Overview of DataKit Log Collection
For the overall observability of log data, it provides a flexible and changeable way of information combination. For this reason, compared with metrics and Tracing, there are more ways to collect and process logs to adapt to different environments, architectures and collection scenarios of technology stacks.
In general, DataKit has the following log collection schemes:
- Get log from disk file
- Collect container stdout logs
- Push logs to DataKit remotely
- Log collection in Sidecar form
Due to different specific environments, the above collection methods will have some variants, but they are the combination of these methods on the whole. The following categories are introduced one by one.
Get Log from Disk File¶
This is the most primitive log processing method. No matter for developers or traditional log collection schemes, logs are generally written directly to disk files at the beginning. Logs written to disk files have the following characteristics:
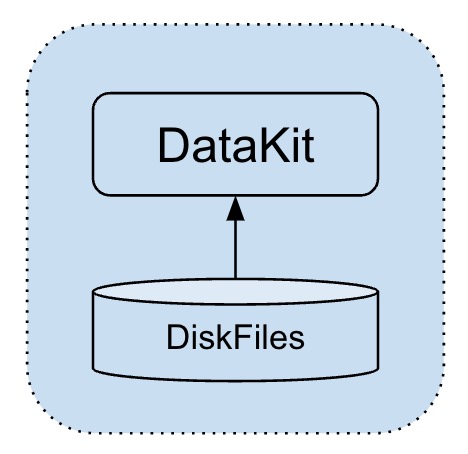
- Sequential writing: The general log framework can guarantee the log in the disk file and keep the sequence of time.
- Automatic slicing: As the disk log files are physically incremented, the general log framework will automatically cut, or through some external resident scripts to achieve log cutting in order to avoid the disk burst by the log.
Based on the above characteristics, it is easy to think that DataKit only needs to keep an eye on the changes of these files (that is, collect the latest updates). Once a log is written, DataKit can collect it, and its deployment is very simple. It only needs to fill in the file path (or wildcard path) to be collected in the conf of the log collector.
It is recommended to use a wildcard path (you can even configure files that do not exist at present but will appear in the future) instead of writing the log path to death, because the log of the application may not appear immediately (for example, the error log of some applications will only appear when the error occurs).
One thing to note about disk file collection is that it only collects log files that have been updated since DataKit started, and if the configured log files (since DataKit started) have not been updated, their historical data will not be collected.
Because of this feature, if the log file is continuously updated and the DataKit is stopped in the middle, the log in this empty window period will not be collected, and some strategies may be taken later to alleviate this problem.
Container stdout Log¶
At present, this collection method is mainly aimed at stdout logs in container environment, which requires applications running in container (or Kubernetes Pod) to output logs to stdout. These stdout logs will actually be dropped on Node, and DataKit can find corresponding log files through corresponding container ID, and then collect them in the way of ordinary disk files.
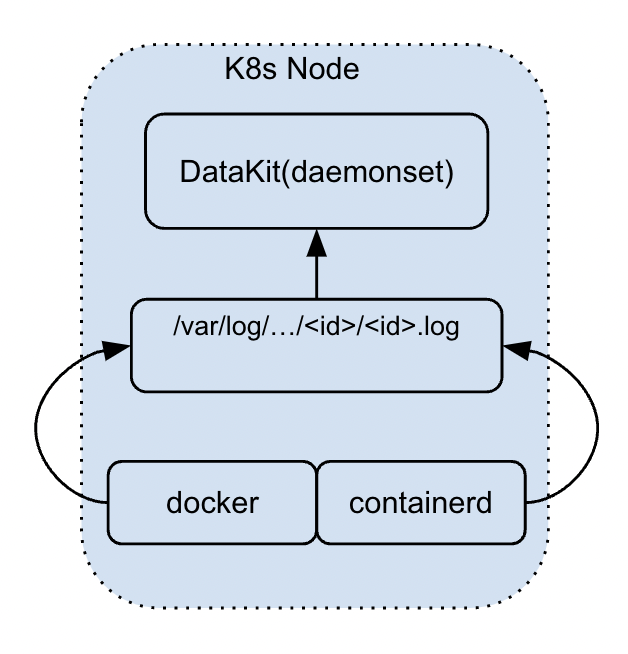
In the existing stdout collection scheme of DataKit (mainly for k8s environment), log collection has the following characteristics:
- Because of the application deployed in the container environment, it is necessary to build the corresponding container image. For DataKit, log collection can be selectively done for some applications based on the image name
- Collect stdout logs at a fixed point by selecting part of the image name (or its wildcard) in ConfigMap's container.conf
- Dyeing tags: By modifying Pod tags through Annotation, DataKit can identify these special Pods and then collect their stdout logs
This is also a defect of this strategy, that is, applications are required to output logs to stdout. In general application development, logs are not directly written to stdout (but mainstream logging frameworks generally support output to stdout), which requires developers to adjust log configuration. However, with the increasing popularity of containerized deployment schemes, this scheme is a feasible way to collect logs.
Push Logs to DataKit Remotely¶
For remote log push, it is mainly
-
Developers push application logs directly to services specified by DataKit, such as Java log4j and Python's native
SocketHandler, which support sending logs to remote services.
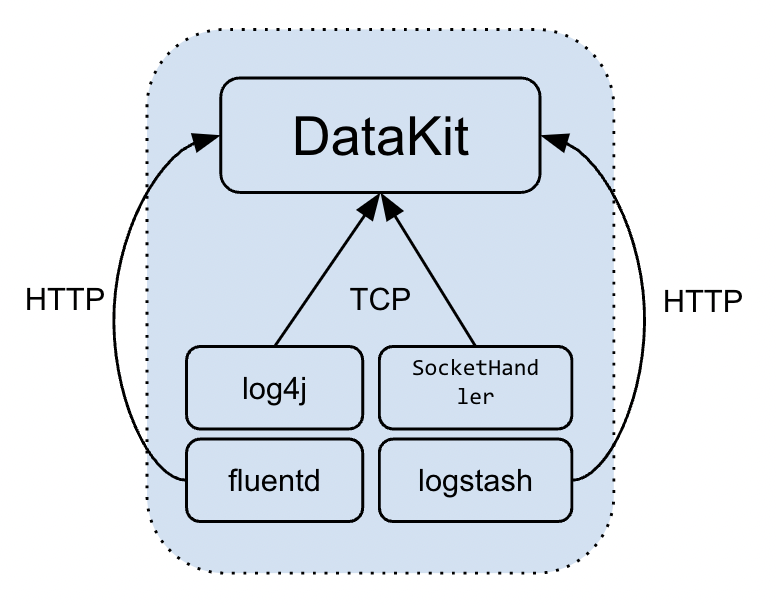
The characteristic of this form is that the log is sent directly to DataKit, and there is no need to drop the disk in the middle. This form of log collection should pay attention to the following points:
- If the log type (
source/service) of TCP type log push is varied, it is necessary to open multiple TCP ports on DataKit.
If you want to open only a single (or a few) TCP ports on the DataKit, you need to identify the characteristics of the cut fields in the subsequent Pipeline processing, and mark their
servicethrough the functionset_tag()(thesourcefield of the log cannot be modified at present, and this function is only supported by versions above 1.2.8)。
- For HTTP log push, developers need to mark the characteristics on the HTTP request parameters, which is convenient for DataKit to do subsequent processing.
Log Collection in the Form of Sidecar¶
In fact, this method of collection is a combination of disk log collection and log remote push. Specifically, a Sidecar application matched with DataKit (i.e. logfwd)) is added to the user's Pod, and its collection method is as follows:
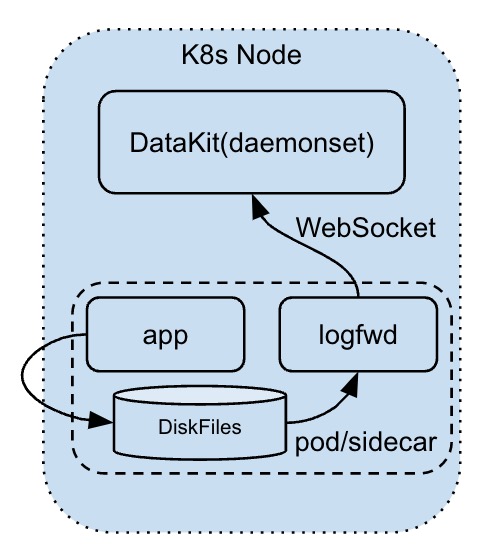
- Get the log in the form of disk file through logfwd
- logfwd then remotely pushes the log (WebSocket) to DataKit
This method can only be used in k8s environment at present, and it has the following characteristics:
- Compared with simple remote log push, it can automatically append some k8s attribute fields of Pod, such as Pod name and k8s namespace information
- Developers can still output the log to disk without modifying the log configuration. In k8s environment, logfwd can even retrieve logs from pod's own storage and push them out without plug-in storage (but logs need to be automatically cut to avoid filling pod storage)
Processing of Logs¶
After the above logs are collected, they all support subsequent Pipeline cutting, but the configuration forms are slightly different:
- Disk Log Collection: Directly configured in logging.conf, where the Pipeline name can be specified.
- Container stdout log collection: Pipeline cannot be configured in container.conf, because this is for log collection of all containers, and it is difficult to process all logs with a common Pipeline. Therefore, the Pipeline configuration of related Pod must be specified by Annotation.
- Remote log collection: For TCP/UDP transport, you can also specify the Pipeline configuration in logging.conf. For HTTP transmission, developers need to configure Pipeline on HTTP request parameters.
- Sidecar log collection: In the configuration of logfwd, configure the Pipeline of the host Pod, which is essentially similar to the container stdout, and is a fixed-point tag for the Pod
Additional Options for Log Collection¶
All log collection, regardless of the collection method used, supports the following collection configuration except Pipeline cutting mentioned above:
- Multi-line cutting: Most logs are single-line logs, but some logs are multi-line, such as call stack logs, and some special application logs (such as MySQL slow logs)
- Encoding: The final logs need to be converted to UTF8 storage, and some Windows logs may need to be coded and decoded
Summary¶
The above describes the current log collection scheme of DataKit as a whole. Generally speaking, these schemes can basically cover the mainstream log data scenarios. With the continuous iteration of software technology, new log data forms will emerge constantly, and DataKit will make corresponding adjustments to adapt to the new scene.