Pipeline Data Processing of Various Categories¶
Since DataKit 1.4.0, you can directly operate DataKit to collect data through the built-in Pipeline function, supporting current all data types
Attention
- Pipeline is applied to all data and is currently in the experimental stage, so there is no guarantee that incompatible adjustments will be made to the mechanism or behavior later.
- Even data reported through the DataKit API supports Pipeline processing.
- Using Pipeline to process the existing data (especially non-logging data) may destroy the existing data structure and lead to abnormal performance of the data on Guance Cloud.
- Before applying Pipeline, be sure to use the Pipeline debugging tool to confirm that the data processing is as expected.
Pipeline can do the following on the data collected by DataKit:
- Add, delete, and modify the values or data types of field and tag
- Change field to tag
- Modify measurement name
- Drop current data(drop())
- Terminate the run of the Pipeline script(exit())
- ...
Input Data Structure¶
All types of data will be encapsulated into a Point structure before being processed by the Pipeline script, and its structure can be regarded as:
struct Point {
Name: str # Equivalent to the measurement name of Metric data,
# the source of Logging (log) data
# the source of Network and
# the class of Object/CustomObject ...
Tags: map[str]str # Store all tags of the data.
# For Metric data, the boundary between tag and field is blurred
Fields: map[str]any # Store all fields of the data.
Time: int64 # As the time of data, it is usually interpreted
# as the timestamp of data generation, in nanoseconds
DropFlag: bool # Marks whether this data should be dropped
}
Taking a piece of nginx log data as an example, the data generated after being collected by the log collector as the input of the Pipeline script is roughly as follows:
Point {
Name: "nginx"
Tags: map[str]str {
"host": "your_hostname"
},
Fields: map[str]any {
"message": "127.0.0.1 - - [12/Jan/2023:11:51:38 +0800] \"GET / HTTP/1.1\" 200 612 \"-\" \"curl/7.81.0\""
},
Time: 1673495498000123456,
DropFlag: false,
}
Prompt:
-
Where
namecan be modified by the functionset_measurement(). -
In the tags/fields map of point, Any key cannot and will not appear in tags and fields at the same time;
-
You can read the value of the corresponding key in the tags/fields map of the point through a custom identifier or the function
get_key()in the Pipeline; but modifying the value of the key in Tags or Fields needs to be done through other built-in functions, such asadd_keyand other functions; where_can be regarded as an alias of the keymessage. -
After the script finishes running, if there is a key named
timein the tags/fields map of point, it will be deleted; if its value is int64 type, its value will be assigned to the time of point and then deleted. If time is a string, you can try to convert it to int64 using the functiondefault_time(). -
You can use the
drop()function to mark the input Point as being dropped. After the script execution ends, the data will not be uploaded.
Pipeline Script Storage, Indexing, and Matching¶
Script Storage and Indexing¶
Currently, Pipeline scripts are divided into four namespaces by source, with indexing priority decreasing, as shown in the following table:
| Namespace | table of contents | Supported data categories | describe |
|---|---|---|---|
remote |
[DataKit installation path]/pipeline_remote | CO, E, L, M, N, O, P, R, S, T | Guance Cloud console management script |
confd |
[DataKit installation path]/pipeline_cond | CO, E, L, M, N, O, P, R, S, T | Confd-managed scripts |
gitrepo |
[DataKit installation path]/pipeline_gitrepos/[repo-name] | CO, E, L, M, N, O, P, R, S, T | Git-managed scripts |
default |
[DataKit installation path]/pipeline | CO, E, L, M, N, O, P, R, S, T | DataKit-generated scripts or user-written |
Notice:
- Do not modify the automatically generated collector default script in the pipeline directory, if modified, the script will be overwritten after DataKit starts;
- It is recommended to add local scripts corresponding to the data category under the pipeline/[category]/ directory;
- Except the pipeline directory, please do not modify other script directories (
remote,confd,gitrepo) in any form.
When DataKit selects the corresponding Pipeline, the index priority of the scripts in these four namespaces is decreasing. Take cpu metric set as an example, when metric/cpu.p is required, DataKit searches in the following order:
pipeline_remote/metric/cpu.ppipeline_confd/metric/cpu.pgitrepo/<repo-name>/metric/cpu.ppipeline/metric/cpu.p
Note: Here
<repo-name>depends on your git warehouse name.
We will create indexes for scripts under each data category separately. This function will not cause the use() function to refer to scripts across namespaces; the implementation of Pipeline's script storage and script index is shown in the figure below. When creating a script index , scripts in higher-priority namespaces will shadow lower-priority ones:
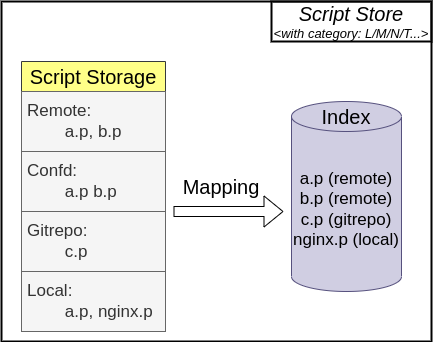
The above four types of Pipeline directories store Pipeline scripts as follows:
├── pattern <-- dedicated to custom patterns
├── apache.p
├── consul.p
├── sqlserver.p <--- pipeline in all top-level directories defaults to logs for compatibility with history settings
├── tomcat.p
├── other.p
├── custom_object <--- dedicated pipeline storage directory for custom objects
│ └── some-object.p
├── keyevent <--- pipeline storage directory dedicated to events
│ └── some-event.p
├── logging <--- pipeline storage directory dedicated to logs
│ └── nginx.p
├── metric <--- dedicated pipeline storage directory for time series metrics
│ └── cpu.p
├── network <--- pipeline directory dedicated to network metrics
│ └── ebpf.p
├── object <--- object-specific pipeline storage directory
│ └── HOST.p
├── rum <--- pipeline storage directory dedicated to RUM
│ └── error.p
├── security <--- pipeline storage directory dedicated to scheck
│ └── scheck.p
└── tracing <--- pipeline storage directory dedicated to APM
└── service_a.p
Data and script matching strategy¶
There are four matching policies for data and script names, which will be judged from the 4th (highest priority) to the 1st, and if the high priority policy is satisfied, the low priority policy will not be executed:
- Add the script file extension
.pof Pipeline to the data characteristic string generated according to the input data, and find the script of the corresponding category. - The default script of the data category set for all data under this category in the observation cloud console.
- The mapping relationship between data and scripts set in the observation cloud console.
- Specify the script in the collector configuration file.
All of the above data and script matching strategies depend on the data feature strings of the data; for different types of data, the generation strategies of the data feature strings are different:
- Generate a data feature string with a specific point tag/field:
- APM's Tracing and Profiling category data:
- Use the value of
servicein tags/fields to generate a data feature string. For example, if DataKit collects a piece of data, if the value ofserviceisservice-a,service-awill be generated, corresponding to the script nameservice-a.p, and then it will be in the script of the Tracing/Profiling category Search under the index;
- Use the value of
-
Scheck's Security category data signature string:
- Use the value of
categoryin tags/fields to generate a data feature string. For example, DataKit receives a piece of Security data, if the value ofcategoryissystem, it will generatesystem, corresponding to the script namesystem.p.
- Use the value of
-
Generate data feature string with specific point tag/field and point name:
-
RUM category data for RUM:
- Use the value of
app_idin tags/fields and the value of point name to generate a data feature string; take the value of point name asactionas an example, generate<app_id>_action, corresponding to Script name<app_id>_action.p;
- Use the value of
-
Use point name to generate data feature string:
- Logging/Metric/Network/Object/... and all other categories:
- Both use point name to generate data feature strings. Taking the timing index set
cpuas an example,cpuwill be generated, corresponding to the scriptcpu.p; and for the host object whose class isHOSTin the object data,HOSTwill be generated, corresponding to the scriptHOST. p.
- Both use point name to generate data feature strings. Taking the timing index set
Pipeline Processing Sample¶
The sample script is for reference only. Please write it according to the requirements for specific use.
Processing Time Series Data¶
The following example is used to show how to modify tag and field with Pipeline. With DQL, we can know the fields of a CPU measurement as follows:
dql > M::cpu{host='u'} LIMIT 1
-----------------[ r1.cpu.s1 ]-----------------
core_temperature 76
cpu 'cpu-total'
host 'u'
time 2022-04-25 12:32:55 +0800 CST
usage_guest 0
usage_guest_nice 0
usage_idle 81.399796
usage_iowait 0.624681
usage_irq 0
usage_nice 1.695563
usage_softirq 0.191229
usage_steal 0
usage_system 5.239674
usage_total 18.600204
usage_user 10.849057
---------
Write the following Pipeline script,
# file pipeline/metric/cpu.p
set_tag(script, "metric::cpu.p")
set_tag(host2, host)
usage_guest = 100.1
After restarting DataKit, new data is collected, and we can get the following modified CPU measurement through DQL:
dql > M::cpu{host='u'}[20s] LIMIT 1
-----------------[ r1.cpu.s1 ]-----------------
core_temperature 54.250000
cpu 'cpu-total'
host 'u'
host2 'u' <--- added tag
script 'metric::cpu.p' <--- added tag
time 2022-05-31 12:49:15 +0800 CST
usage_guest 100.100000 <--- overwrites the specific field value
usage_guest_nice 0
usage_idle 94.251269
usage_iowait 0.012690
usage_irq 0
usage_nice 0
usage_softirq 0.012690
usage_steal 0
usage_system 2.106599
usage_total 5.748731
usage_user 3.616751
---------
Processing Object Data¶
The following Pipeline example is used to show how to discard (filter) data. Taking Nginx processes as an example, the list of Nginx processes on the current host is as follows:
$ ps axuwf | grep nginx
root 1278 0.0 0.0 55288 1496 ? Ss 10:10 0:00 nginx: master process /usr/sbin/nginx -g daemon on; master_process on;
www-data 1279 0.0 0.0 55856 5212 ? S 10:10 0:00 \_ nginx: worker process
www-data 1280 0.0 0.0 55856 5212 ? S 10:10 0:00 \_ nginx: worker process
www-data 1281 0.0 0.0 55856 5212 ? S 10:10 0:00 \_ nginx: worker process
www-data 1282 0.0 0.0 55856 5212 ? S 10:10 0:00 \_ nginx: worker process
www-data 1283 0.0 0.0 55856 5212 ? S 10:10 0:00 \_ nginx: worker process
www-data 1284 0.0 0.0 55856 5212 ? S 10:10 0:00 \_ nginx: worker process
www-data 1286 0.0 0.0 55856 5212 ? S 10:10 0:00 \_ nginx: worker process
www-data 1287 0.0 0.0 55856 5212 ? S 10:10 0:00 \_ nginx: worker process
From DQL, we can know that the measurement fields of a specific process are as follows:
dql > O::host_processes:(host, class, process_name, cmdline, pid) {host='u', pid=1278}
-----------------[ r1.host_processes.s1 ]-----------------
class 'host_processes'
cmdline 'nginx: master process /usr/sbin/nginx -g daemon on; master_process on;'
host 'u'
pid 1278
process_name 'nginx'
time 2022-05-31 14:19:15 +0800 CST
---------
Write the following Pipeline script:
if process_name == "nginx" {
drop() # drop() function marks the data to be discarded and continues running pl after execution
exit() # terminates Pipeline with the exit () function
}
After restarting DataKit, the corresponding Nginx process object will not be collected again (the central object has an expiration policy, and it takes 5 ~ 10min for the original nginx object to automatically expire).