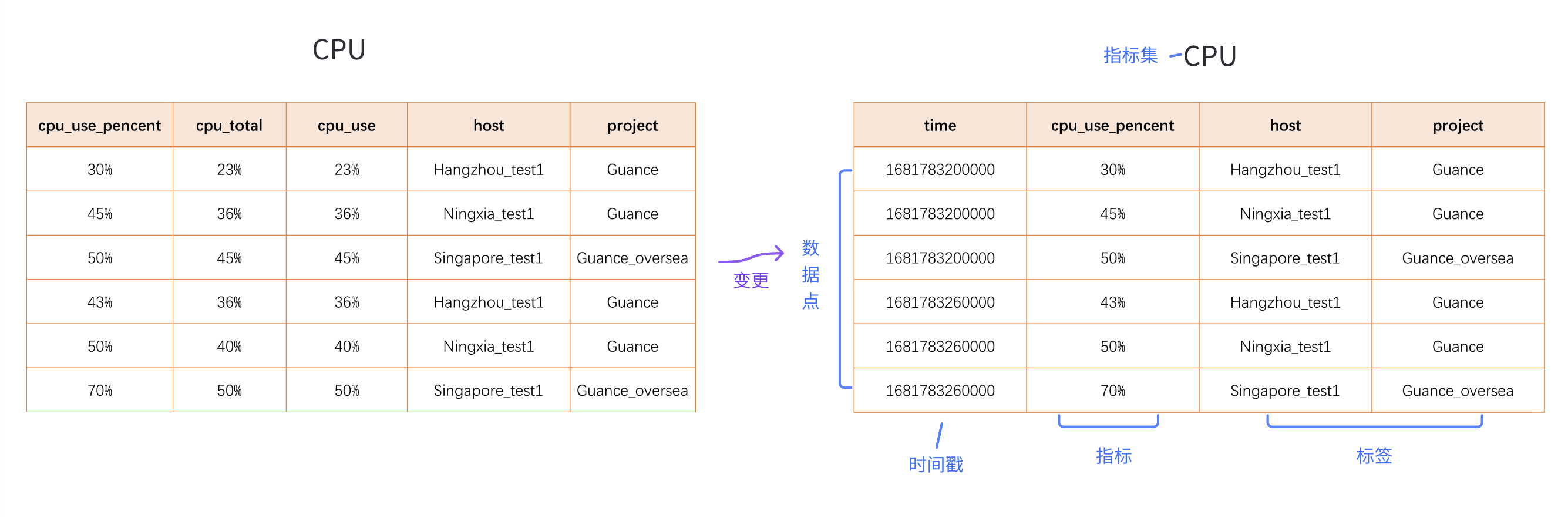
以上图为例:
旧版的时间线统计逻辑中,不包含指标、数据点的概念,仅针对当前指标集的标签组合做数量统计。所以在之前我们很难帮助用户量化具体时间线的数量。
而变更后 GuanceDB 的时间线逻辑是根据每个指标对应的标签组合统计的,所以按照最新的逻辑我们可以得出:指标集 CPU 中基于单个指标存在共 6 个数据点,每个数据点都有一个时间字段:time,一个指标: cpu_use_pencent,两个标签: host、 project。第一行和第四行数据均为 “host” 名称是 Hangzhou_test1 且 “project” 归属于 Guance 的 CPU 使用率(cpu_use_pencent)情况,依此类推第二行和第五行表示 “host” 名称是 Ningxia_test1 且 “project” 归属于 Guance 的 CPU 使用率,第三行和第六行 “host” 名称是 Singapore_test1 且 “project” 归属于 Guance_oversea 的 CPU 使用率。
根据上述时间线的统计数据,基于 cpu_use_pencent 这一指标的时间线组合一共有 3 种,分别是:
"host":"Hangzhou_test1","project":"Guance"
"host":"Ningxia_test1","project":"Guance"
"host":"Singapore_test1","project":"Guance_oversea"
依此类似如需统计当前工作空间内所有的指标的时间线,只需将实际统计到指标的时间线数量求和即可得到。
因此,在时间线数量上,需要注意:
在观测云时间线逻辑变更后,每日产生的时间线组合会有所增加,但从实际的数据表现上来看,每日会收费的时间线数量会有所减少。原因在于,当时间线统计的范围是全量统计,假设数据的数据保存时长是 7 天,那么到第七天、第八天、第九、第十天的时候,该数据已经到达相对稳定的一个状态。也就是说,如果后续要去评估时间线的数量,永远是固定根据这一个区间内所有的时间线数量去做收费逻辑的统计。
但变更为增量统计后,观测云会根据当天的指标数据去计算其日活跃的时间线的数量,所以从总体的量级来看,基于单个指标级,时间线组合数量会有所增加,但需要收费的数量相对来讲呈减少趋势。并且考虑到数量的增加,GuanceDB 的时间线定价有基础定价更改为梯度定价,也就是由原来的 3 元/每千条变更为 0.6 元/每千条,即根据用户去选择不同的数据存储策略来对应不同的单价。因此,整体换算下来,时间线的计费相比从前有所下降。
费用计算公式¶
天费用 = 实际计费数量 / 1000 * 单价(根据数据存储策略应用对应单价)
假设用户安装了一台主机 DataKit,并且默认指标数据采集。该主机每天能产生 600 条日活跃时间线,那么可以从以下步骤来进行测算:
-
要安装 DK 的主机数量有多少?
-
数量 * 600 = 日活跃的时间线数量
-
对应数据保存策略的单价 * 日活跃的时间线数量 / 1000 = 日预估费用